

我用深度学习分析LoL小地图,自制数据集DeepLeague开源(下)
2018年03月01日 17:32:01
来源:雷锋网

原标题:我用深度学习分析LoL小地图,自制数据集DeepLeague开源(下) 本文为雷锋字幕组编译
原标题:我用深度学习分析LoL小地图,自制数据集DeepLeague开源(下)
本文为雷锋字幕组编译的技术博客,原标题 DeepLeague: leveraging computer vision and deep learning on the League of Legends mini map + giving away a dataset of over 100,000 labeled images to further esports analytics research,作者Farza。
翻译 | 于泽平 安妍 整理 | 凡江
嗨!请确定你已经阅读过 我用深度学习分析LoL小地图,自制数据集DeepLeague开源(上),否则你可能会对这一部分感到困惑。
创建数据集
第一部分:神秘的网络套接字
可能许多人都想知道如何创建这个数据集,因为这个数据集实在是太大了。现在我来揭晓答案。我没有手动标记100000张小地图,那样做太疯狂了。每张图片都有10个边界框(假设所有10个英雄都存活),表示这些英雄在哪里以及它们是什么英雄。即使我手动标记每张图片需要5秒钟,也需要超过8000分钟才能完成!
下面让我来讲讲我是怎样创建数据集的,这包含一些聪明的技巧以及Github上面另一位名为remixz的开发者的帮助。这位开发者创建了接下来我将介绍的神秘的网络套接字数据集(我喜欢这样叫它)。
当你在lolesports.com上面观看英雄联盟比赛直播时,实际上有一个神秘的网络套接字,它不断地抛出关于这场比赛直播的数据。我称之为神秘的网络套接字因为有很少人知道这件事,而且它似乎是半隐藏的。套接字产生的数据包含这场比赛中的选手名字、他选择的英雄以及每一时刻的英雄位置和血量。它以这种形式存在是因为这样可以让直播软件在网页上实现统计功能。

你现在可能想知道我如何使用这个数据的了!
我创建了我自己的节点脚本(与remixz所创建的类似),每当神秘的网络套接字开启,脚本监听传入的数据,并将数据保存到一个JSON文件中。我在AWS EC2机器上托管了这个脚本,现在我正在自动保存LCS(英雄联盟冠军联赛)中北美赛区和欧洲赛区的比赛数据!
如果你仍对数据感到好奇,这里是从LCS一场比赛中获取的小片段,可以让你更好地理解它是什么样子的。
这个JSON数据本身其实没什么用。但是请记住,我们这样做的目的是为了创建一个有标签的数据集。这个数据集是带标签的小地图图片,标签表示各个英雄在小地图上的位置。我并不关心JSON数据本身。
我应该补充说明的是,深度联盟只从比赛中识别了55个英雄,因为我只是用LCS的数据。LCS中的选手通常只使用一部分英雄。例如,中单通常会玩狐狸,但是几乎没有人玩提莫!这意味着我没有办法训练一个可以识别提莫的模型。同样,也意味着我有太多狐狸的数据。我需要在我的数据集中获得英雄的平衡。你可以查看代码,看看我如何使用check_champs函数平衡我的数据集的。
现在,我拥有的一切是这些JSON文件,它们对应某场比赛每一时刻的每一个英雄的位置。因此,我所需要做的就是下载JSON文件对应的比赛视频,并将JSON数据与视频匹配。起初我认为这很简单。我以为只需要去YouTube上面找到并下载比赛视频,写一个脚本自动从视频中提取帧,再将它与JSON数据匹配就可以了。
第二部分:理解问题
我犯了一个很大的错误。让我来解释一下。
我无法像处理我在家里录制的英雄联盟视频一样处理LCS的视频。举个例子,如果我需要记录我自己在家从头到尾玩的一局英雄联盟,我只需要运行这段代码:
注意:当我说“帧”时,我的意思是假设游戏中的每一秒与一个图像“帧”相对应。一个60秒的视频将一共有60帧,每一帧都对应一秒。因此,1FPS(每秒传输帧数)!
# first go through every single frame in the VOD.
in_game_timestamp = 0
for frame in vod:
# go in the vod's json data. find the json data associated with
# that specific timestamp.
frame.json_data = vod_json_data[in_game_timestamp]
in_game_timestamp += 1
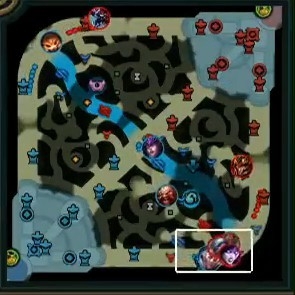
一帧的例子。我保存了完整的视频,只是从中裁剪出了小地图。
这段代码可以在我家里保存的游戏视频上完美运行。假设我在游戏中0:00的时间戳开始录制视频,在22:34时间戳停止。那么如果我想要游戏计时器中每一秒的一帧数据,这是很容易的,因为:
我在家里录制的视频的时间戳与游戏中时间戳是直接对齐的。
哈哈,朋友们,我真希望LCS视频也可以这样简单地处理。
获得LCS比赛视频的唯一方式是通过Twitch上的直播流。这些LCS比赛的Twitch直播流在比赛过程中有许多终端,例如即时回放,选手采访以及暂停。视频的JSON数据对应游戏中的计时器。你明白这为什么会成为一个问题了吗?我的视频计时器与游戏计时器不是对齐的。

溜了溜了
假设发生了这种情况:
LCS比赛在游戏计时器中时间戳为12:21
LCS比赛在游戏计时器中时间戳为12:22
LCS比赛在游戏计时器中时间戳为12:23
流转换为即时回放,并播放最近的一场团战,共17秒。
LCS比赛在游戏计时器中时间戳为12:24
天哪!这真是太可怕了。我完全失去了游戏计时器的轨迹,因为这次中断,游戏时间戳和视频时间戳变得不对齐了!我的程序应该怎样了解如何从视频中提取数据,并将每一帧与我从网络套接字中获得的JSON数据相关联呢?
第三部分:取消谷歌云服务
现在问题已经很清晰了。我用来从视频中提取数据的脚本必须知道游戏中的时间戳的实际情况。只有这样我才能真正确定正在展示的是比赛而不是一些类似即时回放或是其他中断的内容。同样,知道游戏中的时间戳是非常重要的,因为神秘的网络套接字数据集给我们的是实际游戏中的每一秒对应的帧的数据。即使有类似即时重放的事情出现,神秘的网络套接字仍然在向我们发送数据。因此,为了匹配JSON数据中的帧,我们需要知道游戏中的时间戳。
我做的第一个尝试是使用基本的OCR(光学字符识别)识别时间戳。我尝试了很流行的库,但都获得了很糟糕的结果。我猜测的是,奇怪的字体以及总在变化的背景使其变得十分困难。
裁剪出的游戏计时器的样例
最后,我发现了谷歌的Cloud Vision API,其中也有OCR功能。这个API效果很好,几乎不犯错误。但有一个问题。
每使用API处理1000张图片需要花费1.5美元。我首先想到的是将所有时间戳放到同一张图片中,并将它们作为一张图片进行处理。但由于某种原因,我得到了很糟糕的结果。API一直在给我错误的答案。这意味着我有一个选择,我将需要每次发送给API一个小时间戳。我有超过100000帧,这代表我需要付150美元。这其实也不算太差,只是我没有那么多钱,我还在上大学,我还只是个孩子…
但是!我很幸运地找到了这个:
创建一个账户就可以获得免费使用的300美元。无疑,我现在还没有创建3个账户,因此我可以用免费的900美元处理我的视频,并在GCP上做随机测试和脚本。这将违反服务条款,也不尊重公司。
无论如何,凭借这笔免费资金,我编写了一个脚本,可以逐个使用Google Vision API处理视频。这个脚本输出了一个名为time_stamp_data_clean.json的JSON文件,它从游戏中提取了各个帧,并根据每一帧对应的时间从游戏计时器中读取并标记。
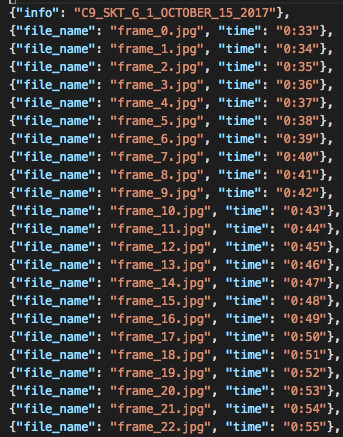
time_stamp_data_clean.json的数据,告诉我们游戏计时器根据特定帧读取的内容。
太厉害了! 这种方法是有效的!
在这一点上,一切都接近完美,数据集几乎准备就绪。 现在是最后一步了。 我们只需要将来自此JSON的数据与来自神秘网络套接字的JSON匹配。 为此,我创建了这个League/blob/master/read_ocr_and_lolesport_data.py" target="_blank" rel="nofollow">脚本。
对于一个巨大的数据集,如果没有合适地处理它,使用起来是很麻烦的。我需要一种好方法去说“这个帧有这些边界框+标签”。我可以只留下一些.jpg文件和一个包含所有标签和坐标信息的.csv文件。它看起来就像这样:
frame_1.jpg, Ahri [120, 145], Shen [11, 678], ...
frame_2.jpg, Ahri [122, 147], Shen [15, 650], ...
frame_3.jpg, Ahri [115, 133], Shen [10, 700], ...
但这是不好的。因为CSV很烦人,JPG更烦人。另外,这意味着我将不得不对所有图片文件重命名,以便使它们与CSV对应。这样肯定不行。必须要有一个更好的办法。确实有。
我将所有数据保存到一个.npz文件中用来代替JPG和CSV。这个.npz文件使用numpy的矩阵保存。Numpy是机器学习的一种语言,所以这很完美。每个图片被保存到numpy数组中,标签也随之保存,就像这样:
[
[[image_as_numpy_array],
[[Ahri, 120, 145, 130, 150],
[Shen, 122, 147, 170, 160],
...
],[[image_as_numpy_array],
[[Ahri, 125, 175, 180, 190],
[Shen, 172, 177, 190, 180],
...
]
...]
现在我们不再需要处理烦人的文件名或者CSV了。所有数据都被保存在同一个文件的许多数组中,并且可以通过索引轻松访问。
最后就是困难的深度学习部分了,获取+处理数据,已经完成了!
选择一个神经网络框架
假如不用模型来训练数据,那数据有什么用?
从最开始我就想用一个专门用于检测物体的现有框架,因为这只不过是个概念验证罢了。我不想花上几周时间来搭一个适合电游的框架。这事儿我还是留给未来的博士生们去做吧:)。
我在上文提到过,之所以选用YOLO框架,是因为它运行速度很快,而且在一度算得上先进。另外,YOLO的作者很了不起,他开放了所有源代码,向开发人员们敞开了大门。但他写YOLO用的是C++语言。我不太爱用C++,因为它大部分数据的代码完全可以用Python和Node.js来做。幸好有人决定创建YAD2K,这样大家就能用Python和Keras来使用YOLO了。说实在的,我选择YOLO还有一个重要原因在于我读懂了它的论文。我深知只有真的读懂了这篇论文,才能弄清楚框架背后的核心代码。其他热门框架的论文我没能读得这么透。YOLO只需看一眼图像就能得出结论,这项能力比R-CNN用的上千个区域提案还要人性化。最重要的是,YOLO的代码对照着论文就很好懂。
至于YOLO是如何运行的,我在此就不赘述了。有很多其他资源对此做出了解释,比如这个(此处有超链接),就比我解释得清楚多了!
对YOLO进行再训练
注意:这部分的技术性较强,如果你有什么不懂的地方,尽管在推特上问我!
YOLO是个特别有深度的神经网络。也有可能它其实没什么深度,是我太容易被打动了。不管怎样,框架是这样的:
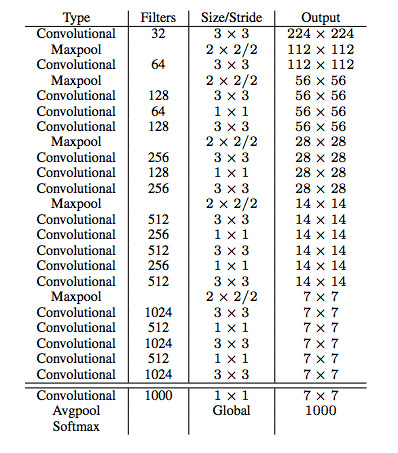
我用的是一台2012年的MacBook Pro。我没法用它来训练YOLO这么个庞大的模型,那估计得花上好几年时间。于是我买了个AWS EC2 GPU实例,因为我想在21世纪结束前完成模型训练。
以下是再训练脚本的运行方式:
我没有完全从头开始训练YOLO。
YAD2K首先得经得住训练前的重量,冻结主体的所有层次,然后运行5次迭代。
接着,YAD2K和整个模型在未冻结的状态下运行30次迭代。
然后,当验证损失开始增加时,YAD2K会尽早停止并退出,这样模型就不会被过度训练了。
所以,起初我还天真地从5个LCS游戏中提取了大约7,500帧的数据,用YOLO运行了一遍,结果数据在2次迭代内过度拟合然后湮灭了。这倒也说得通。这个模型有很多参数,而我没有使用任何形式的数据增强,注定行不通。
说到数据增强,我其实没用在这个项目上。通常来说,在针对现实中的物体训练模型时,数据增强对模型的帮助非常大。例如,一个杯子可以在图像中显示出数千种不同的尺寸。我们无法得到包含每个尺寸的数据集,因此使用数据增强。但就这个迷你地图的例子而言,除了冠军图标和其他一些东西(比如病房)的位置,一切都是恒定不变的。由于我只用了1080p的VOD,迷你地图的大小也是恒定的。如果我想为某位冠军提供更多数据,数据增强会非常有用。所以我可以把迷你地图的框架翻转过来,然后从一个框架中得到两个框架。但与此同时,冠军图标也会被翻转,导致模型混淆。关于这一点我还没测试过,但说不定能行呢!
经历了第一次失败后,我想,“好吧,算了,我用整个数据集试试”。但我的训练脚本在大约20分钟内一直在崩溃,因为我的系统“内存不足”(和RAM一个道理)。
再一次 溜了溜了
这也讲得通,因为我的数据集十分庞大,而训练脚本是把整个数据集都加载到RAM内存里,相当于在电脑上一下子打开十万张图。我本可以租一个内存更大的AWS实例,这样就不会有任何问题;但我又抠又穷。于是我给训练脚本添加了新功能,以便批量训练。这样一来,一次就只加载一部分数据集,而不是一股脑儿全都加载到内存里。得救了!
我用改进后的“批量训练”来运行YOLO,事情总算出现了转机。我前前后后试了有10次。在这个过程中,我把模型运行了好几个小时,才意识到代码有一个巨大的错误,于是我终止训练,从头再来一遍。最后,我修复了错误,损失终于开始降低,而模型这次也没有过度拟合!我花了大约两天时间,让模型运行了完整的训练时长。可惜这下我的钱包瘪了不少,好在最终我还是得到了最后的重量。损失呈现很好的收敛,验证损失也收敛得很好,而且正好处于训练损失之上。
我真想向大家展示一下我那美丽的TensorFlow图形。怪我太蠢,我把训练后的重量保存到笔记本电脑之后,不小心删除了我实例里的所有内容。KMS :(。我可以再花2天时间来训练模型、分析训练,只要先给我买GPU的钱就行:)。
差不多就是这样了!忙了这么久,我终于能取得些可靠的成果来用于我的任务了。写到这儿,我本可以就此收尾,大谈DeepLeague是个多么完美的工具,我是多么了不起。但那不是实话。特此澄清,DeepLeague还远称不上完美,不过我的确很了不起。
尽管DeepLeague大多数情况下都做得很好,但它仍存在一些主要问题。下面我们来看看其中一个。

在上面的输出中,DeepLeague错误地把Cho'Gath标记成了Karma,还给了它1.0的置信度。这很糟。神经网络似乎百分百确定Cho'Gath就是Karma。我在其他地方提到过,我得对数据集加以平衡,否则我就会在掌握某个冠军很多数据的同时,只掌握另一个冠军很少的数据。例如,我有Karma的很多数据,是因为她已经坏了,而大家都在LCS游戏里扮演过她。但是,并没有多少人扮演Cho'Gath!这代表我所掌握的Cho'Gath的数据要比Karma的少得多。其实,还存在一个更深层次的问题使得平衡数据集如此困难。
比方说,在Karma所在的游戏里,我有50,000个帧,整个数据集有100,000帧。对于单独一位冠军而言,这么多数据已经相当多了;而如果在很多Karma身上训练我的网络,可能会使得神经网络对其他冠军的了解变得困难很多。此外,还有可能导致严重的本土化问题。
我知道你们在想什么:“扔掉点儿Karma的数据呗!”我不能为了平衡数据集而扔掉含有Karma的帧,因为这些帧同时也包含了其他9位冠军的数据。也就是说,如果我扔掉那些含有Karma的帧,就会同时减少其他那9位冠军的数据!我试着尽可能去平衡数据集,但由于网络只在地图里的少数几个地方见到过两三次Cho'Gath,而在地图上到处都能见到好多Karma,因此Cho'Gath很有可能被识别成Karma。正如很多深度学习中的问题一样,针对这个问题最简单的解决方案是:更多的数据。这是非常可行的,我们可以从web socket中持续抓取数据!我们还可以试试能“学着”平衡数据集的焦点损失,不过我还没试过。
撇开对于某些冠军的错误分类不看,DeepLeague仍然好得出奇。我真的很想看看这个项目是不是也能启发些别的点子。比如,我们可以在电游里进行动作检测吗?这样一来,当某些冠军在某些时候使用某些法术时,我们就可以识别出来!当Ahri把她的Q扔出去时,她会做出某些动作,而神经网络可以分析这些动作。试想一下,你可以对Faker是如何计算自己的能力、管理自己的法力、在地图上漫游的进行分析。这一切都可以通过计算机视觉实现:)。
非常感谢你阅读本文,我最喜欢你了。如果你有任何疑问,请随时在Twitter上给我留言。先再见啦!

更多文章,关注雷锋网,添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be a AI Volunteer !雷锋网雷锋网雷锋网



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






