


学界 | 无需进行滤波后处理,利用循环推断算法实现歌唱语音分离
2017年11月13日 13:08:25
来源:机器之心

原标题:学界 | 无需进行滤波后处理,利用循环推断算法实现歌唱语音分离 选自arXiv 机器之心编译
原标题:学界 | 无需进行滤波后处理,利用循环推断算法实现歌唱语音分离
近日,来自 Fraunhofer IDMT、Tampere University of Technology 与蒙特利尔大学的 Yoshua Bengio 等人在 arXiv 上提交了一篇论文,提出跳过使用泛化维纳滤波器进行后处理的步骤,转而使用循环推断算法和稀疏变换步骤进行歌唱语音分离,效果优于之前基于深度学习的方法。这篇论文已经提交至 ICASSP 2018。
论文:Monaural Singing Voice Separation with Skip-Filtering Connections and Recurrent Inference of Time-Frequency Mask
论文链接:https://arxiv.org/abs/1711.01437v1
on-line demo 地址:https://js-mim.github.io/mss_pytorch/
GitHub 地址:https://github.com/Js-Mim/mss_pytorch
摘要:基于深度学习的歌唱语音分离依赖于时频掩码(time-frequency masking)。在很多情况中,掩码过程(masking process)不是一个可学习的函数,也无法封装进深度学习优化中。这造成的结果就是,大部分现有方法依赖于使用泛化维纳滤波器(generalized Wiener filtering)进行后处理。我们的研究提出一种方法,在训练过程中学习和优化源依赖掩码(source-dependent mask),无需上述后处理步骤。我们引入了一种循环推断算法、一种稀疏变换步骤用于改善掩码生成流程,以及一个学得的去噪滤波器。实验结果证明,与之前单声道歌唱语音分离的顶尖方法相比,该方法使信号失真比(signal to distortion ratio)提高了 0.49 dB,信号干扰比(signal interference ratio)提高了 0.30 dB。
undefined
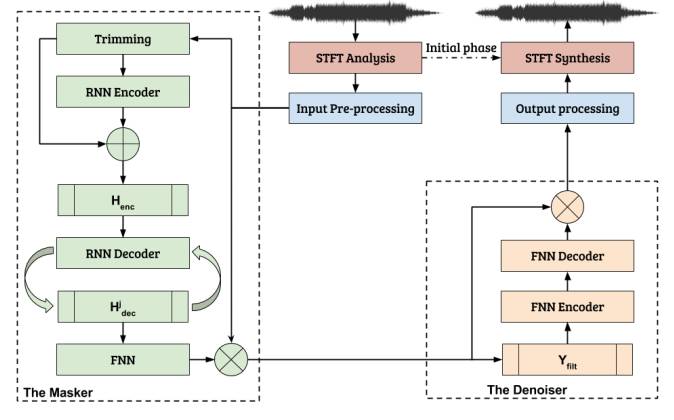
图 1:方法图示。
表 1:几种方法的中值信号失真比(SDR)和信号干扰比(SIR)(单位为 dB)。下划线为我们提出的方法。值越高效果越好。


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






