


学界 | 伯克利提出强化学习新方法,可让智能体同时学习多个解决方案
2017年10月14日 23:34:06
来源:机器之心

原标题:学界 | 伯克利提出强化学习新方法,可让智能体同时学习多个解决方案 选自BAIR Blog
原标题:学界 | 伯克利提出强化学习新方法,可让智能体同时学习多个解决方案
选自BAIR Blog
作者:Haoran Tang、Tuomas Haarnoja
机器之心编译
参与:Panda
强化学习可以帮助智能体自动找到任务的解决策略,但常规的强化学习方法可能对环境变化不够稳健。近日,伯克利人工智能研究所(BAIR)发表了一篇博客,解读了他们与 OpenAI 和国际计算机科学研究所(ICSI)在这方面的一项共同研究进展《Reinforcement Learning with Deep Energy-Based Policies》。该论文也是 ICML 2017 所接收的论文之一。另外,该研究相关的代码和演示视频也已公开。
论文:https://arxiv.org/abs/1702.08165
代码:https://github.com/haarnoja/softqlearning
视频:https://sites.google.com/view/softqlearning/home
深度强化学习(deep RL)已经在很多任务上取得了成功,比如基于原始像素玩视频游戏(Mnih et al., 2015)、下围棋(Silver et al., 2016)和模拟机器人运动(比如 Schulman et al., 2015)。标准深度强化学习的目标是掌握给定任务的一种解决方法,通常会选择第一种看起来有效的方法。因此,训练会受到环境中的随机性、策略的初始化和算法实现的很大影响。这个现象如图 1 所示,其中展示了两个训练策略,其目标是优化一个鼓励前进运动的奖励函数:尽管这两个策略都收敛到了一个高性能的步态,但这两个步态具有显著的差异。

图 1:训练得到的模拟步行机器人,来自 John Schulman and Patrick Coady(OpenAI Gym),参阅:https://gym.openai.com/envs/Walker2d-v1/
为什么我们可能并不想只找到一个解决方案?只知道一种行动方案会让智能体难以应对环境的变化,而真实世界的环境常有改变。举个例子,如图 2 所示,假设一个机器人需要在一个简单迷宫中到达它的目标(蓝色十字区域)。在训练阶段(图 2a),有两条路径通向目标。因为上面那条通道的长度稍短一些,所以该智能体很可能会确定选择上面的通道。但是,如果我们对该环境进行一点修改,在上面那条通道上增加一道墙(图 2b),那么该智能体已经找到的解决方案将会变得不可用。因为该智能体在训练阶段完全关注的是上面的通道,所以它几乎没有关于下面的通道的任何知识。因此,采用图 2b 中的新解决方案还需要该智能体再次从头开始学习整个任务。
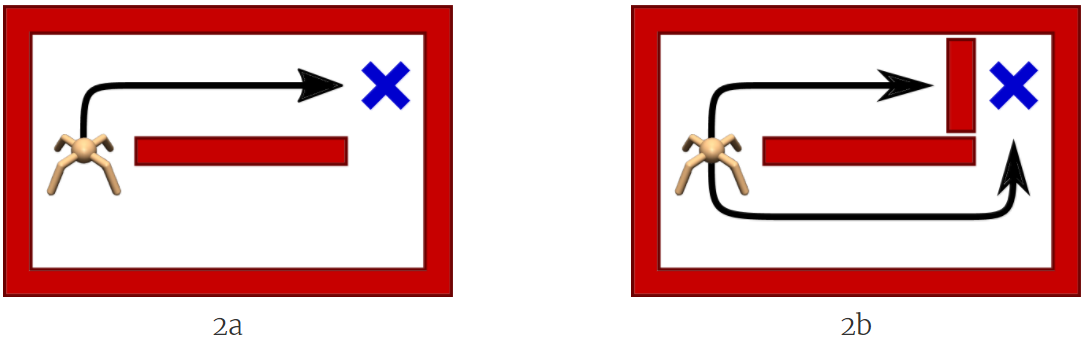
图 2:走迷宫的机器人
最大熵策略及其能量形式
让我们首先了解一下强化学习(RL),即智能体通过迭代式地观察当前状态(s)、采取动作(a)并接收奖励(r)来与环境进行交互。它会采用一种(随机)策略(π)来选择动作,并找到其中的最佳策略,从而使得在长度 T 的 episode 过程中累积的奖励最大化。
最大熵策略及其能量形式
让我们首先了解一下强化学习(RL),即智能体通过迭代式地观察当前状态(s)、采取动作(a)并接收奖励(r)来与环境进行交互。它会采用一种(随机)策略(π)来选择动作,并找到其中的最佳策略,从而使得在长度 T 的 episode 过程中累积的奖励最大化。
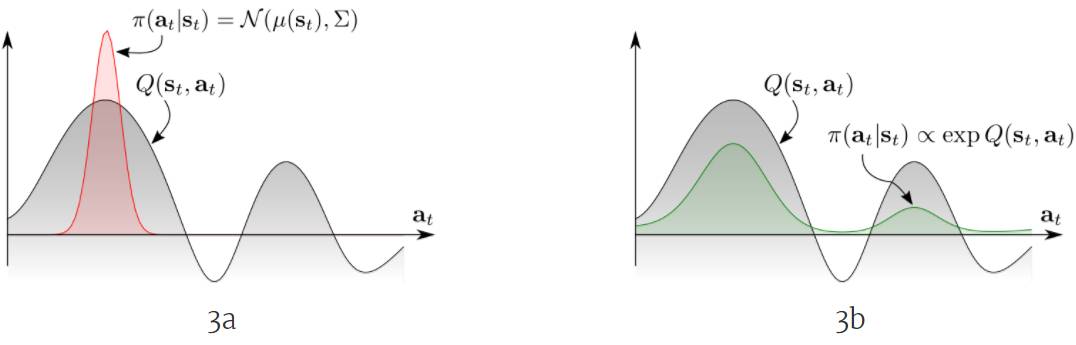
图 3:多模态 Q 函数
从高层面来看,显然应该让智能体探索所有有希望的状态,同时按照有希望的程度做优先级排序。为了用数学形式化这一思想,一种方式是直接以指数 Q 值的形式定义策略(图 3b,绿色分布):
其密度具有玻尔兹曼分布的形式,其中 Q 函数用作负能量(negative energy),其会为所有动作分配一个非零似然。因此,该智能体就能知晓所有可以解决该任务的行为,这能有助于该智能体适应条件变化,使得该智能体在某些解决方案不可行时也能够解决该任务。事实上,我们可以表明:通过能量形式定义的策略是最大熵强化学习目标函数
的一个最优解;这个函数只是将传统的强化学习目标与策略的熵加到了一起(Ziebart 2010)。
学习这种最大熵模型的思想源自统计建模,其目标是在满足观察到的统计结果的同时找到具有最高熵的概率分布。比如说,如果该分布在欧几里德空间上且观察的统计结果是均值和协方差,那么其最大熵分布就是一个带有对应均值和协方差的高斯分布。在实践中,我们更喜欢最大熵模型,因为它们对未知的假设最少,同时也能匹配观察到的信息。
之前一些研究工作已经在强化学习和最优控制方面使用了最大熵原理。Ziebart (2008) 使用了最大熵原理来解决逆向强化学习(inverse reinforcement learning)的模糊性问题,即多个奖励函数都能解释所观察到的表现。还有一些成果(Todorov 2008; Toussaint, 2009)通过最大熵方法研究了推理和控制之间的联系。Todorov (2007, 2009) 还表明最大熵原理可用于使马尔可夫决策过程(MDP)线性可解。Fox et al. (2016) 则利用该原理将先验知识整合进了强化学习策略中。
软贝尔曼方程和软 Q 学习
我们可以通过使用软贝尔曼方程(soft Bellman equation)获得最大熵目标函数的最优解。软贝尔曼方程如下所示:
其中
软贝尔曼方程可以用于得到增加了熵的奖励函数的最优 Q 函数(比如 Ziebart 2010)。注意其与传统贝尔曼方程的相似性——传统贝尔曼方程是取动作上 Q 函数的真正最大值(原文为 hard max),而不是求 softmax。和求真正最大值的版本一样,软贝尔曼方程也是一种收缩,这使得我们可以在平面的状态和动作空间中使用动态规划或无模型 TD(时间差分)学习来求解其 Q 函数(比如 Ziebart, 2008; Rawlik, 2012; Fox, 2016)。
但是,在连续域中还有两大主要挑战。第一,无法做到准确的动态规划,因为软贝尔曼方程需要在每个状态和动作上都有效,所以其 softmax 涉及到在整个动作空间上的整合。第二,其最优策略是由一个难得实现的基于能量的分布定义的,该分布难以被采样。为了解决第一个挑战,我们可以使用表达神经网络函数近似器(expressive neural network function approximator),这可以在采样的状态和动作上使用随机梯度下降训练得到,然后就可以有效地泛化到新的状态-动作元组上。为了解决第二个挑战,我们可以使用马尔可夫链蒙特卡罗(MCMC)等近似推理(approximate inference)技术,之前已有研究为基于能量的策略探索过这种方法(Heess, 2012)。为了加速推理,我们使用 amortized Stein 变分梯度下降(Wang and Liu, 2016)训练了一个推理网络来生成近似样本。所得到的算法称为软 Q 学习(soft Q-learning),这是深度 Q 学习和 amortized Stein 变分梯度下降的结合。
应用于强化学习
现在我们可以通过软 Q 学习来学习最大熵策略了,我们可能会想:这种方法有什么实际用途吗?在下面的章节中,我们会用实验说明软 Q 学习能够实现更好的探索、能实现相似任务之间的策略迁移、能根据已有策略轻松组合出新策略以及还能通过训练阶段广泛的探索提升稳健性。
更好的探索
软 Q 学习(SQL)为我们提供了一种隐含的探索策略,其方法是为每一个动作分配一个非零概率,该概率会受到对其值的当前信心的影响,从而自然地将探索和开发(exploitation)结合到了一起。为了说明,让我们假设有一个类似于前面所讨论的那种双通道迷宫(图 4)。该任务的目标是寻找一种到达目标状态(用蓝色方框表示)的方法。假设其奖励反比于其与目标的距离。因为该迷宫几乎是对称的,所以这样的奖励会得到一个双模态目标,但其中只有一个模态对应于该任务的真正解。因此,在训练阶段两个通道都要探索,这是很关键的,从而才能发现这两个通道哪个才真正最好。单模态策略只有足够幸运时才能解决这个任务,即一开始就选择了下面的通道。而多模态软 Q 学习策略总是可以解决该任务,它会随机地选择这两个通道,直到其智能体到达目标(图 4)。

图 4:使用软 Q 学习训练的策略可以在训练过程中探索两个通道
微调最大熵策略
强化学习的标准做法是为每个新任务都从头开始训练一个智能体。因为智能体丢弃了从之前任务学习到的知识,所以这个过程可能会很慢。而我们的智能体可以迁移之前在相似任务上学习到的技能,让其可以更快地学习新任务。迁移技能的方法之一是为通用任务预训练一些策略,然后使用这些策略作为模板或初始配置来训练更加具体的任务。比如,行走的技能包含在迷宫中导航的技能,因此可以将行走技能用作学习导航技能的有效初始化。为了阐述这一思想,我们通过奖励高速行走的智能体(不管行走方向)而训练了一个最大熵策略。结果得到的策略学会了行走,但由于最大熵目标,它不会选择任何一个特定方向(图 5a)。接下来,我们使用一系列导航技能对该行走技能进行了特化,比如图 5b。在新的任务中,智能体只需要选择哪种行为可以让自己更接近目标即可,这可比从头开始学习同样的技能要容易多了。传统的策略在为通用任务进行训练时会收敛到一个特定的行为。比如,它可能只能学会向一个方向走,因此就无法将这种行走技能直接迁移到迷宫环境中,因为迷宫环境需要在多个方向上进行运动。

图 5:最大熵预训练允许智能体在新环境中更快速地学习。为其它目标任务微调过的同一预训练策略的视频可访问:https://www.youtube.com/watch?v=7Nm1N6sUoVs
组合性
类似于从通用到特定的迁移过程,我们也可以通过交叉不同的技能将已有策略的新技能组合到一起——甚至无需任何微调。这一思想很简单:取两个软策略,其中每个策略都对应于一个不同的行为集合,然后通过将它们的 Q 函数相加而将它们组合起来。事实上,通过直接将组分任务的奖励函数相加可以得到组合任务(应在误差范围内),而我们组合得到的策略对该组合任务而言可能就是近似最优的。比如有如下图所示的平面操作器。左边两个智能体的训练目标是将圆柱体移动到红色条带所示的目标位置。注意这两个任务的解空间的重叠方式:通过将圆柱体移动到两个条带的交汇处,可以同时解决这两个任务。实际上,右边的策略是直接将两个 Q 函数相加所得到的,它成功将圆柱体移动到了交汇处,所以无需再为该组合任务明确训练一个策略。传统策略没有这样的组合性,因为它们只能表征特定的非组合的解。
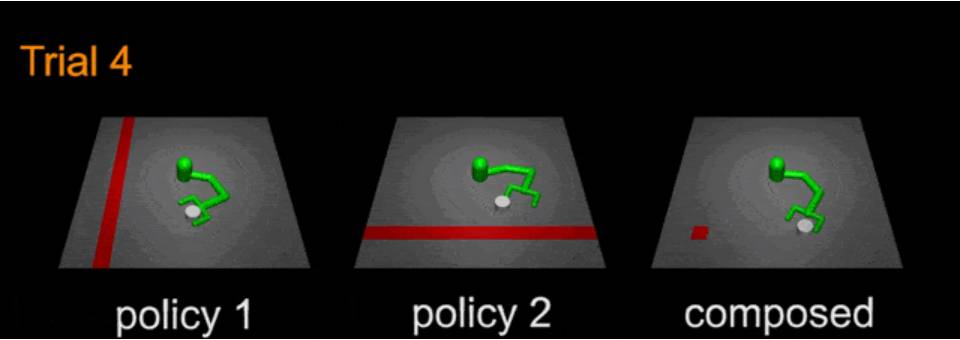
图 6:将两个技能组合成一个新技能
稳健性
因为最大熵方法会鼓励智能体尝试所有可能的解决方案,所以智能体会学习探索大部分状态空间。因此它们可以学会如何在各种不同情况下采取行动,而且对环境中的扰动也更为稳健。为了说明这一点,我们训练了一个 Sawyer 机器人来堆叠乐高积木——目标是让该执行器做出一个特定的最终姿势。图 7 给出了训练过程的一些快照。

图 7:使用软 Q 学习训练堆叠乐高积木
该机器人在 30 分钟后实现了第一次成功;一个小时后,它就总是可以堆叠好积木了;两个小时后,策略完全收敛。收敛得到的策略对干扰也是稳健的,如下所示,其中该机器臂受到了很大的干扰,出现了非常不同于其正常执行过程中会遇到的情况,但它每次都能成功恢复。

图 8:训练后的策略对干扰是稳健的
相关研究
最近有一些论文在多步骤转移学习方面研究了软最优性(soft optimality)(Nachum et al., 2017)及其与策略梯度方法的联系(Schulman et al., 2017)。O'Donoghue et al. (2016) 谈论了一个相关的概念,他们也对熵正则化(entropy regularization)和玻尔兹曼探索(Boltzmann exploration)进行了思考。熵正则化的这个版本仅考虑了当前状态的熵,没有考虑未来状态的熵。
就我们所知,之前仅有少数几个研究直接在真实世界机器人上演示了成功的无模型强化学习。Gu et al. (2016) 表明 NAF(normalized advantage function)可以学会开门任务,他们使用了 2.5 小时两个机器人并行的经历。Rusu et al. (2016) 使用强化学习训练了一个机器臂来接触一个红色方块,同时使用了模拟环境中的预训练。Večerı́k et al. (2017) 表明,如果使用演示进行初始化,Sawyer 机器人仅需大约 30 分钟经验就能学会执行插入销子这样的任务。我们上面给出的软 Q 学习结果也值得一提,其中仅使用了一个机器人进行训练,而且没有使用任何模拟或演示。
参考文献
同时研究的相关论文
Schulman, J., Abbeel, P. and Chen, X. Equivalence Between Policy Gradients and Soft Q-Learning. arXiv preprint arXiv:1704.06440, 2017.
Nachum, O., Norouzi, M., Xu, K. and Schuurmans, D. Bridging the Gap Between Value and Policy Based Reinforcement Learning. NIPS 2017.
利用了最大熵原理的论文
Kappen, H. J. Path integrals and symmetry breaking for optimal control theory. Journal of Statistical Mechanics: Theory And Experiment, 2005(11): P11011, 2005.
Todorov, E. Linearly-solvable Markov decision problems. In Advances in Neural Information Processing Systems, pp. 1369–1376. MIT Press, 2007.
Todorov, E. General duality between optimal control and estimation. In IEEE Conf. on Decision and Control, pp. 4286–4292. IEEE, 2008.
Todorov, E. (2009). Compositionality of optimal control laws. In Advances in Neural Information Processing Systems (pp. 1856-1864).
Ziebart, B. D., Maas, A. L., Bagnell, J. A., and Dey, A. K. Maximum entropy inverse reinforcement learning. In AAAI Conference on Artificial Intelligence, pp. 1433–1438, 2008.
Toussaint, M. Robot trajectory optimization using approximate inference. In Int. Conf. on Machine Learning, pp. 1049–1056. ACM, 2009.
Ziebart, B. D. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. PhD thesis, 2010.
Rawlik, K., Toussaint, M., and Vijayakumar, S. On stochastic optimal control and reinforcement learning by approximate inference. Proceedings of Robotics: Science and Systems VIII, 2012.
Fox, R., Pakman, A., and Tishby, N. Taming the noise in reinforcement learning via soft updates. In Conf. on Uncertainty in Artificial Intelligence, 2016.
真实世界的无模型强化学习
Gu, S., Lillicrap, T., Sutskever, I., and Levine, S. Continuous deep Q-learning with model-based acceleration. In Int. Conf. on Machine Learning, pp. 2829–2838, 2016.
M. Večerı́k, T. Hester, J. Scholz, F. Wang, O. Pietquin, B. Piot, N. Heess, T. Rothörl, T. Lampe, and M. Riedmiller,「Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards,」arXiv preprint arXiv:1707.08817, 2017.
其它参考
Heess, N., Silver, D., and Teh, Y.W. Actor-critic reinforcement learning with energy-based policies. In Workshop on Reinforcement Learning, pp. 43. Citeseer, 2012.
Jaynes, E.T. Prior probabilities. IEEE Transactions on systems science and cybernetics, 4(3), pp.227-241, 1968.
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. ICLR 2016.
Liu, Q. and Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. In Advances In Neural Information Processing Systems, pp. 2370–2378, 2016.
Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A, Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., et al. Human-level control through deep reinforcement learning. Nature, 518 (7540):529–533, 2015.
Mnih, V., Badia, A.P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D. and Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning (pp. 1928-1937), 2016.
O’Donoghue, B., Munos, R., Kavukcuoglu, K., and Mnih, V. PGQ: Combining policy gradient and Q-learning. *arXiv preprint arXiv:1611.01626*, 2016.
Rusu, A. A., Vecerik, M., Rothörl, T., Heess, N., Pascanu, R. and Hadsell, R., Sim-to-real robot learning from pixels with progressive nets. arXiv preprint arXiv:1610.04286, 2016.
Schulman, J., Levine, S., Abbeel, P., Jordan, M., & Moritz, P. Trust region policy optimization. Proceedings of the 32nd International Conference on Machine Learning (ICML-15), 2015.
Silver, D., Huang, A., Maddison, C.J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M. and Dieleman, S. Mastering the game of Go with deep neural networks and tree search. *Nature*, 529(7587), 484-489, 2016.
Sutton, R. S. and Barto, A. G. *Reinforcement learning: An introduction*, volume 1. MIT press Cambridge, 1998.
Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W. and Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. arXiv preprint arXiv:1703.06907, 2017.
Wang, D., and Liu, Q. Learning to draw samples: With application to amortized MLE for generative adversarial learning. arXiv preprint arXiv:1611.01722, 2016.



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






