


专栏 | 贝叶斯学习与未来人工智能
2017年09月19日 12:41:38
来源:机器之心

原标题:专栏 | 贝叶斯学习与未来人工智能 机器之心专栏 作者:邓仰东 发射资本 人人都喜欢美剧《生
原标题:专栏 | 贝叶斯学习与未来人工智能
机器之心专栏
作者:邓仰东 发射资本
人人都喜欢美剧《生活大爆炸》。Sheldon 和朋友们的生活看似单调,但是自有其独特的精彩。捧腹之余,理工科出身的观众不免也想看看 Sheldon 到底在做怎样的研究,特别是和我们自己相关的工作。果然,在第四季第 2 集中我们看到了下图中的公式(用红框标出)——贝叶斯定理!该定理素以其简单而优雅的形式、深刻而隽永的意义而闻名,在今天的机器学习大潮中,贝叶斯定理仍会扮演重要的角色,而且其作用将日益凸显。

1. 贝叶斯定理
贝叶斯定理是英国数学家贝叶斯提出的,当时的目标是要解决所谓「逆概率」问题。在前贝叶斯时代处理概率问题的时候,总是先取一定假设(比如抛硬币时,每次出现正反面的概率相同),然后在假设下讨论一定事件的概率(比如说连续出现 10 次正面的概率)。「逆概率」则反过来考虑问题,比如说,如果连续出现 10 次正面,我们想知道一次抛硬币时出现正反面的概率。贝叶斯定理的相关论文在贝叶斯去世后才发表,此后法国大数学家拉普拉斯对这一理论进行了深入的研究,使之成为我们今天使用的形式,如下图所示。
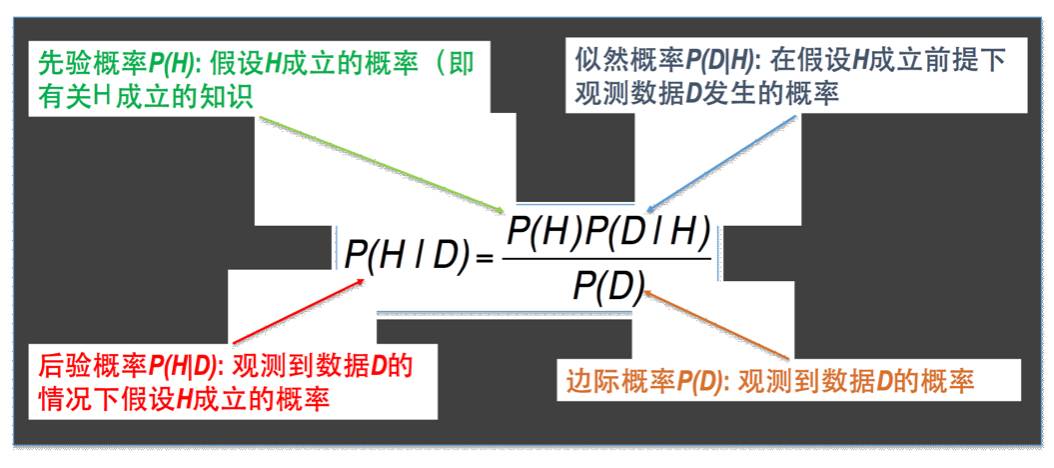
贝叶斯定理的公式并不复杂。上图中 P 表示概率,取值在 0 和 1 之间,即相应事件发生的几率。等式中 D 表示数据,也就是说,我们在某一活动中观测到数据 D。H 代表导致数据 D 发生的假设,或者可以直观的理解为原因。多个不同假设可以产生同样的数据 D,比如我们早晨离开家时发现当前并没有下雨但是道路是湿的,那么这可能是由于凌晨时下雨造成的,也可能是因为给草坪浇水的结果,当然也许是由于是自来水管道泄露,甚至外星人故意把路面弄湿和我们开个玩笑也是一种可能性。P(Y|X) 符号中的竖线表示条件概率,就是如果 X 成立下 Y 发生的概率。贝叶斯定理公式的等号左边是该定理要计算的目标,即后验概率,指在观测到数据 D 时假设 H 成立的可能性。例如,P(下雨|路湿) 就是观测到路面湿这一事实时,其原因是由于下雨。公式右边分子有两项,前者是假设 H 成立的可能性,常称为先验概率,源自经验和知识。后者 P(D|H) 叫做似然概率,是假设 H 成立的前提下,观测到数据 D 的概率,例如下雨的情况下路湿的可能性。分母的 P(D) 是数据 D 发生的概率,这一项可以对 P(D|H) 针对各种可能性积分(消掉 H)而获得,因此称为边际概率。很多情况下,我们并不在乎后验概率的绝对值,只要能够比较不同假设(或原因)的可能性就可以决策,所以我们常常不需要真正计算 P(D)。
贝叶斯定理说明在评判现象背后的原因时,不仅要看这个原因的可能性有多大(先验概率),也要看这一原因产生现象的概率(似然概率)。还用道路湿这个例子来看:凌晨下雨后路面变湿的概率确实存在(但是也可能由于道路过于干燥而没有湿润的迹象),但是可能不如自来水管道泄露的情况下把路弄湿的概率高,即 P(道路湿|凌晨时下雨) < P(道路湿|自来水管道泄露),但是另一方面,凌晨时下雨的概率远大于自来水管道泄露的概率(至少在我居住的城市和小区是如此),即 P(凌晨时下雨)>>P(自来水管道泄露)。综合两方面因素,我们认为还是凌晨下雨是更加可能的原因。
2. 贝叶斯定理的意义
形式如此简单的贝叶斯定理被誉为「永远不死的理论」,为什么如此重要呢?我们从三个角度来考察:概率理论、科学方法和人脑认知。
首先,从理论意义上来讲,贝叶斯定理为概率论提供了新的基础。传统概率论学者实际属于频率学派,总是根据先验知识先假定一个先验概率(即确定概率分布的类型和参数),然后以此为基础进行概率推演。然而,在很多情况下先验概率并非能够精确获得,我们的认知总是存在各种各样的不确定性。换言之,绝大多数现象无法用「客观概率」刻画,只能从现有事实出发用我们脑中的「主观概率」加以统摄。贝叶斯学派则完全把自己放在观察者的角色,把先验概率看做是一种信念,通过观测数据不断修正前提假设,从而形成新的信念。不仅如此,在继续观测到新的数据后,我们还可以不断使用贝叶斯原理把现有信念和观测数据整合,从而持续更新后验概率并使得「主观概率」不断逼近「客观概率」。
其次,科学研究方法角度看,贝叶斯定理提供了一种发现的逻辑。频率学派实际上是认为现象背后的规律(例如概率分布和参数)是以柏拉图的「理念」形式客观存在的,只是我们不知道而已。贝叶斯学派则认为「理念」存在与否并不重要,只要我们能够以越来越强的信念了解规律就好。事实上,科学史上只有爱因斯坦等极少的几位大哲在狭义和广义相对论等极少的例子上能够完全从公设出发建立理论体系,然后让别人从实验证明其理论完全于观测数据吻合。更多的例如电磁理论和量子理论的大量发现,都是在观测数据基础上寻找最佳的理论解释才能建立的。典型的例子是普朗克定理的发现,普朗克发现只有使用量子假说才能完美的解释黑体辐射问题,从而打开了量子理论的大门。
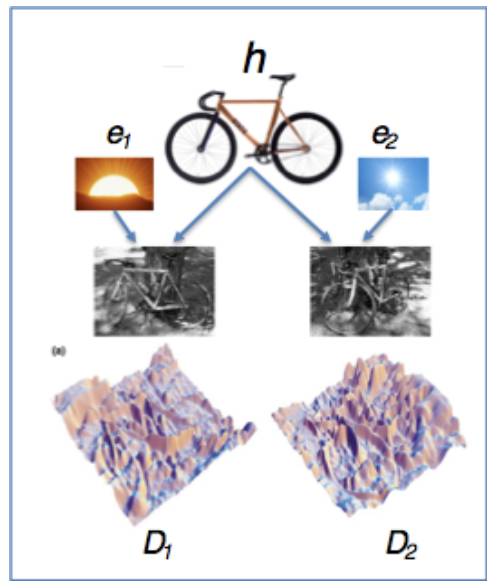
第三,从认知科学角度看,贝叶斯定理与大脑的认知机制存在极高的吻合度。仔细思考一下,就会发现我们在日常生活中在不停的利用贝叶斯定理。就以共享单车——ofo 小黄车为例来说,我们当然知道小黄车的颜色。然而,眼睛识别到的颜色实际上是光照的光谱和小黄车本身颜色光谱叠加的后果,即光照在小黄车上反射进入我们的眼睛,在不同的光照效果下我们看到的颜色差别可以非常之大,比如在夜间甚至可以完全看不出黄色。不过,不管白天黑夜,我们似乎总是能够正确的找到小黄车(现在的问题是我总是看到太多的小黄车和其它共享单车)。这就是因为人脑能够根据光照情况的先验概率和光照下小黄车颜色变化的规律(似然概率),自动推断在当前光照情况下单车是否是小黄车的后验概率。当然,人脑并不真正进行精确的概率运算,而是使用某种巧妙的近似机制(例如神经脉冲的数量、形状等)完成推理过程。目前,基于贝叶斯模型的人脑认知理论已经获得长足的进步,能够有效解释概念学习、物体识别、感知-运动集成和归纳等多种人脑认知行为。
3. 贝叶斯理论和其它人工智能理论
基于贝叶斯理论的学习和推断是人工智能的重要分支。那么,从类脑计算角度来看,贝叶斯理论和其它人工智能方法,特别是深度学习方法,又是什么关系呢?我们用下图做一个概要性的说明。
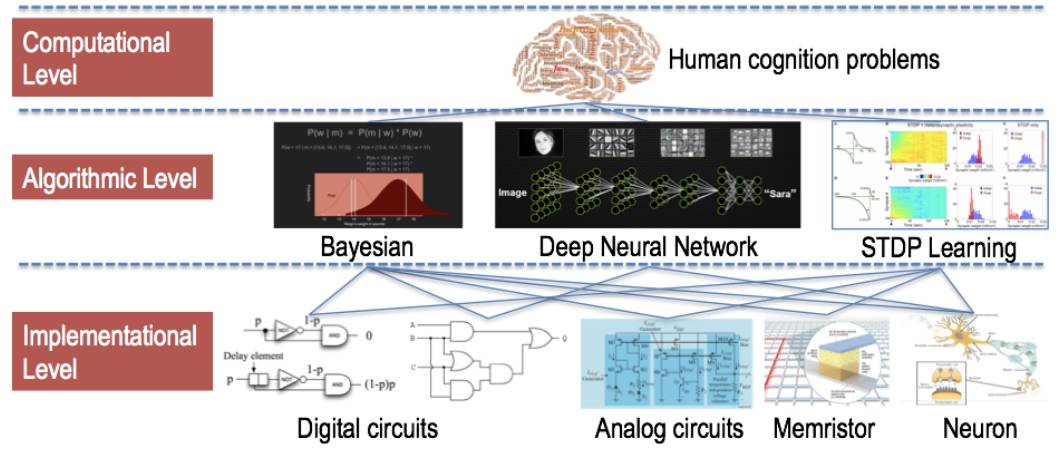
美国天才心理学家 Marr 认为理解和分析人脑需要三个层次的努力,即计算层、算法层和实现层。
计算层关注功能和接口,也就是人类某种认知行为完成的功能以及相应的输入和输出。典型的计算机任务包括视觉处理、记忆、理解、推理、语言、学习和创造等等。计算层不关心该实现功能的方法和物质基础。
算法层关注的是人类认知行为的实现方法,但不关心具体的物质基础。比如说,人脑学习的基本机制是神经突触可塑性,但是这里的神经元可以是生物神经元,也可以是硅基电路实现的神经元电路,也可以是由软件实现的神经元程序。深度神经网络也可以看做是图像分类、物体检测等认知活动的算法,而贝叶斯定理及其衍生出的方法实际上也提出了实现人脑行为的一大类算法。有趣的是,深度神经网络和贝叶斯方法似乎更多的是互补关系。深度神经网络擅长解决图像分类和物体检测问题,似乎主要对应视觉皮层的功能,而贝叶斯方法更适合于更加抽象的认知活动,例如归纳、推理和感知-运动集成等,对应于海马区、小脑等多个脑区的功能。
实现层解决用何种硬件(包括生物机制)实现相应算法。地球生物在漫长的进化过程中,最终采用神经元作为计算单元。也就是说,人脑的物质基础是神经元细胞连结而成的脉冲神经网络。而另一方面,当我们制造类脑计算机的时候,从目前技术来看,集成电路似乎是唯一可行的途径。值得说明的是,虽然算法层应该与实现层完全正交,不过实际上算法层总会对应于最适当的实现层,而实现层也总会对算法层有所制约。对于贝叶斯算法来说,数字电路完全可以作为实现层(即不必追求实现层与人脑的相似性),当然需要通过电路设计增强其随机采样和计算的能力。对于实现神经突触可塑性算法来说,模拟电路和忆阻器(memristor)是比较直观的硬件基础,而用数字电路实现神经突触可塑性就比较麻烦,例如在 IBM 的 TrueNorth 计算机中需要 2000 多个逻辑门才能搭建一个神经元。然而,数字电路在集成度和器件性能的一致性上具有极大优势。
总结上面的分析,应该说,贝叶斯理论是类脑计算的一个算法框架。以这个框架为基础,根据人脑认知行为的计算层要求,我们可以构造出相应的算法。以上算法可以使用计算机以软件形式实现,也可以设计专用的集成电路进行加速计算。
4. 贝叶斯计算
贝叶斯计算的核心就是求解后验概率,其方法包括马尔可夫链蒙特卡洛(Markov chain Monte Carlo,MCMC)方法和变分法。这里我们主要关注 MCMC 方法,因为其与人脑感知过程更为接近。MCMC 的思想是根据似然概率对随机采样进行选择,并使得采样过程形成的马尔可夫链收敛到目标后验概率。实现 MCMC 的具体算法很多,下面我们给出最经典的 Metropolis–Hastings(MH)算法的伪代码。该算法有三个主要步骤:1. 从一个已知概率分布 q(建议分布)上获得随机采样 X,2. 计算当前样本 X 的接受函数α,3. 如果 X 更好,则接受 X,否则以概率α接受 X。经过足够多的迭代采样后,按照上述 MH 算法得到的采样数据将服从我们想要的后验分布。

MH 算法的形式并不复杂,但是计算量可以极大,尤其在高维数据空间的收敛速度经常变得难以接受。其中,主要的复杂度在于需要大量样本,即需要大量次数的迭代才能达到收敛状态。而且,由于每一个状态都与前一状态相关,一般说来 MCMC 的并行比较困难,研究界普遍认为简单的多链并行效果不佳。除此之外,MH 算法涉及到大量随机抽样(每次迭代需要两个随机数),传统计算机上无法产生真随机数,而伪随机数往往需要大数计算,执行时效率很低。
5. 贝叶斯计算机
前面的描述实际上已经揭示出我们的企图:既然贝叶斯计算如此重要、计算量又如此之高,但是现有计算机并不适合贝叶斯计算,那么解决之道只能是设计新的硬件了。从硬件设计角度看,我们需要解决两个问题:1. 怎样尽可能直接的支持采样计算,即怎样用最少的逻辑单元产生常见的离散概率分布?2. 怎样支持硬件并行执行?
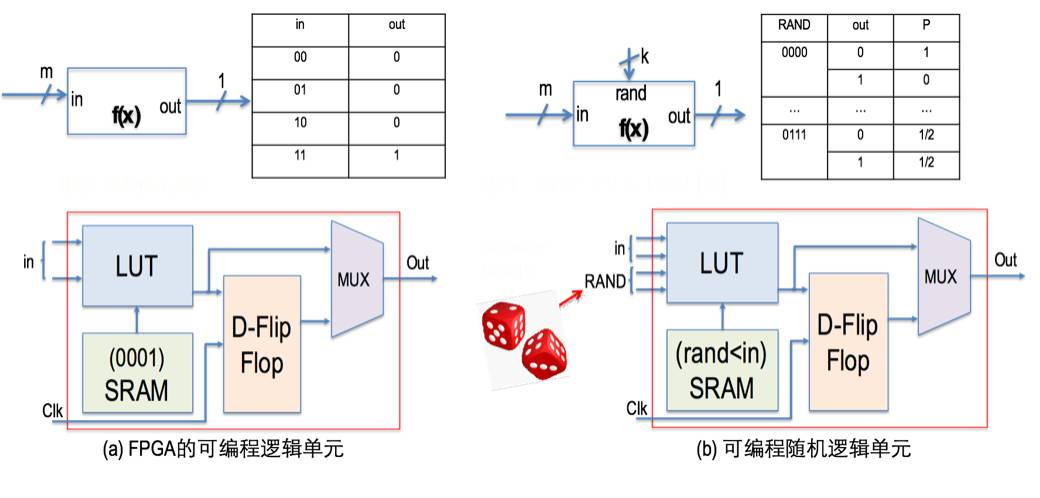
上图中给出了一种利用 FPGA 的可编程单元实现随机采样的电路设计方法。上图(a)是原始的 FPGA 可编程单元,其中可编程逻辑用查找表实现。也就是说,需要实现的逻辑功能的真值表存储在 SRAM 存储器中,各个输入变量的组合其实对应于查找真值表的地址。这样一来,我们只要对真值表进行编程,就可以让可编程单元实现任意逻辑函数,当然此时对应每一个输入组合的输出的确定性的。在上图(b)中,我们把输入分成两组,一组是正常的数字信号(in),另一组接随机数发生器(rand),相应的真值表则实现功能 rand
有了前述的随机组合逻辑,我们还可以引入存储单元(例如 D 触发器),形成随机时序电路。对电路结构进行适当的编程,我们就可以构造出计算 MCMC 的电路结构。然而,这样的电路还是只能顺序执行,也就是说只是提高了基本计算的性能。Calderhead 在 2014 年的美国科学院会刊上发表了一篇题为「A general construction for parallelizing Metropolis−Hastings algorithms」的论文,提出了一种能够有效的实现并行化 MH 算法的方法。其思想是引入一个新的离散随机变量,把原有马尔可夫链的概率计算转换为条件概率计算,然后通过条件概率对多个并行采样进行取舍,整个过程依然满足细致平稳的收敛条件。对我们的贝叶斯硬件来说,改算法提供了一种并行计算的框架。
以上的硬件当然也可以组织为处理器,下图是一种可能的贝叶斯计算机体系结构。该处理器以前面的随机逻辑单元作为基本计算电路,而并行 MCMCMCMC 则通过编程实现。既然是处理器,那么编程又怎样实现呢?显然,一个合适的编程模型是概率程序,例如 Stanford 设计的 STAN 语言和 MIT 设计的 Church 语言。概率程序的基本元素是概率变量,即其中的变量不再是确定性的,而是遵循某种概率。
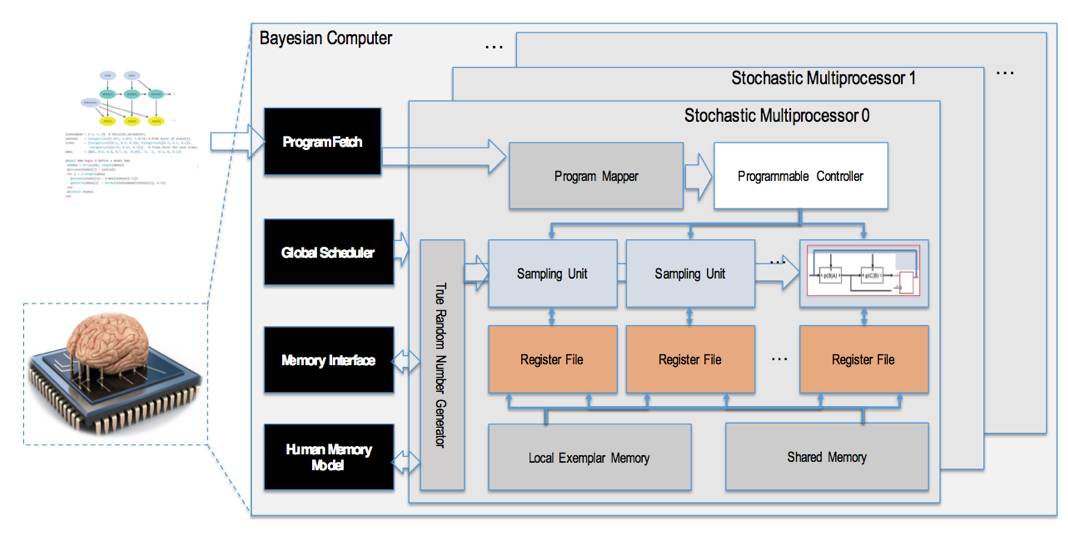
在我们的规划中,贝叶斯计算机将作为类脑计算的底盘,从而允许我们开发并实验一系列的认知方法,例如单词学习、长期和短期记忆模型、归纳、物理规律学习、感知-运动集成、理论学习等等。
6. 总结
到这里让我们的贝叶斯之旅先告一段落,我们工作还在继续,而我们的目标当然是人工智能的圣杯——构造象人那样学习和思考的机器,即「强人工智能」。甚至还要更好:事实上,人脑并不能进行精确的概率数值计算,因此虽然群体行为往往可以用贝叶斯原理解释,而个人行为则可能由于随机采用出现巨大偏差,那么我们的贝叶斯计算机能否成为「比人还好」的学习和思考机器呢?尽管听起来有点离经叛道,但我们总想试试、而且也值得试试,难道不是吗?
作者简介:邓仰东,发射资本资深科学顾问,中国清华大学软件学院副教授、博导,美国卡内基梅隆大学计算机工程专业博士。



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






