

从 20 篇ICCV 2017录用论文,看商汤科技四大攻坚领域|ICCV 2017
2017年10月28日 02:16:00
来源:雷锋网

原标题:从 20 篇ICCV 2017录用论文,看商汤科技四大攻坚领域|ICCV 2017 雷锋网
原标题:从 20 篇ICCV 2017录用论文,看商汤科技四大攻坚领域|ICCV 2017
雷锋网 AI 科技评论:本文作者为香港中文大学林达华教授,雷锋网 AI 科技评论获授权转载。
今秋,在以水城而闻名的威尼斯,来自世界各地的三千多位学者荟萃一堂,共赴两年一度的国际计算机视觉大会 (ICCV)。这次大会的一个重要亮点就是中国学者的强势崛起。根据组委会公开的数字,会议 40% 的论文投稿来自中国的研究者。在中国的人工智能浪潮中,商汤科技以及它与港中文的联合实验室无疑是其中最有代表性的力量。在本届 ICCV 大会,商汤科技与香港中大-商汤科技联合实验室共发表了 20 篇论文,其中包括 3 篇 Oral (录取率仅 2.09%) 和 1 篇 Spotlight,领先 Facebook(15 篇)、Google Research(10 篇)等科技巨头。
ICCV 是计算机视觉领域最高水平的国际学术会议,在其中发表的论文的量与质可以衡量一个公司或者研究机构的学术水平,以及其对未来科技发展潮流的把握。从商汤科技的 20 篇论文中,可以看到其在研究上重点发力的四大主线:
跨模态分析:让视觉与自然语言联合起来
在过去几年,随着深度学习的广泛应用,计算机视觉取得了突破性的发展,很多传统任务(比如图像分类,物体检测,场景分割等)的性能大幅度提高。但是在更高的水平上,计算机视觉开始遇到了新的瓶颈。要获得新的技术进步,一个重要的方向就是打破传统视觉任务的藩篱,把视觉理解与自然语言等其它模态的数据结合起来。商汤科技很早就捕捉了这一趋势,并投入重要力量进行开拓,取得了丰硕成果。在这一方向上,有 4 篇论文被 ICCV 2017 录用,包括一篇 Oral。
Towards Diverse and Natural Image Descriptions via a Conditional GAN (Oral).
Bo Dai, Sanja Fidler, Raquel Urtasun, Dahua Lin.

看图说话,也就是根据图像生成描述性标题,是今年来非常活跃的研究领域。现有的方法普遍存在一个问题,就是产生的标题很多是训练集中的表述的简单重复,读起来味同嚼蜡。这一问题的根源在于学习目标过分强调与训练集的相似性。这篇论文提出了一种新型的基于 Conditional GAN 的训练方法,把描述生成模型与评估模型合同训练。这样,评估的标准从「像不像训练集」变成「像不像人说话」,从而驱动生成模型产生更加自然、生动,并具有丰富细节的描述。这一工作为看图说话任务提供了新的思路。在 User Study 中,这种新的方法以 6:4 的胜率战胜了传统的方法。
另外两篇 paper 则从相反的方向思考,力图利用相关文本的信息来帮助提高视觉理解的能力。
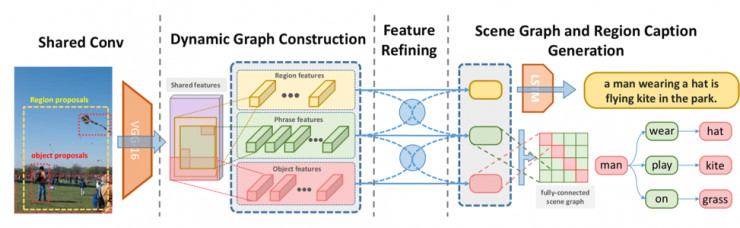
Scene Graph Generation from Objects, Phrases and Caption Regions.
Yikang Li, Bolei Zhou, Wanli Ouyang, Xiaogang Wang, Kun Wang.
Learning to Disambiguate by Asking Discriminative Questions.
Yining Li, Chen Huang, Xiaoou Tang, Chen Change Loy.
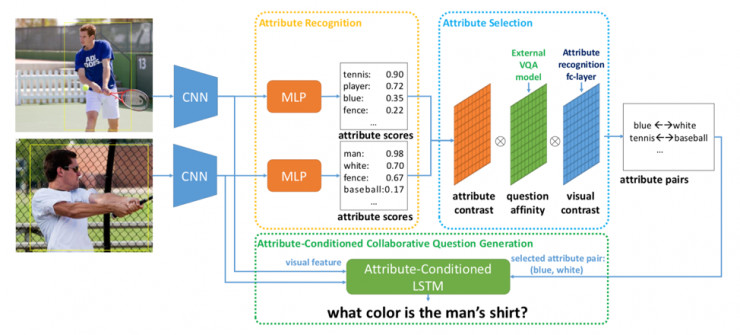
这篇论文探索了一个新的方向,即透过提出有鉴别力的问题来区分不同的视觉实体。比如当你需要区分一只白色的狗和一只黑色的狗的时候,可以提出关于颜色的问题。为了支持这个方向的探索,作者在这项工作中建立了一个新的数据集,里面含有了超过一万组包含成对图像与多个相关问题的样本;并且提出了一种新型的弱监督训练方法,可以在缺乏细致标注的条件下,同时学习到一个具有区分度的问题生成器,以及能提供准确答案的鉴别模型。
Identity-Aware Textual-Visual Matching with Latent Co-attention.
Shuang Li, Tong Xiao, Hongsheng Li, Wei Yang, Xiaogang Wang.
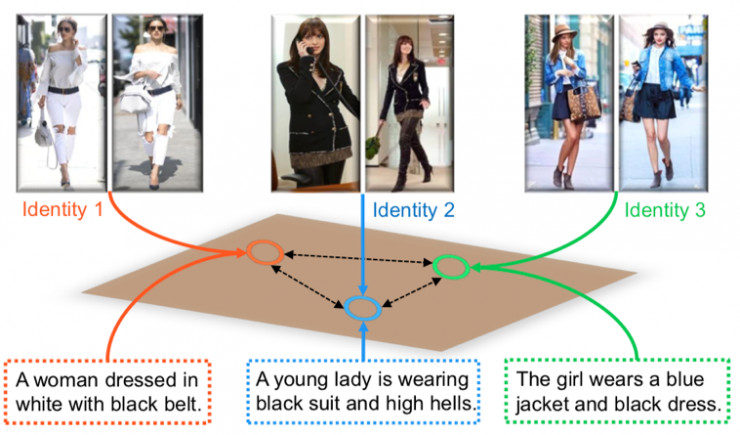
特征匹配是跨模态学习的核心环节。这篇论文提出了一个新的文本与视觉特征匹配的框架。这个框架由两个阶段组成。第一阶段能迅速排除明显错误的配对,并为第二阶段的训练提供效度更高的训练样本。第二阶段通过一个新的关联注意力模型(co-attention model),把文本中的单词关联到图像中的特定区域。在三个公开数据集上(CUHK-PEDES, CUB, Flowers),本文提出的方法都显著超过现行的主流方法。
视频分析:让计算机看懂视频
虽然深度学习在图像分析中取得了巨大的成功,它在视频的理解与分析中的应用还有很长的路要走。相比于图像,视频数据具有更大的数据量以及更丰富的结构,因而也为视觉分析技术提出了更高水平的挑战。商汤科技在数年前就开始了把深度学习用于视频分析与理解的探索,提出了包括 Temporal Segmental Networks (TSN) 在内的多种有很大影响并被广泛应用的视频分析架构,并在 ActivityNet 2016 取得了冠军。在 2017 年,商汤科技以及相关实验室继续把这个方向的探索推向纵深,并在 ICCV 2017 发表了两项重量级的工作,包括一篇 Oral。
RPAN: An End-To-End Recurrent Pose-Attention Network for Action Recognition in Videos. (Oral)
Wenbin Du; Yali Wang; Yu Qiao.
通常的视频分析模型大部分是基于 video-level 的类别进行监督学习的,这种方法的局限是难以学习到复杂的运动结构。这篇论文另辟蹊径,着力于动态人体的建模,并提出了一个新型的可以端对端训练的深度网络架构 Recurrent Pose Attention Network (RPAN)。该架构不仅可以自适应地整合人体运动姿态的特征,还能很好地学习其时空演化结构。这项工作一方面为视频动作理解提供了新的方法,另一方面作为副产品也获得了一个不错的粗粒度姿态估计的模型。
Temporal Action Detection with Structured Segment Networks.
Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, Dahua Lin
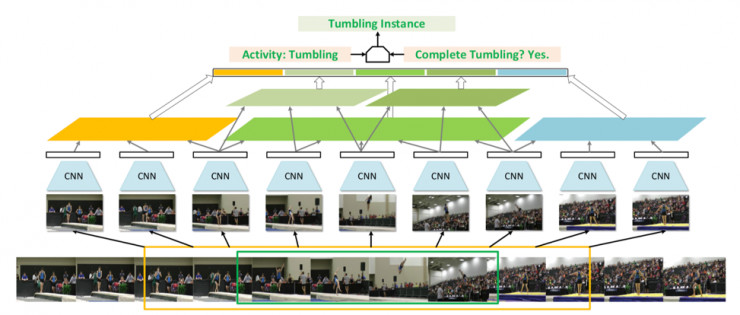
时域上的动作检测是近两年兴起的新型视频分析任务。相比于传统的动作分类,这个任务更具有挑战性,不仅需要判断一个运动或者事件的类型,还需要获得它的准确起止时间。这个任务在实际场景中有很大的潜在价值,比如它可以从长时间的运动视频或者电影中自动定位到相关的精彩片段。这篇论文提出了一种新型的视频动作检测模型,它在 TSN 的基础上引入了三段结构模型以更有效地捕捉运动起始段与终结段的特征。基于这一架构,动作分类器与时间定位器可以端到端联合训练。这个方法在多个大型视频数据集上(包括 THOMOS 和 ActivityNet)取得了比现有方法超过 10 个百分点的提升。
生成对抗网络:让计算机学习创作
最近两年,由于生成对抗网络(Generative Adversarial Networks)的提出,生成模型(generative model)的学习成为一个新兴的研究方向。和传统的鉴别模型(discriminative model)主要关注信息提炼不同,生成模型需要从零开始,或者基于信息量非常有限的给定条件,产生出完整的图像,因此特别具有挑战性。这个研究方向在消费领域具有巨大的应用价值,同时它也可以通过产生训练样本的方式反哺传统领域的研究。商汤科技在这个新兴领域也积极开展研究,取得不少新的成果,并在 ICCV 2017 发表了两项相关工作,包括一篇 Oral。
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks.n (Oral)
Han Zhang, Ttao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas.
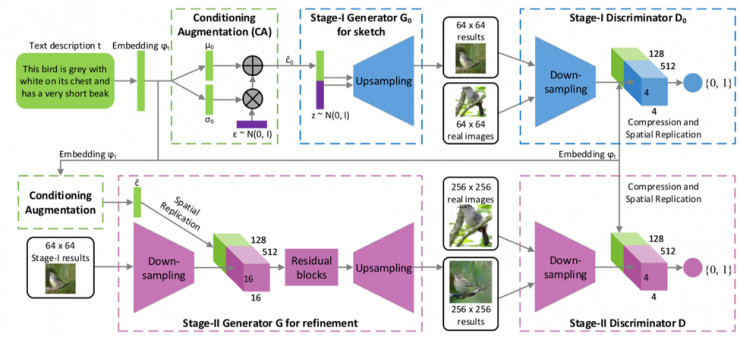
生成高质量的图像是生成模型研究的核心问题。这篇文章提出了一个新型的生成框架,StackGAN,它能够根据简短的文字描述生成解析度为 256 x 256 的高质量图片。生成如此高解析度的照片是一个极具挑战性的问题,此前的生成模型通常只能产生大小为 64 x 64 的图片。本文提出的方法把这个困难的任务分解为两个阶段。在第一阶段,先根据文字描述产生粗粒度的草图,以第一阶段的结果作为输入,第二阶段产生高解析度的图像,并补充丰富的细节。此文还进一步提出了一种新型的条件增强技术,以改进训练过程的稳定性。和现有的生成网络相比,StackGAN 在生成图片的质量的解析度上获得了非常显著的进步。
Be Your Own Prada: Fashion Synthesis with Structural Coherence.
Shizhan Zhu, Sanja Fidler, Raquel Urtasun, Dahua Lin, Chen Change Loy
这篇文章探索了一个极具应用价值的方向,把生成模型引入时尚领域:提出一种崭新的方法产生换装照片。具体而言,给定一个人的照片,以及对换装的描述,此文提出的方法可以根据对换装的描述,比如「黑色的短袖长裙」,产生换装后的照片。和一般的生成任务相比,换装任务更具挑战性,换装照不仅需要符合文字描述,而且需要和原照片中人体的姿态相吻合。此文提出一个两阶段的框架解决这个问题:第一阶段产生一个和人体姿态吻合的分区图,第二阶段以此为基础生成具有精细细节的服装图像。
除了在新兴方向上积极开拓,商汤科技在一些重要的核心领域,包括人脸检测、物体检测、人体姿态估计、实际场景中的身份再识别等,也持续投入,精益求精,在本届 ICCV 发表多篇相关论文。
商汤科技 ICCV 2017 论文列表:
1. 「StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks」. Han Zhang, Ttao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas.
2. 「Scene Graph Generation from Objects, Phrases and Caption Regions」. Yikang Li, Bolei Zhou, Wanli Ouyang, Xiaogang Wang, Kun Wang.
3. 「Online Multi-Object Tracking Using Single Object Tracker with Spatial and Temporal Attention」. Qi Chu, Wanli Ouyang, Hongsheng Li, Xiaogang Wang, Nenghai Yu.
4. 「Learning Feature Pyramids for Human Pose Estimation」. Wei Yang, Wanli Ouyang, Shuang Li, Xiaogang Wang.
5. 「Learning Chained Deep Features and Classifiers for Cascade in Object Detection」. Wanli Ouyang, Xiaogang Wang, Kun Wang, Xin Zhu.
6. 「Identity-Aware Textual-Visual Matching with Latent Co-attention」. Shuang Li, Tong Xiao, Hongsheng Li, Wei Yang, Xiaogang Wang.
7. 「Towards Diverse and Natural Image Descriptions via a Conditional GAN」. Bo Dai, Sanja Fidler, Raquel Urtasun, Dahua Lin.
8. 「Temporal Action Detection with Structured Segment Networks」. Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, Dahua Lin.
9. 「Learning to Disambiguate by Asking Discriminative Questions」. Yining Li, Chen Huang, Xiaoou Tang, Chen Change Loy.
10. 「Be Your Own Prada: Fashion Synthesis with Structural Coherence」. Shizhan Zhu, Sanja Fidler, Raquel Urtasun, Dahua Lin, Chen Change Loy.
11. 「Recurrent Scale Approximation for Object Detection in CNN」. Yu LIU, Hongyang Li, Junjie Yan, Xiaogang Wang, Xiaoou Tang.
12. 「Orientation Invariant Feature Embedding and Spatial Temporal Re-ranking for Vehicle Re-identification」. Zhongdao Wang, Luming Tang, Xihui Liu, Zhuliang Yao, Shuai Yi, Jing Shao, Junjie Yan, Shengjin Wang, Hongsheng Li, Xiaogang Wang.
13. 「Multi-label Image Recognition by Recurrently Discovering Attentional Regions」. Zhouxia Wang, Tianshui Chen, Guanbin Li, Ruijia Xu, Liang Lin.
14. 「HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis」. Xihui Liu, Haiyu Zhao, Maoqing Tian, Lu Sheng, Jing Shao, Shuai Yi, Junjie Yan, Xiaogang Wang.
15. 「Learning Deep Neural Networks for Vehicle Re-ID with Visual-spatio-temporal Path Proposals」. Yantao Shen, Tong Xiao, Hongsheng Li, Shuai Yi, Xiaogang Wang.
16. 「Deep Dual Learning for Semantic Image Segmentation」. Ping Luo, Guangrun Wang, Liang Lin, Xiaogang Wang.
17. 「Detecting Faces Using Inside Cascaded Contextual CNN」. Kaipeng Zhan, Zhanpeng Zhang, Hao Wang, Zhifeng Li, Yu Qiao, Wei Liu.
18. 「Single Shot Text Detector With Regional Attention」. Pan He; Weilin Huang, Tong He, Qile Zhu, Yu Qiao, Xiaolin Li.
19. 「RPAN: An End-To-End Recurrent Pose-Attention Network for Action Recognition in Videos」. Wenbin Du, Yali Wang, Yu Qiao.
20. 「Range Loss for Deep Face Recognition With Long-Tailed Training Data」. Xiao Zhang, Zhiyuan Fang, Yandong Wen, Zhifeng Li, Yu Qiao.
更多资讯,敬请关注雷锋网AI科技评论。


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






