


学界 | MIT提出像素级声源定位系统PixelPlayer:无监督地分离视频中的目标声源
2018年04月13日 11:42:14
来源:机器之心

原标题:学界 | MIT提出像素级声源定位系统PixelPlayer:无监督地分离视频中的目标声源
原标题:学界 | MIT提出像素级声源定位系统PixelPlayer:无监督地分离视频中的目标声源
选自arxiv
作者:Hang Zhao、Chuang Gan、Andrew Rouditchenko、Carl Vondrick Josh McDermott、Antonio Torralba
机器之心编译
参与:刘晓坤、李泽南
相比单模态信息,多模态信息之间的关联性能带来很多有价值的额外信息。在本文中,MIT 的研究员提出了 PixelPlayer,通过在图像和声音的自然同时性提取监督信息,以无监督的方式实现了对视频的像素级声源定位。该系统有很大的潜在应用价值,例如促进声音识别,以及特定目标的音量调整、声音移除等。
论文链接:https://arxiv.org/pdf/1804.03160.pdf
项目地址:http://sound-of-pixels.csail.mit.edu/
这个世界上存在视觉和听觉信号的丰富资源。本文提出的视觉和听觉系统可以识别目标、分割目标覆盖的图像区域,以及分离目标产生的声音。虽然听觉场景分析 [1] 在环境声音识别 [2,3] 声源分离 [4,5,6,7,8,9] 已被广泛研究过,但实际上,图像和声音之间的自然同时性可以提供丰富的用于定位图像中的声音的监督信息 [10,11,12]。训练系统从图像或声音中识别目标通常需要大量的监督信息。然而在本文中,研究者利用声音-图像的联合学习来识别图像中生成声音的目标,并且不需要任何人工监督 [13,14,15]。
MIT 的研究表明:通过结合声音和图像信息,机器学习系统能以无监督的方式从图像或声音中识别目标、定位图像中的目标,以及分离目标产生的声音。该系统被称为 PixelPlayer。给定一个输入视频,PixelPlayer 可以联合地将配音分离为目标组件以及在图像帧上定位目标组件。PixelPlayer 允许在视频的每个像素上定位声源。
研究人员利用了图像和声音的自然同时性来学习图像声源定位模型。PixelPlayer 以声音信号为输入,并预测和视频中空间定位对应的声源信号。在训练过程中,研究者利用了自然声音的可加性来生成视频,其中构成声源是已知的。研究者通过混合声源来训练模型生成声源。
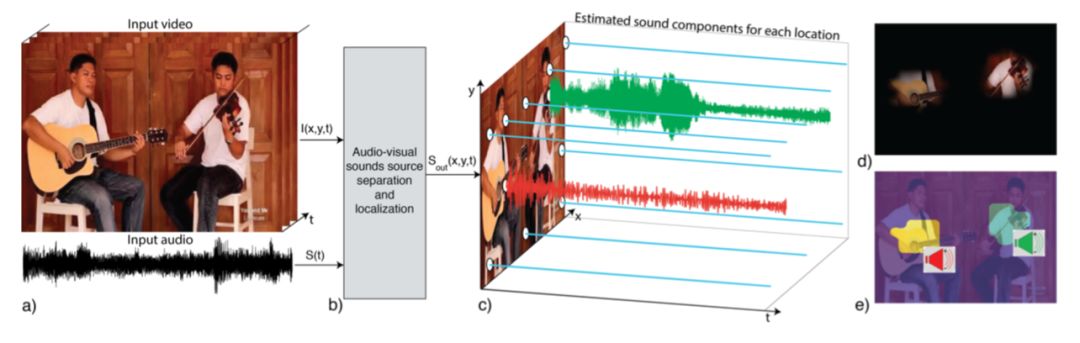
图 1:图中展示了 PixelPlayer 的一个应用案例(输出视频结果请查看补充材料)。
在这个案例中,该系统用大量的不同组合的人们弹奏乐器的视频来训练,包括独奏和二重奏。所有视频都不包含使用乐器的标签、定位,以及音乐的听觉性质。在测试时,输入(图 1 a)是多个乐器一起弹奏的视频,其中包括图像帧 I(x,y,t)和单声道音频 S(t)。PixelPlayer 将执行声音-图像源分离和定位,分割输入声音信号来评估输出声音组件 Sout(x,y,t),每个组件对应视频帧中空间定位(x,y)中的声源。图 1 c 展示了 11 个示例像素的复原声音信号。平直的蓝线对应没有生成声音的的像素。非平直的信号对应来自每个独立乐器的声音。图 1 d 展示了每个像素的评估声音能量,或声音信号的音量。注意,系统准确地检测到了声音是来自两个乐器,而不是来自背景。图 1 e 展示了像素如何根据它们的组件声音信号进行聚类。相同的颜色被被分配到生成非常相似声音的像素。
将声音整合到图像中的系统将拥有很广泛的应用,例如视频识别和操控。PixelPlayer 的分离和定位声源的能力将允许更多对目标声音的独立操作,并可以促进声音识别。该系统还可以促进视频的声音编辑,例如,特定目标的音量调整,或移除特定目标的声音等。
与本研究平行的还有近期的两篇论文 [16,17],它们也展示了结合图像和声音来将声音分解成组件的应用价值。[16] 展示了人的外观如何帮助解决语音领域中的鸡尾酒会问题。[17] 展示了一个声音-图像系统,其可以将屏幕场景产生的声音和视频中不可见的背景声音分离。
论文:The Sound of Pixels

摘要:我们提出了 PixelPlayer,该系统通过大量无标签视频数据训练,来学习定位图像中生成声音的区域,并将输入声音分割成一系列组件,以表征源于每个像素的声音。我们的方法利用了视觉和听觉模态的自然同时性来学习模型,可在不需要额外人工监督的情况下,联合解析声音和图像。在最新收集的 MUSIC 数据集上的实验结果表明,我们提出的 Mix-and-Separate 框架在图像的声音定位任务上超越了基线方法。多项定性结果表明,我们的模型可以在视野中定位声音,可应用于例如独立地调整声源的音量这样的任务。
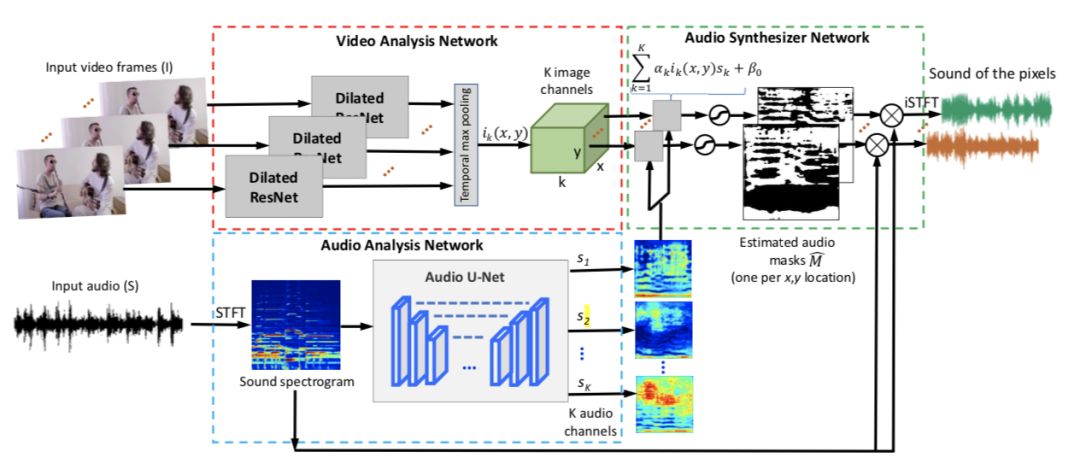
图 2:生成像素关联声音的流程:像素级视觉特征通过对扩张 ResNet 的输出的 T 个帧进行时间最大池化得到。输入声音的频谱传递到一个 U-Net 中,其输出是 K 个音频通道。每个像素的声音由一个声音合成器网络计算得到。声音合成器网络输出一个掩码,其将被应用到输入频谱上,以选择和该像素相关的频谱组件。最后,将 inverse STFT 应用到频谱上为每个像素计算并生成最终的声音输出。
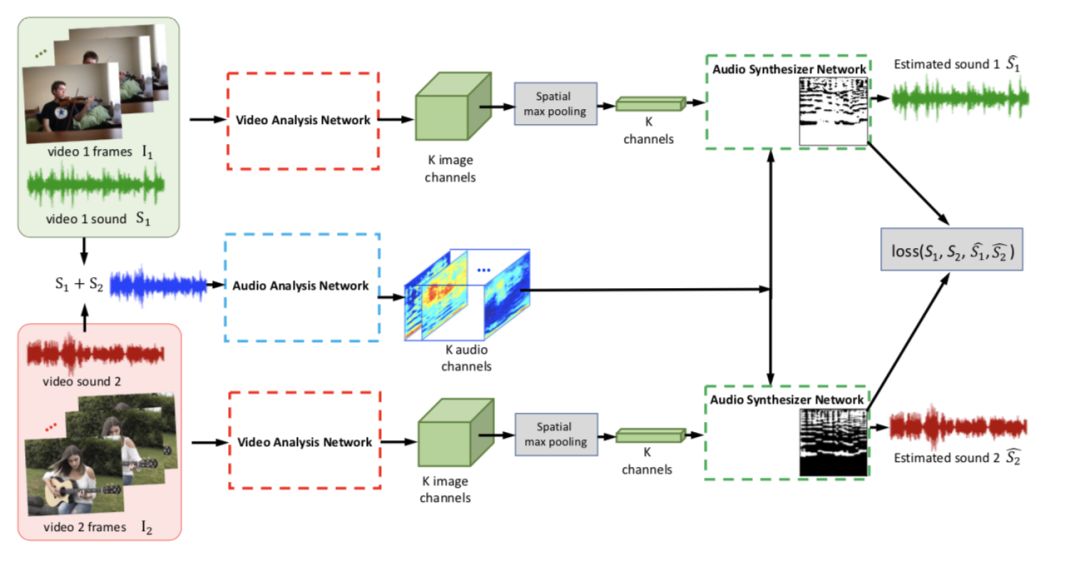
图 3:本文提出的 Mix-and-Separate 模型的训练流程,以混合两个视频为例(N=2)。
虚线框表示图 2 中详细描述的模块。来自两个视频的声音将被加到一起来生成已知构成声源信号的输入混合体。该网络被训练来根据对应的视频帧分离声源信号;它的输出是对两个声音信号的评估。注意:这里并没有假设每个视频都包含了单个声源。此外,这里没有提供任何标注。因此该系统可以学习分离独立声源,而不需要传统方法中的监督信息。
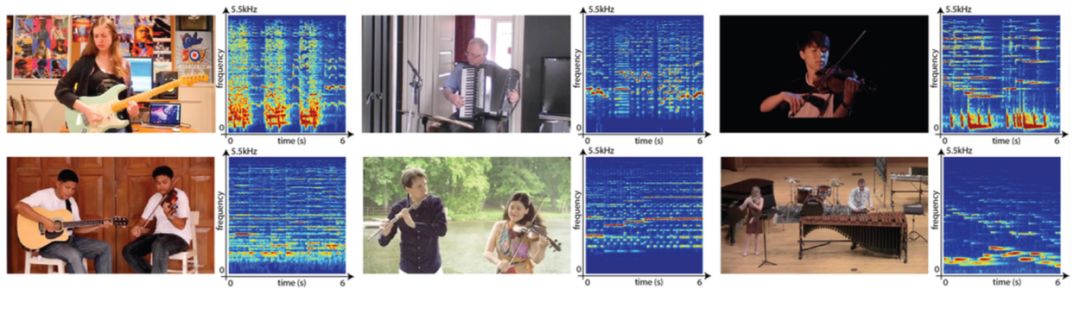
图 4:本研究使用的视频数据集的示例帧和相关声音。上行展示了独奏视频,下行展示了二重奏视频。其中声音以时频域的声谱展示,频率以对数标度表示。

图 5:数据集统计:(a)展示了视频类别的分布。其中有 565 个独奏视频和 149 个二重奏视频。(b)展示了视频时长的分布。平均时长为 2 分钟。
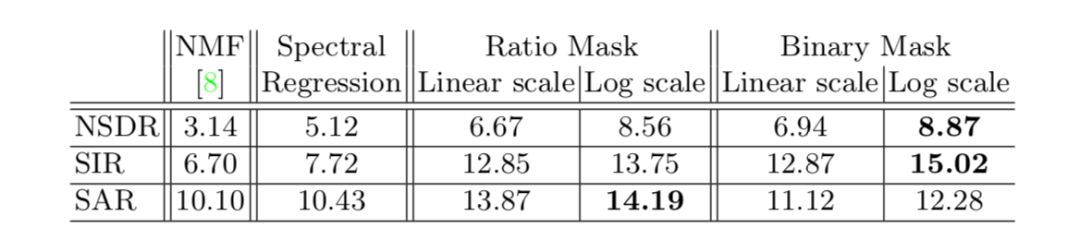
表 1:NMF 的和本文提出模型的不同变体的性能,在 NSDR/SIR/SAR 指标上评估。对数频率标度的 Binary masking 在所有指标上获得了最好的总体成绩。
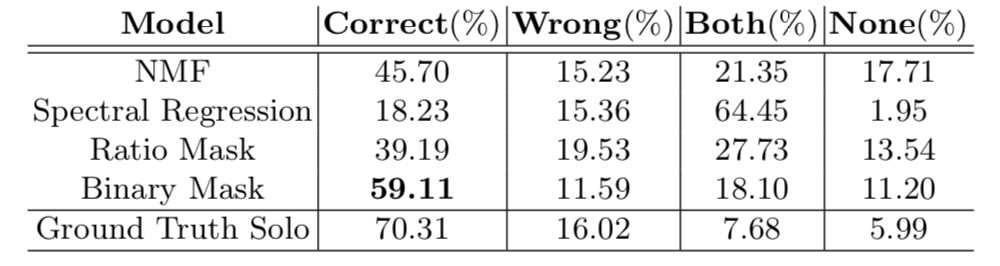
表 4:声音分离性能的主观评估。基于 Binary masking 的模型在声音分离中超越了其它所有模型。



- 0好文

- 0钦佩

- 0喜欢

- 0泪奔

- 0可爱

- 0思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128
图片新闻







