

英伟达发布Llama-3.1-Nemotron-Ultra-253B-v1模型,推动AI高效部署




独家抢先看
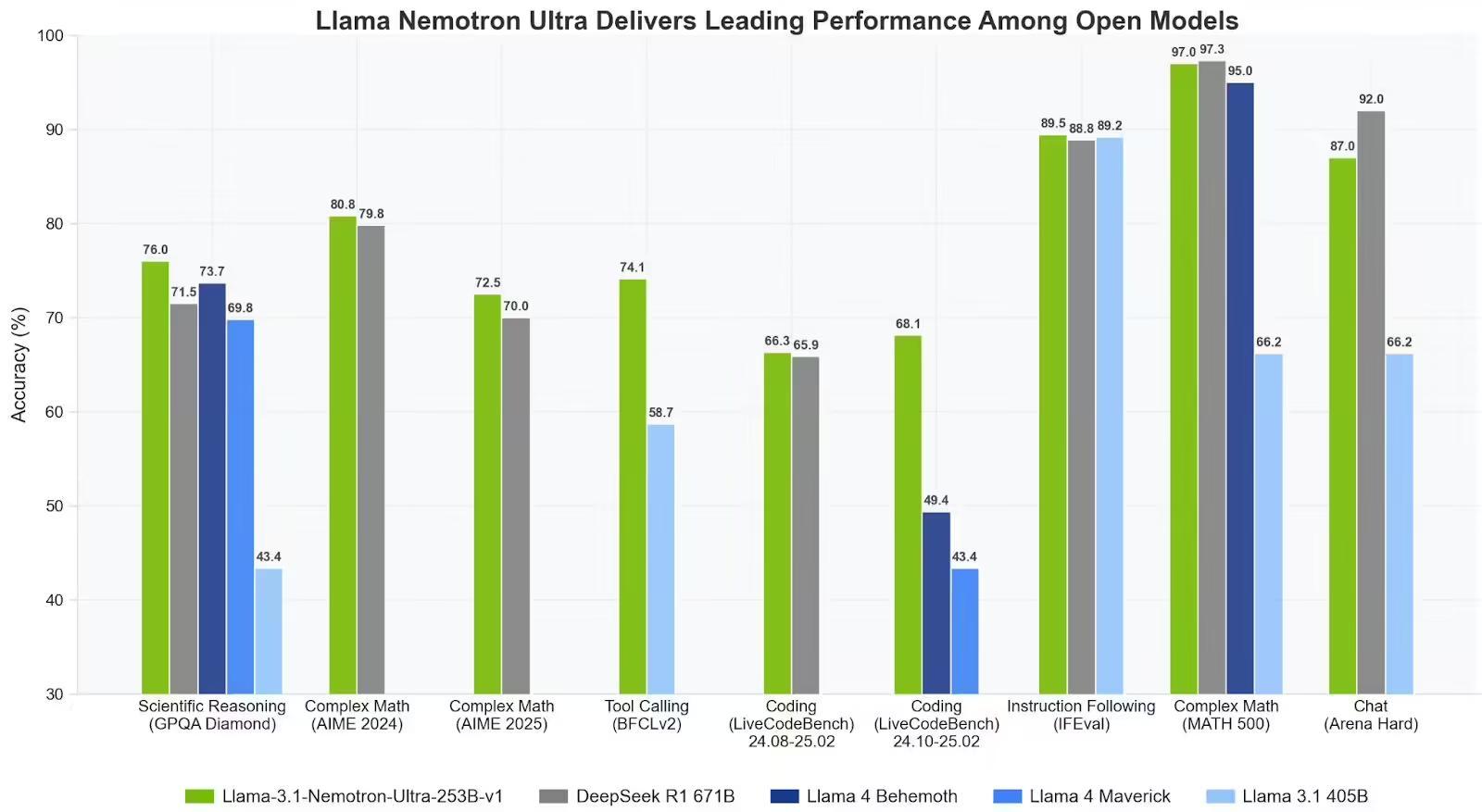
IT之家 4月12日消息,科技媒体 marktechpost 昨日(4月11日)发布博文,报道称英伟达发布Llama-3.1-Nemotron-Ultra-253B-v1,这款2530亿参数的大型语言模型在推理能力、架构效率和生产准备度上实现重大突破。
随着AI在数字基础设施中的普及,企业与开发者需在计算成本、性能与扩展性间寻找平衡。大型语言模型(LLM)的快速发展提升了自然语言理解和对话能力,但其庞大规模常导致效率低下,限制大规模部署。
英伟达最新发布的Llama-3.1-Nemotron-Ultra-253B-v1(简称Nemotron Ultra)直面这一挑战,该模型基于Meta的Llama-3.1-405B-Instruct架构,专为商业和企业需求设计,支持从工具使用到多轮复杂指令执行等任务。
IT之家援引博文介绍,Nemotron Ultra采用仅解码器的密集Transformer结构,通过神经架构搜索(NAS)算法优化,其创新之处在于采用跳跃注意力机制,在部分层中省略注意力模块或替换为简单线性层。
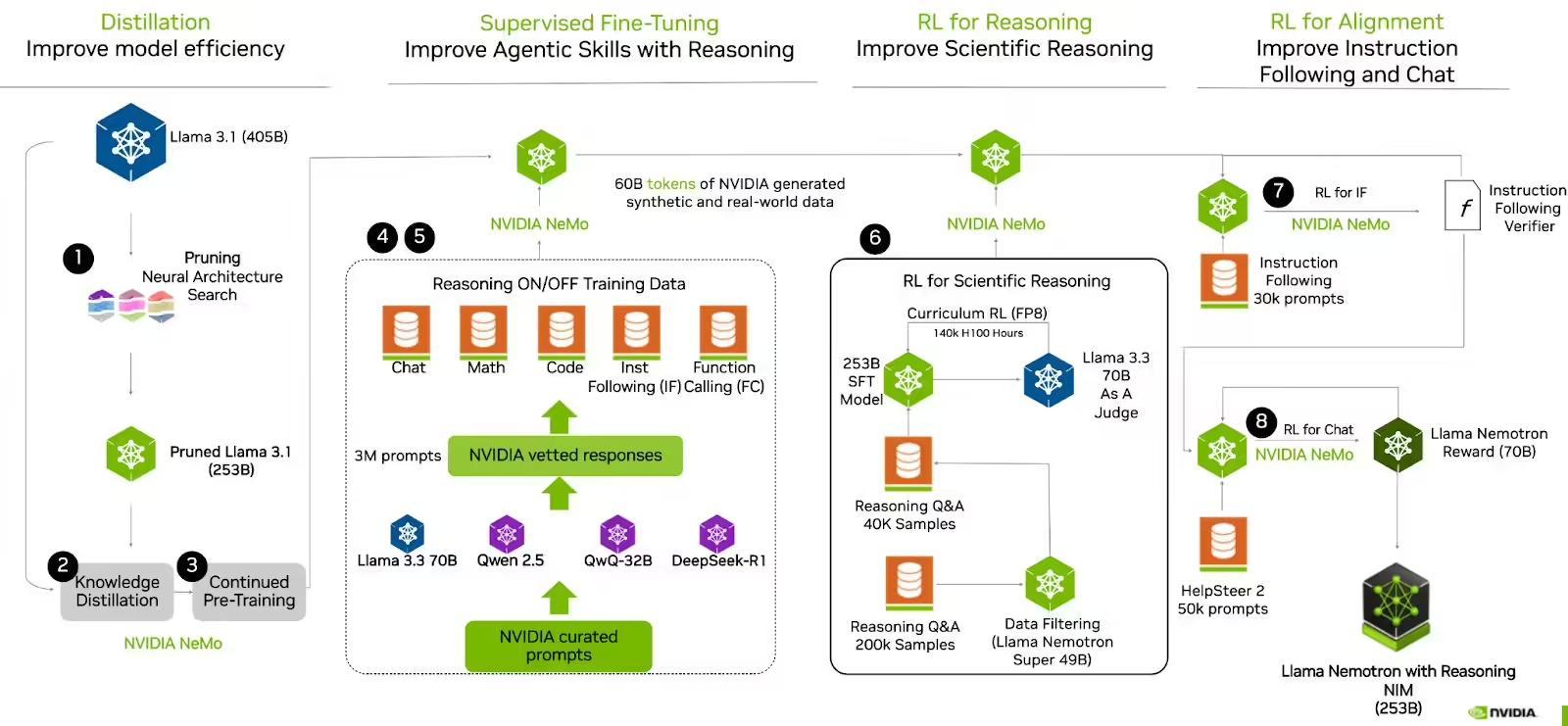
此外,前馈网络(FFN)融合技术将多层FFN合并为更宽但更少的层,大幅缩短推理时间,同时保持性能。模型支持128K token的上下文窗口,可处理长篇文本,适合高级RAG系统和多文档分析。
在部署效率上,Nemotron Ultra 也实现突破。它能在单8xH100节点上运行推理,显著降低数据中心成本,提升企业开发者的可及性。

英伟达通过多阶段后训练进一步优化模型,包括在代码生成、数学、对话和工具调用等任务上的监督微调,以及使用群体相对策略优化(GRPO)算法进行强化学习(RL)。这些步骤确保模型在基准测试中表现出色,并与人类交互偏好高度契合。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

