


深度 | 生成对抗网络初学入门:一文读懂GAN的基本原理(附资源)
2017年09月10日 18:56:52
来源:机器之心


原标题:深度 | 生成对抗网络初学入门:一文读懂GAN的基本原理(附资源)
选自 Sigmoidal
作者:Roman Trusov
机器之心编译
参与:Panda
生成对抗网络是现在人工智能领域的当红技术之一。近日,Sigmoidal.io 的博客发表了一篇入门级介绍文章,对 GAN 的原理进行了解释说明。另外,在该文章的最后还附带了一些能帮助初学者自己上手开发实验的资源(包含演讲、教程、代码和论文),其中部分资源机器之心也曾有过报道或解读,读者可访问对应链接查阅。
你怎么教一台从未见过人脸的机器学会绘出人脸?计算机可以存储拍字节级的照片,但它却不知道怎样一堆像素组合才具有与人类外表相关的含义。
多年以来,已经出现了很多各种各样旨在解决这一问题的生成模型。它们使用了各种不同的假设来建模数据的基本分布,有的假设太强,以至于根本不实用。
对于我们目前的大多数任务来说,这些方法的结果仅仅是次优的。使用隐马尔可夫模型生成的文本显得很笨拙,而且可以预料;变分自编码器生成的图像很模糊,而且尽管这种方法的名字里面有「变」,但生成的图像却缺乏变化。所有这些缺陷都需要一种全新的方法来解决,而这样的方法最近已经诞生了。
在这篇文章中,我们将对生成对抗网络(GAN)背后的一般思想进行全面的介绍,并向你展示一些主要的架构以帮你很好地开始学习,另外我们还将提供一些有用的技巧,可以帮你显著改善你的结果。
GAN 的发明
生成模型的基本思想是输入一个训练样本集合,然后形成这些样本的概率分布的表征。常用的生成模型方法是直接推断其概率密度函数。
在我第一次学习生成模型时,我就禁不住想:既然我们已经有如此多的真实训练样本了,为什么还要麻烦地做这种事呢?答案很有说服力,这里给出了几个需要优秀生成模型的可能的应用:
1. 模拟实验的可能结果,降低成本,加速研究
2. 使用预测出的未来状态来规划行动——比如「知道」道路下一时刻状况的 GAN
3. 生成缺失的数据和标签——我们常常缺乏格式正确的规整数据,而这会导致过拟合
4. 高质量语音生成
5. 自动提升照片的质量(图像超分辨率)
2014 年,Ian Goodfellow 及其蒙特利尔大学的同事引入了生成对抗网络(GAN)。这是一种学习数据的基本分布的全新方法,让生成出的人工对象可以和真实对象之间达到惊人的相似度。
GAN 背后的思想非常直观:生成器和鉴别器两个网络彼此博弈。生成器的目标是生成一个对象(比如人的照片),并使其看起来和真的一样。而鉴别器的目标就是找到生成出的结果和真实图像之间的差异。
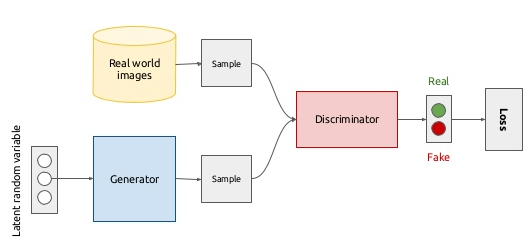
这张图给出了生成对抗网络的一个大致概览。目前最重要的是要理解 GAN 差不多就是把两个网络放到一起工作的方法——生成器和鉴别器都有它们自己的架构。要更好地理解这种思想的根源,我们需要回忆一些基本的代数知识并且问我们自己一个问题:如果一个网络分类图像的能力比大多数人还好,那么我们该怎么欺骗它?
对抗样本
在我们详细描述 GAN 之前,我们先看看一个有些近似的主题。给定一个训练后的分类器,我们能生成一个能骗过该网络的样本吗?如果我们可以,那看起来又会如何?
事实证明,我们可以。
不仅如此,对于几乎任何给定的图像分类器,都可以通过图像变形的方式,在新图像看起来和原图像基本毫无差别的情况下,让网络得到有很高置信度的错误分类结果!这个过程被称为对抗攻击(adversarial attack),而这种生成方式的简单性能够给 GAN 提供很多解释。
对抗样本(adversarial example)是指经过精心计算得到的旨在误导分类器的样本。下图是这一过程的一个示例。左边的熊猫所属的分类就和右边的不一样——右边的图被分类为了长臂猿。

图片来自:Goodfellow, 2017
图像分类器本质上是高维空间中的一个复杂的决策边界。当然,在涉及到图像分类时,我们没法画出这样的边界线。但我们可以肯定地假设,当训练完成后,得到的网络无法泛化到所有的图像上——只能用于那些在训练集中的图像。这样的泛化很可能不能很好地近似真实情况。换句话说,它与我们的数据过拟合了——而我们可以利用这一点。
让我们首先向图像加入一些随机噪声,并且确保噪声非常接近于 0。我们可以通过控制噪声的 L2 范数来实现这一点。你不用担心 L2 范数这个数学概念,对于大多数实际应用而言,你可以将其看作是一个向量的长度。这里的诀窍是你的图像中的像素越多,其平均 L2 范数就越大。所以,如果你的噪声的范数足够低,你就可以认为它在视觉上是不可感知的;但是在向量空间中,加入噪声的图像可以与原始图像相距非常远。
为什么会这样呢?
如果 H×W 的图像是一个向量,那么我们加入其中的 H×W 噪声也是一个向量。原始图像有各种各样相当密集的颜色——这会增加 L2 范数。另一方面,噪声则从视觉上看起来是一张混乱的而且相当苍白的图像——一个小范数的向量。最后我们将它们加到一起,得到的受损图像看起来和原图像很接近,但却会被错误地分类!
现在,如果原始类别「狗」的决策边界没有那么远(在 L2 范数角度来看),那么增加的这点噪声会将新的图像带到决策边界之外。
你不需要成为世界级的拓扑学家,也能理解特定类别的流形或决策边界。因为每张图像只是高维空间中的一个向量,在它们之上训练的分类器就是将「所有猴子」定义为「这个用隐含参数描述的高维 blob(二进制大对象)中的所有向量」。我们将这个 blob 称为该类别的决策边界。
好了,也就是说我们可以通过添加随机噪声来轻松欺骗网络。那生成新图像还必须做什么?
生成器和鉴别器
现在我们已经简单了解了对抗样本,我们离 GAN 只有一步之遥了!那么,如果我们前面部分描述的分类器网络是为二分类(真和加)设计的呢?根据 Goodfellow 等人那篇原始论文的说法,我们称之为鉴别器(Discriminator)。
现在让我们增加一个网络,让其可以生成会让鉴别器错误分类为「真」的图像。这个过程和我们在对抗样本部分使用的过程完全一样。这个网络称为生成器(Generator)。对抗训练这个过程为其赋予了一些迷人的特性。
在训练的每一步,鉴别器都要区分训练集和一些假样本的图像,这样它区分真假的能力就越来越强。在统计学习理论中,这本质上就意味着学习到了数据的底层分布。
那当鉴别器非常擅长识别真假时,欺骗它能有什么好处呢?没错!能用来学习以假乱真的赝品!

图片来自:Goodfellow, 2016
有一个古老但睿智的数学结果最小最大定理(Minimax theorem)开启了我们所知的博弈论的先河,其表明:对于零和博弈中的两个玩家而言,最小最大解决方案与纳什均衡是一样的。
哇!这都说的啥!
简单来说,当两个玩家(D 和 G)彼此竞争时(零和博弈),双方都假设对方采取最优的步骤而自己也以最优的策略应对(最小最大策略),那么结果就已经预先确定了,玩家无法改变它(纳什均衡)。
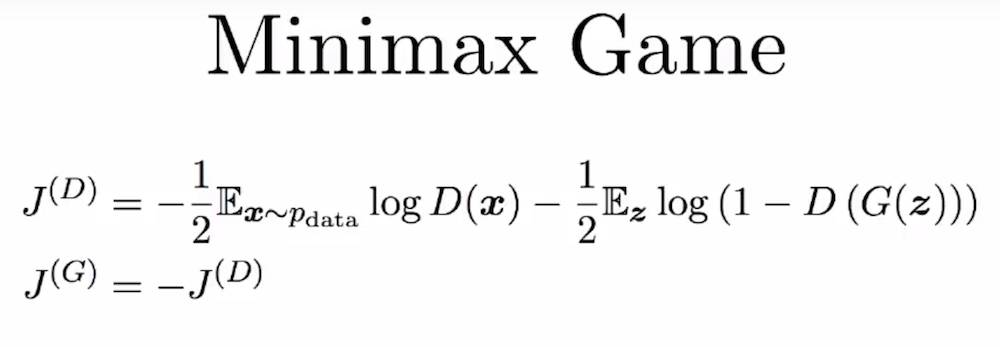
图片来自:Goodfellow, 2017
所以,对于我们的网络而言,这意味着如果我们训练它们足够长时间,那么生成器将会学会如何从真实「分布」中采样,这意味着它开始可以生成接近真实的图像,同时鉴别器将无法将其与真实图像区分开。
上手学习的最佳架构
理论归理论,当涉及到实践时,尤其是在机器学习领域,很多东西就是没法起效。幸运的是,我们收集了一些有用的小点子,可以帮助得到更好的结果。在这篇文章中,我们将首先回顾一些经典的架构,并提供一些相关链接。
深度卷积生成对抗网络(DCGAN)
在 GAN 的第一篇论文出来之后的大概一年时间里,训练 GAN 与其说是科学,倒不如说是艺术——模型很不稳定,需要大量调整才能工作。2015 年时,Radford 等人发表了题为《使用深度卷积生成对抗网络的无监督表征学习(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)》的论文,描述了之后被称为 DCGAN 的著名模型。

图片来自:Radford et al., 2015
关于 DCGAN,最值得一提的是这个架构在大多数情况下都是稳定的。这是第一篇使用向量运算描述生成器学习到的表征的固有性质的论文:这与 Word2Vec 中的词向量使用的技巧一样,但却是对图像操作的!

图片来自:Radford et al., 2015
DCGAN 是最简单的稳定可靠的模型,我们推荐从它开始上手。后面我们给出了一些训练和实现的有用技巧,并提供了代码示例的链接。
条件 GAN(Conditional GAN)
这是研究者提出的一种 GAN 的元架构的扩展,以便提升生成图像的质量,你也可以把它称为一个小技巧,百分之百没问题。其思想是,如果你的一些数据点有标签,你可以使用它们来构建显著的表征。这和你使用了哪种架构无关——这个扩展每次都是一样的。你需要做的全部事情就是为其生成器添加另一个输入。

图片来自:Mirza, 2014
所以,现在又如何呢?现在假如你的模型可以生成各种各样的动物,但你其实喜欢猫。现在你不再为生成器传递生成的噪声然后期待有最好的结果,而是为第二个输入增加一些标签,比如「猫」类别的 ID 或词向量。在这种情况下,就说生成器是以预期输入的类别为条件的。
诀窍和技巧
在真正实践时,你在上面读到的描述可不够用。只是介绍该算法的概况的教程也不行——通常他们的方法仅在用于演示的小数据集上才有效。在这篇文章中,我们的目标是为你提供一整套能让你自己上手研究 GAN 的工具,让你能立马开始自己开发炫酷的东西。
所以,你已经实现了你自己的 GAN 或从 GitHub 上克隆了一个(说实话,这是我力挺的开发方式)。在哪种随机梯度下降(SGD)的效果最好上,目前还不存在普遍共识,所以最好就选择你自己最喜欢的(我使用 Adam),并且在你实施长时间的训练之前要对学习率进行仔细的调节——这可以节省你大量时间。一般的工作流程很简单直接:
1. 采样训练样本的一个 minibatch,然后计算它们的鉴别器分数;
2. 得到一个生成样本 minibatch,然后计算它们的鉴别器分数;
3. 使用这两个步骤累积的梯度执行一次更新。
应该分开处理训练和生成的 minibatch,并且分别为不同的 batch 计算 batch norm,这是很关键,可以确保鉴别器有快速的初始训练。
有时候,当生成器执行一步时,让鉴别器执行一步以上的效果更好。如果你的生成器在损失函数方面开始「获胜」了,不妨试试这么做。
如果你在生成器中使用了 BatchNorm 层,这可能会导致 batch 之间出现很强的相关性,如下图所示:

图片来自:Goodfellow, 2016
基本而言,每一个 batch 都会得到同样的结果,其中只是稍微有些不同。你怎么防止这种情况发生?一种方法是预计算平均像素和标准差,然后每次都使用,但这常常会导致过拟合。作为替代,还有一种被称为虚拟批归一化(Virtual Batch Normalization)的妙招:在你开始训练之前预定义一个 batch(让我们称其为 R),对于每一个新 batch X,都使用 R 和 X 的级联来计算归一化参数。
另一个有趣的技巧是从一个球体上采样输入噪声,而不是从一个立方体上。我们可以通过控制噪声向量的范数来近似地实现这一目标,但是从高维立方体上真正均匀地采样会更好一点。
下一个诀窍是避免使用稀疏梯度,尤其是在生成器中。只需将特定的层换成它们对应的「平滑」的类似层就可以了,比如:
1.ReLU 换成 LeakyReLU
2. 最大池化换成平均池化、卷积+stride
3.Unpooling 换成去卷积
结论
在这篇文章中,我们解释了生成对抗网络,并且给出了一些训练和实现的实用技巧。在下面的资源一节中,你可以找到一些 GAN 实现,能帮你上手你自己的实验。
资源
演讲
1.Ian Goodfellow 在 NIPS 2016 的演讲《生成对抗网络》:参阅机器之心报道《独家 | GAN 之父 NIPS 2016 演讲现场直击:全方位解读生成对抗网络的原理及未来》
2.Ian Goodfellow 演讲《对抗样本和对抗训练》:https://www.youtube.com/watch?v=CIfsB_EYsVI
3.Soumith Chintala 在 NIPS 2016 的演讲《如何训练 GAN》:https://www.youtube.com/watch?v=X1mUN6dD8uE
教程
1. 来自 O'Reilly 的全面教程《生成对抗网络初学者》:https://www.oreilly.com/learning/generative-adversarial-networks-for-beginners
2. 极简教程,有很多可以发挥的空间:https://github.com/uclaacmai/Generative-Adversarial-Network-Tutorial
代码库
1.TensorFlow 实现 DCGAN:https://github.com/carpedm20/DCGAN-tensorflow
2.PyTorch 实现 DCGAN:https://github.com/pytorch/examples/tree/master/dcgan
3. 使用条件 GAN 生成动画人物:https://github.com/m516825/Conditional-GAN
论文
1. 生成对抗网络(Generative Adversarial Networks):https://arxiv.org/abs/1406.2661)
2. 使用深度卷积生成对抗网络的无监督表征学习)Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks):https://arxiv.org/abs/1511.06434
3. 条件生成对抗网络(Conditional Generative Adversarial Nets):https://arxiv.org/abs/1411.1784



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






