

2分钟论文 | 用 谷歌「AI可解释性」 看懂机器学习
2018年03月19日 18:46:18
来源:雷锋网

原标题:2分钟论文 | 用 谷歌「AI可解释性」 看懂机器学习 雷锋网按:这里是,雷锋字幕组编译的T
原标题:2分钟论文 | 用 谷歌「AI可解释性」 看懂机器学习
雷锋网按:这里是,雷锋字幕组编译的Two minutes paper专栏,每周带大家用碎片时间阅览前沿技术,了解AI领域的最新研究成果。
原标题 Building Blocks of AI Interpretability - Two Minute Papers #234
翻译 | 陈晓璇 字幕 | 凡江 整理 | 吴璇 逯玉婧
谁再说神经网络是黑盒,甩出这篇文章,给TA翻个白眼。
上周,谷歌Jeff Dean在推特上转发了一句话“还认为神经网络是黑盒吗?要不再想想 :) ”。
还配上了《纽约时报》一篇名为《谷歌研究人正在搞懂机器学习》的文章。
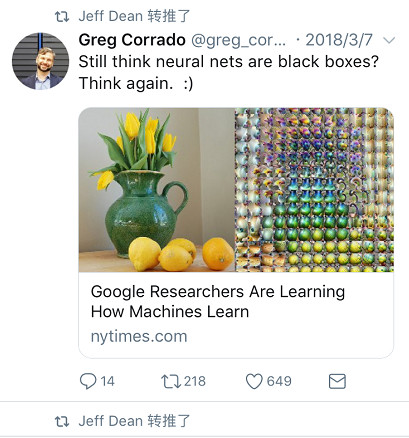
点进这篇文章发现,Jeff Dean意指论文《The Building Blocks of Interpretability》(译名:可解释性的基石)在神经网络可视化方面的新进展。
研究由谷歌大脑研究员Chris Olah带队完成,创建了一套神经网络可视化方法。

左图:可以被神经网络识别,比如说,告诉我们图片里有没有花瓶或柠檬。
右图:神经网络中间层的可视化呈现,能够检测到图片中的每个点。
看起来,神经网络正在检测,像花瓶的模型以及像柠檬的物体。
论文将独立的神经元、分类归属与可视化结合,从而提供一种理解神经元的方法。
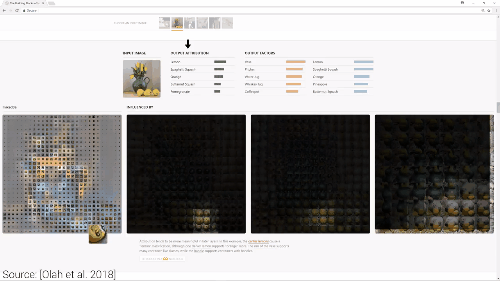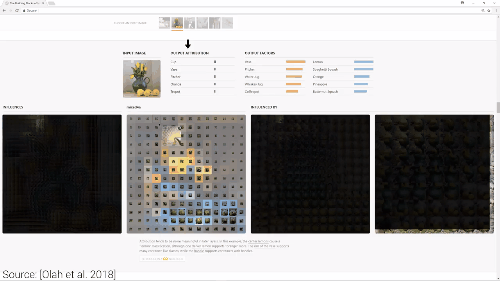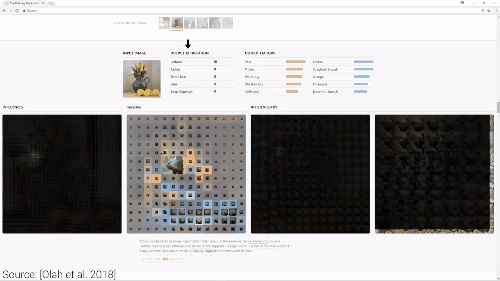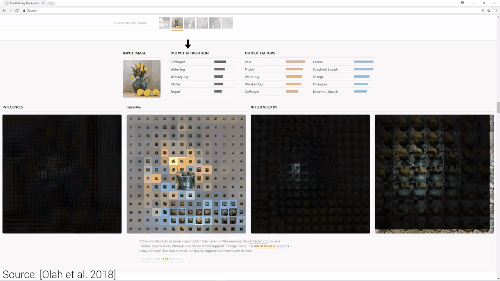
我们通过观察“神经元可以被哪些图像激活”,“神经元在找哪些图像“、“神经元判定这个图像属于哪一类“,可以判断出“神经元的最终决策及贡献值“。
这个过程减少了神经元的总数,并且将神经元分解成一些小的语义组,得出有意义的解释方法。在论文中被称作“因式分解“或者“神经元分组”。通过做这项工作,我们可以得到高度描述性的标签,赋予它们直观的含义。
现在我们把一张图片放到拉布拉多组,神经网络开始观察拉布拉多的耳朵、额头、嘴巴还有毛发的组合。过程可以由一个活动地图来展示,通过观察,我们可以轻松看到神经元群组兴奋点。
我们这里仅仅概括了论文的表面含义,论文中还有许多其他的成果和互动的案例供大家赏析。




- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






