


英伟达刚刚发布全球最大GPU:GTC2018黄仁勋演讲核心内容都在这了
2018年03月28日 07:03:45
来源:机器之心

原标题:英伟达刚刚发布全球最大GPU:GTC2018黄仁勋演讲核心内容都在这了 机器之心报道 参与:
原标题:英伟达刚刚发布全球最大GPU:GTC2018黄仁勋演讲核心内容都在这了
机器之心报道
参与:李泽南、李亚洲
昨天,第九届年度 GPU 技术大会(GTC)在加州圣何塞 McEnery 会议中心正式开幕。在刚刚结束的 Keynote 演讲中,英伟达创始人兼首席执行官黄仁勋宣布了该公司在芯片、AI 平台、自动驾驶上的一系列新动作。在本文中,机器之心对其演讲的核心内容做了梳理。
正如黄仁勋所说的,今天的发布会有关于:「Amazing science, amazing graphics, amazing products and amazing AI.」
核心内容:
新一代服务器级 GPU:搭载英伟达 RTX 技术的 GPU Quadro GV100,以及「世界最大的 GPU」
NVIDIA AI 平台:TensorRT 4 等技术,多种重大改进
推出 DRIVE Constellation 自动驾驶仿真系统
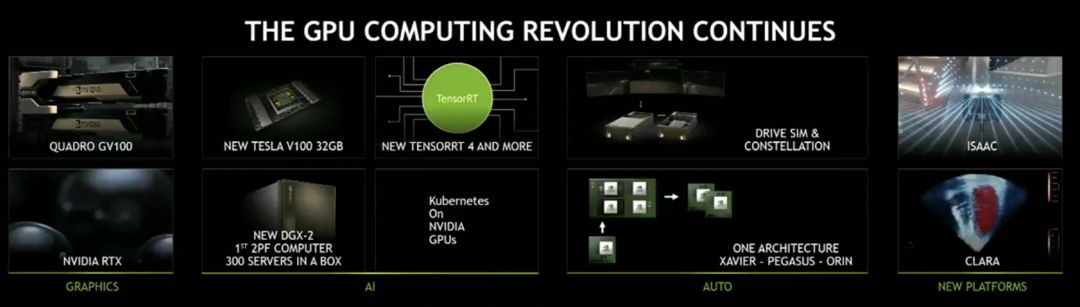
图注:黄仁勋 Keynote 演讲总结
搭载英伟达 RTX 技术的 GPU Quadro GV100

在今天的 GTC 大会 Keynote 中,黄仁勋首先宣布推出搭载 NVIDIA RTX 技术的 Quadro GV100 GPU,首次向数以百万计的艺术家和设计师提供实时光线追踪技术。
黄仁勋表示,结合强大的 Quadro GV100 GPU,NVIDIA RTX 能够在运行专业设计及内容创作类应用程序的同时,实现实时的计算密集型光线追踪。
Quadro GV100 具有 32GB 内存,且可借助 NVIDIA NVLink 2 互联技术,通过并联两块 Quadro GPU 扩展至 64GB,在所有适用于此类应用的平台中其性能最高。
在性能方面,GV100 基于 NVIDIA Volta GPU 架构,可提供每秒 7.4 万亿次浮点运算的双精度性能、每秒 14.8 万亿次浮点运算的单精度性能、以及每秒 118.5 万亿次浮点运算的深度学习性能。NVIDIA RTX 内置的 NVIDIA OptiX AI-denoiser 可实现实时的 AI 去噪,英伟达表示且其性能相当于采用 CPU 时的 100 倍。
NVIDIA AI 平台:多项重大改进

而后,如同往届,黄仁勋对英伟达 AI 平台做了介绍,公布了其中的一系列重要进展,包括全新 Tesla V100 32GB GPU 的 2 倍内存、革命性的 NVSwitch 结构、以及全面的软件堆栈推动性能提升、深度学习工作站 DGX-2 成为首款性能高达每秒 2 千万亿次浮点运算的深度学习系统、发布深度学习引擎 TensorRT 4 等。英伟达表示,相较于六个月前发布的上一代产品 DGX-1,其深度学习工作负载性能实现了 10 倍提升。
在大会上,黄仁勋宣布,新版的 Tesla V100 内存扩容了一倍。「5 年前 AlexNet 在 ImageNet 上展示了突破性的能力,」黄仁勋说道,「它有 8 层,数百个参数。而今天我们能够看到数百层的神经网络,内含数十亿参数,深度学习模型经过五年的发展,体量扩大了 500 倍。」
而这样的计算需求可由「世界上最大的 GPU」DGX-2 进行处理,它是由 16 块 32GB 内存的 Tesla V100 计算卡通过 NVSwitch 进行连接(显卡间的通信速度是 PCI 的 20 倍,每秒 300Gbyte)所组成的,共拥有 2000TFPLOS 的 Tensor Core 算力,售价 39.9 万美元。NVSwitch 是今天黄仁勋宣布的全新的 GPU 互联结构。

DGX-2 是首款能够提供每秒两千万亿次浮点运算能力的单点服务器,具有 300 台服务器的深度学习处理能力,占用 15 个数据中心机架空间,而体积则缩小 60 倍,能效提升 18 倍。

而后,黄仁勋宣布了英伟达在 AI 推理上的一系列动作。黄仁勋表示,基于在数据中心、汽车应 用、以及包括机器人和无人机等嵌入式设备领域中,诸如语音识别、自然语言处理、推荐系统、 以及图像识别等新功能的支持,面向深度学习推理的 GPU 加速正在获得越来越多的关注。
「我们需要超级计算机来帮助自己寻找更高效的能源存储方法,探索地球的内部,预测未来的自然灾害,以及模拟微观世界的变化。」黄仁勋说道。
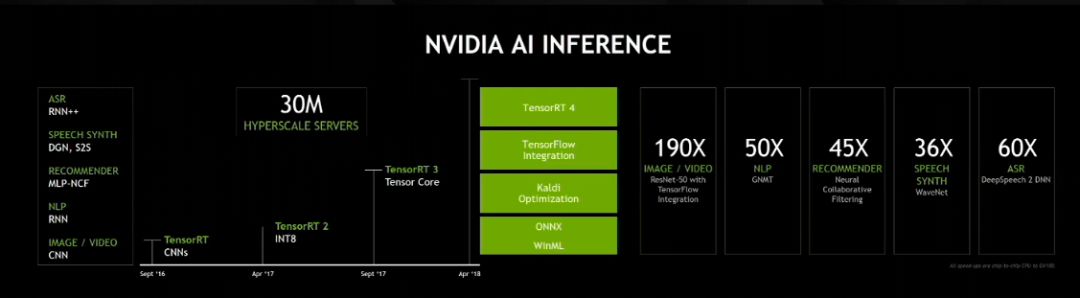
英伟达宣布推出新版 TensorRT 推理软件 TensorRT 4,并将 TensorRT 集成至谷歌的 TensorFlow 框架。
英伟达表示,TensorRT 4 可用于快速优化、验证及部署在超大规模数据中心、嵌入式与汽车 GPU 平台中经过 训练的神经网络。相比 CPU,针对计算机视觉、神经网络机器翻译、自动语音识别、语音合成 与推荐系统等常见应用,该软件最高可将深度学习推理的速度加快 190 倍。而且为了进一步精简开发,英伟达与谷歌的工程师已将 TensorRT 集成至 TensorFlow 1.7,使得在 GPU 上运行深度学习推理应用更加容易。
此外,英伟达还宣布了面向 Kubernetes 的 GPU 加速,以促进企业在多云 GPU 集群上的推理部署。英伟达将针对开源社群强化 GPU 性能,以支持 Kubernetes 生态系统。
推出 DRIVE Constellation 仿真系统
自动驾驶一直是 GTC 大会的重要部分,今天,英伟达展示了一套用于使用照片级真实感模拟,基于云的自动驾驶汽车测试系统。
该系统被称为 NVIDIA DRIVE Constellation,是一种基于两种不同服务器的计算平台。第一台服务器运行 NVIDIA DRIVE Sim 软件,用以模拟自动驾驶汽车的传感器,如摄像头、激光雷达和雷达。第二台服务器搭载了 NVIDIA DRIVE Pegasus AI 汽车计算平台,可运行完整的自动驾驶汽车软件堆栈,并能够处理模拟数据,这些模拟数据如同来自路面行驶汽车上的传感器。

要实现自动驾驶汽车的量产部署,我们需要一种能够在数十亿英里的行驶中进行测试和验证的解决方案,以实现足够安全性和可靠性。黄仁勋介绍说,DRIVE Constellation 可以将视觉计算和数据中心方面的专业知识相结合以实现这一目标。借助虚拟现实技术,测试者可通过对数十亿英里的自定义场景和极端情况进行测试,从而提高算法的稳定性,而花费的时间和成本仅为实际道路测试的一小部分。
此外,英伟达还推出了机器人开发平台 ISSAC 等工具。同时宣布与 ARM 展开合作。两家公司正在合作将开源的 NVIDIA 深度学习加速器 NVDLA 架构集成到 Arm 的 Project Trillium 平台上,以实现机器学习。此次合作将使物联网芯片公司能够轻松地将 AI 集成到自己的设计中,并帮助它们将智能化且价格低廉的新产品带给全球数十亿的消费者。
小结
英伟达 GTC 大会从 2009 年开办以来,越来越受到人们的关注。而随着人工智能的火热,GPU 价值也水涨船高。而本届 GTC 相比于第一届,参会人数增加了近 10 倍,火热程度也超乎以往。但遗憾的是,今天的发布仍然围绕商用计算设备进行,不像国内外众多媒体猜测的那样会发布新一代 Geforce 显卡。或许,众多玩家还要继续等待一段时间。
本文为机器之心报道,转载请联系本公众号获得授权。



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






