

阿里QVQ-Max来了!超绝视觉推理模型,会看网课学编程,免费可用




独家抢先看
作者 | 程茜
编辑 | 心缘
智东西3月28日报道,阿里大模型表情包军团再添猛将!今日凌晨,大模型“劳模”阿里云通义团队发布其首款视觉推理模型QVQ-Max。
在数学问题、生活常识、编程代码、艺术创作等场景,该模型可以看懂图片和视频里的内容,还能结合这些信息进行分析、推理,并给出解决方案。
例如,QVQ-Max可以协助用户在工作中完成数据分析、信息整理、编程写代码等任务,帮助学生解答配有图表的数学、物理等科目的难题,并通过直观的方式讲解复杂概念,在生活中根据衣柜照片推荐穿搭方案、基于食谱图片指导用户烹饪。
用户只需上传任何图像或视频然后提出问题,点击 “思考 ”按钮,即可查看它如何逐步处理视觉信息。
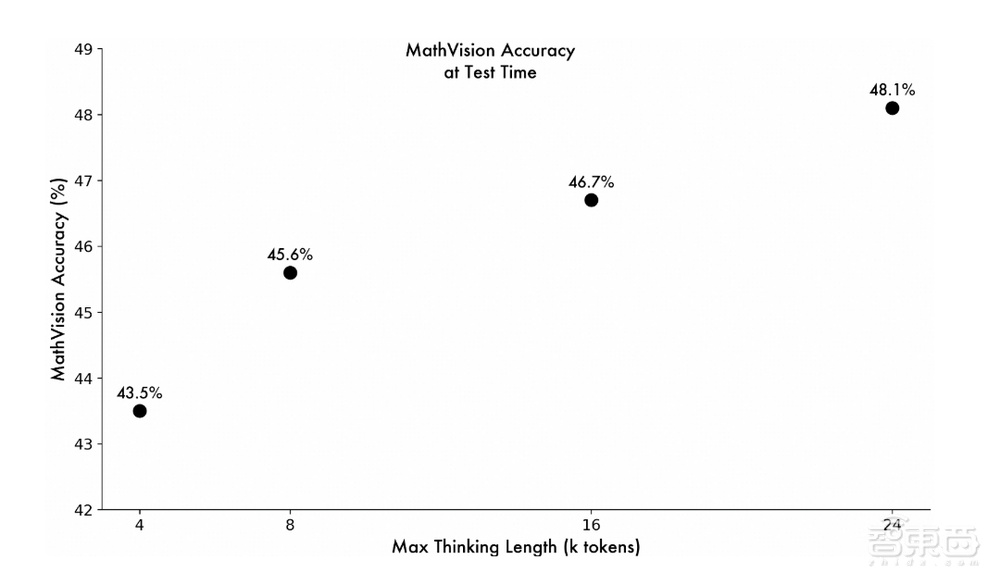
多模态数学问题的数据集MathVision可以用来评估模型解决复杂数学问题的能力,研究人员发现,模型思考的token数越长,其MathVision的准确度就会越高。
博客中提到,他们设计QVQ-Max的目标,就是让它成为一个既“眼尖”又“脑快”的助手,帮助用户解决各种实际问题。
一、秀多图识别、数学推理、看视频学习编程技能
阿里通义团队在博客中放出了几个新鲜的QVQ-Max演示案例。
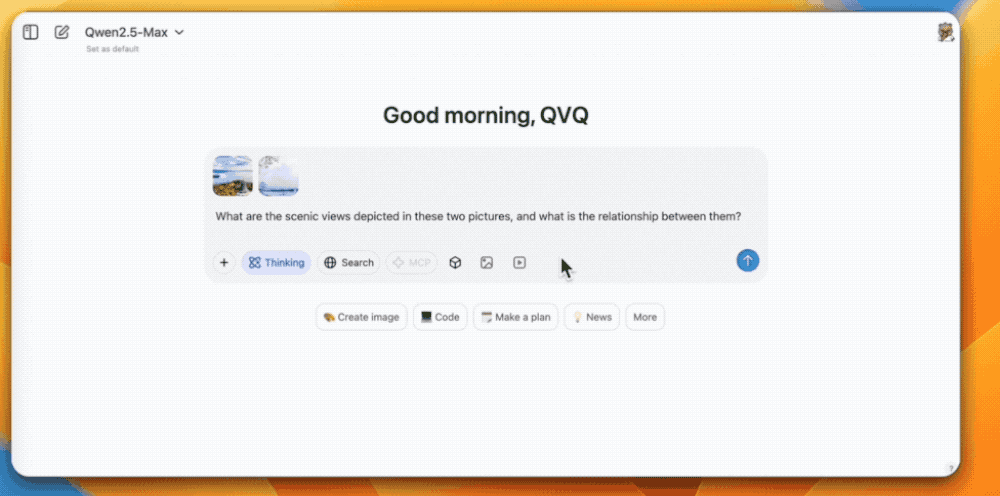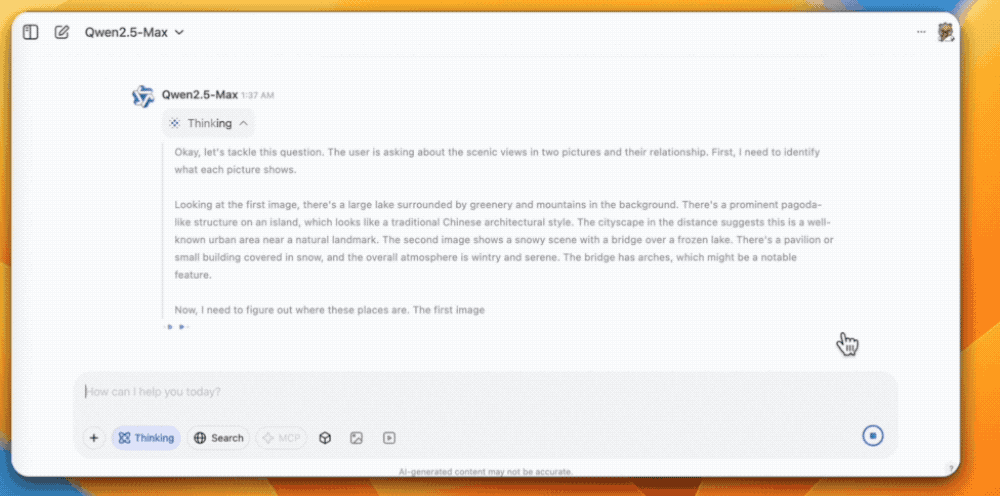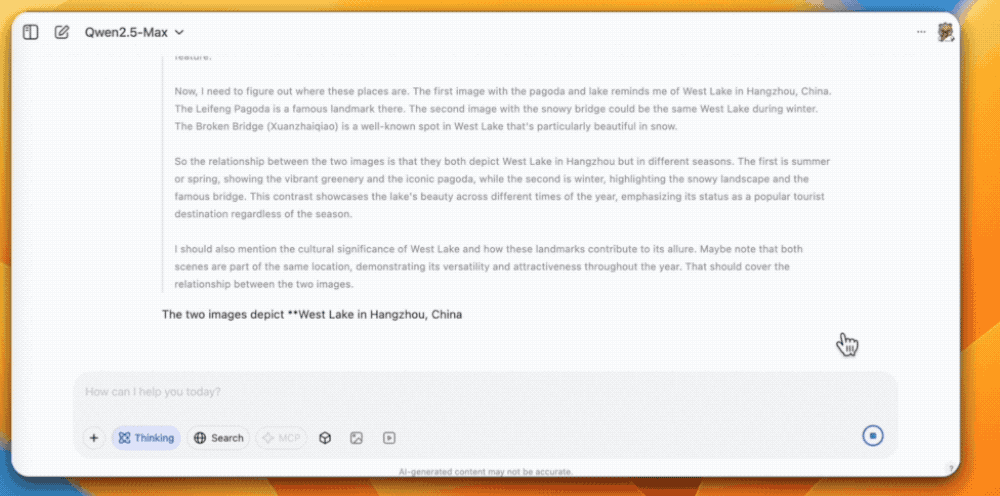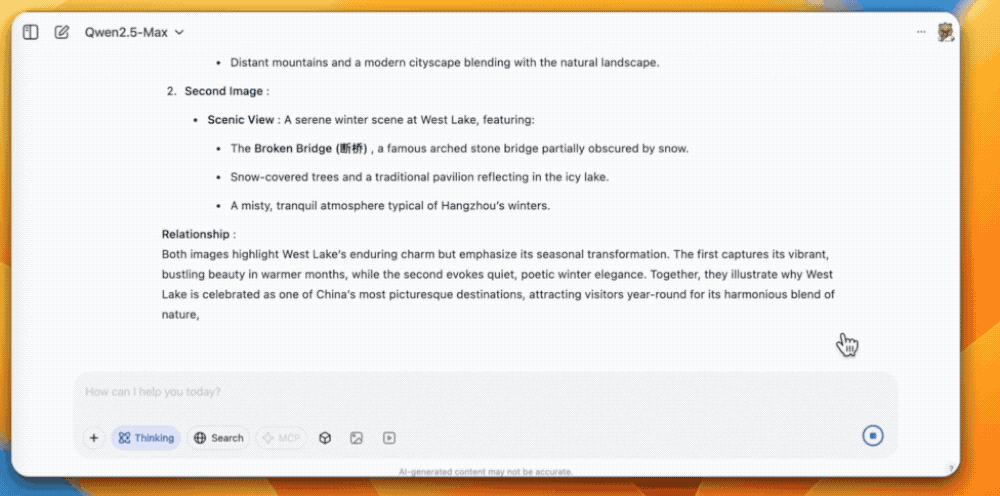
首先是多图识别,QVQ-Max可以描述图片中的景色,并且通过分析图片信息找到这两张图片的相关之处。
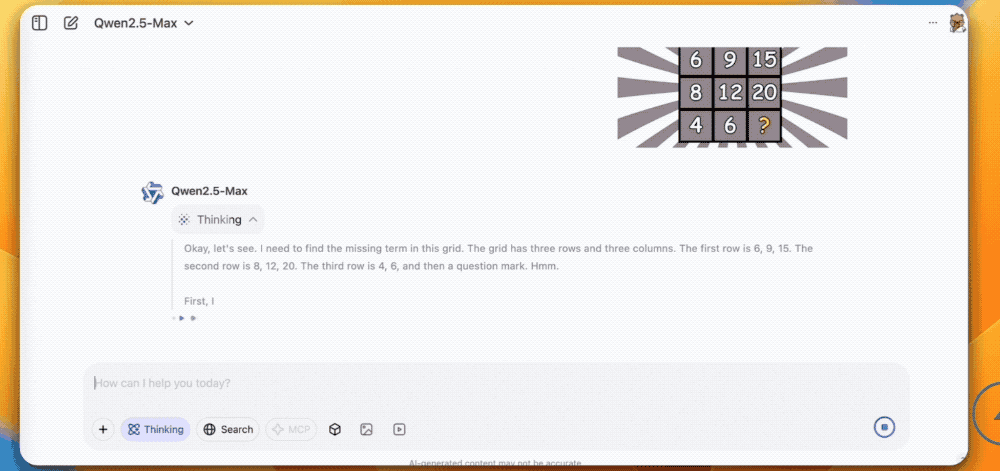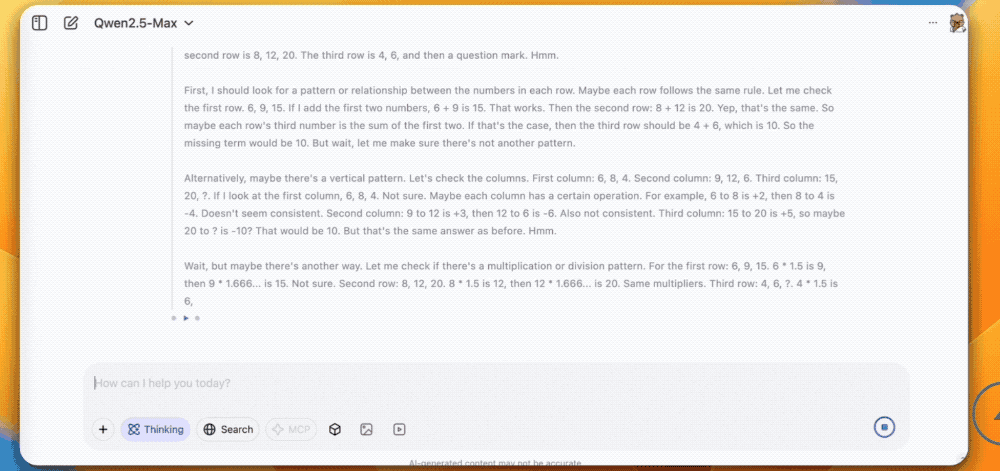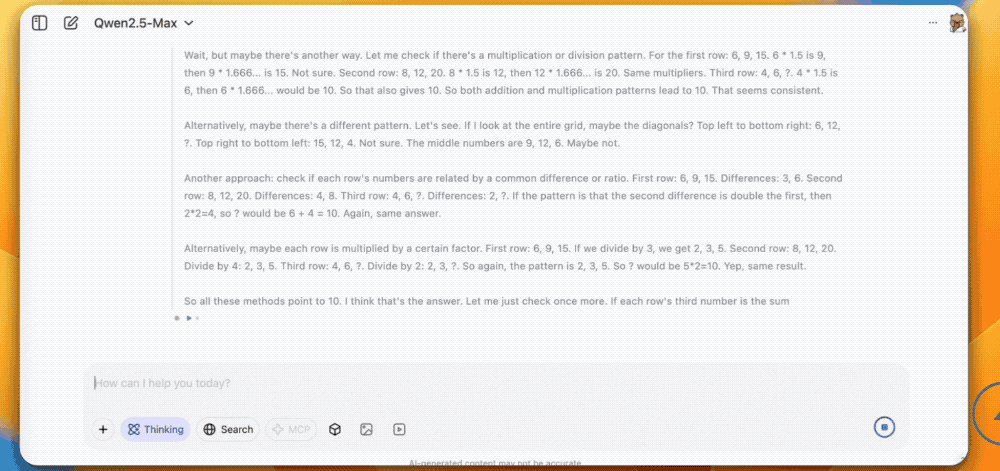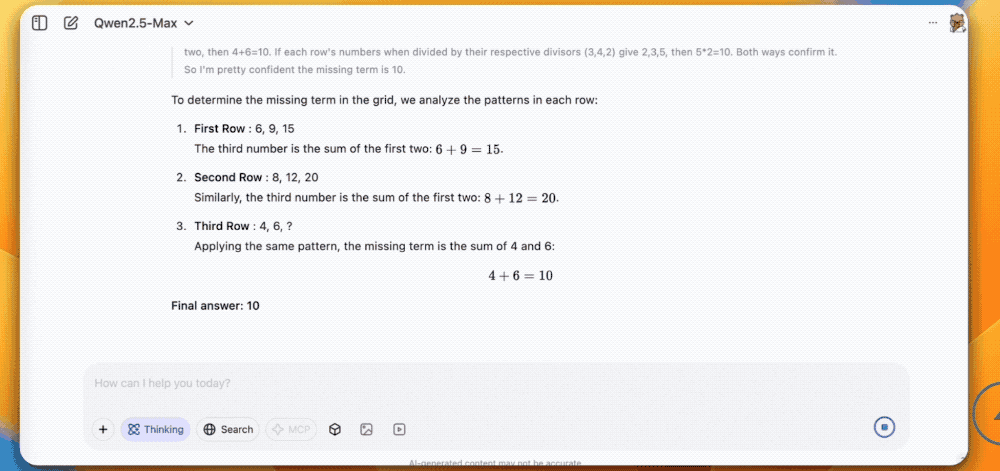
其次是数学推理,这道难题需要模型从图片中找问题和答案,QVQ-Max通过分析其余8个数字之间的关系,得出了最后一格的数字应该是10的正确答案。
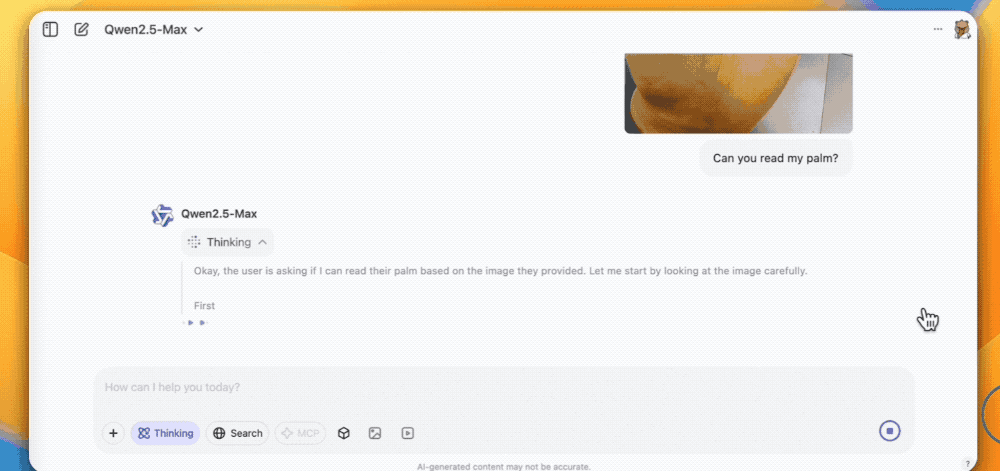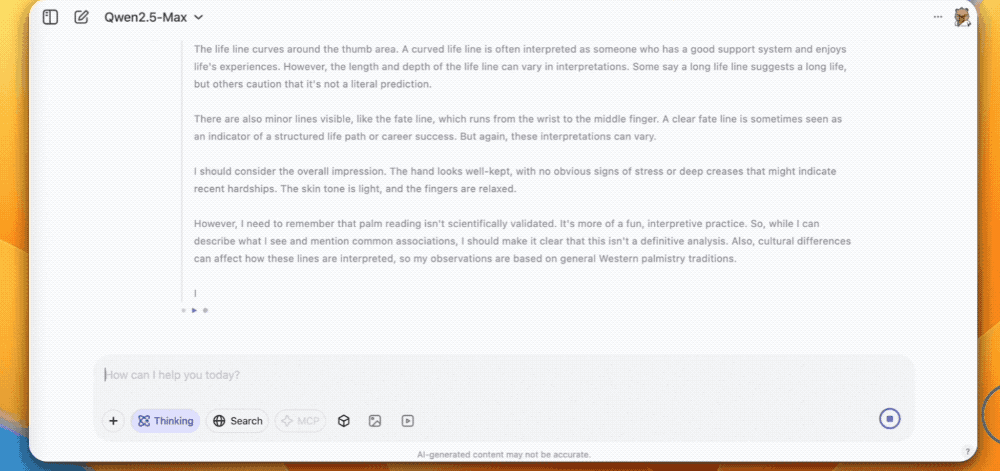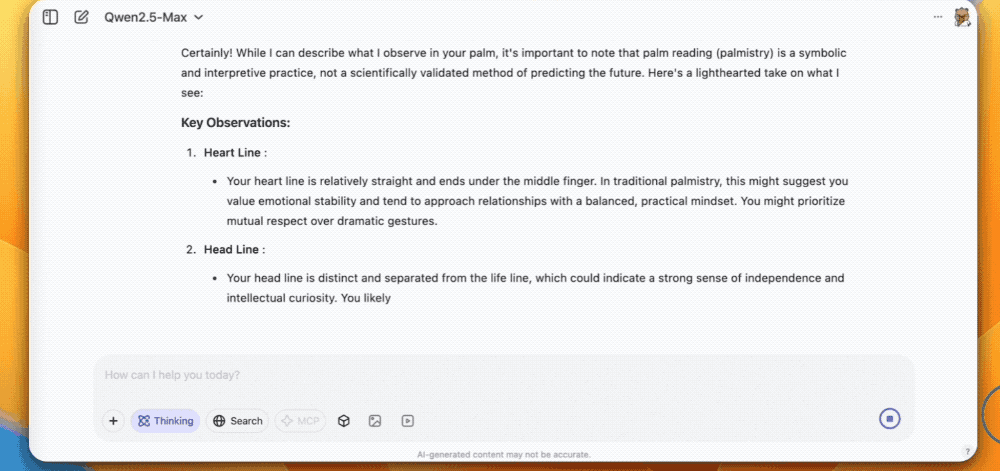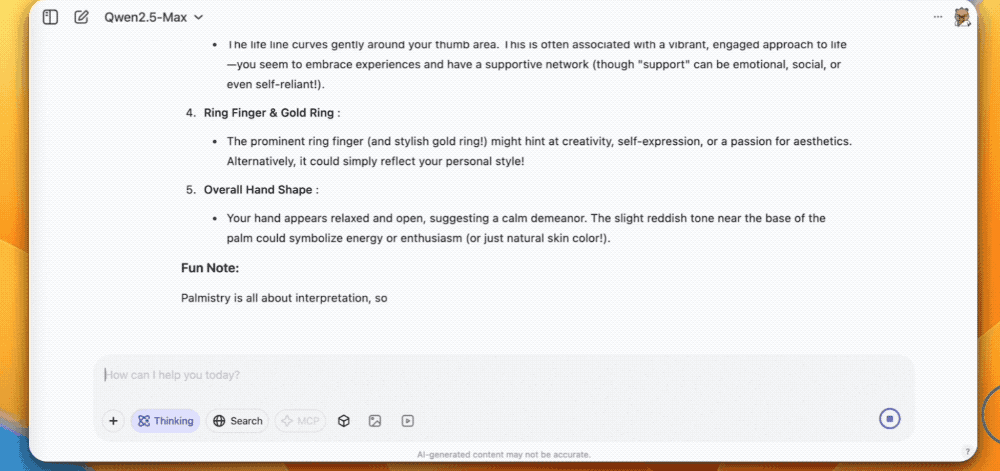
第三个是让QVQ-Max看手相,感情线、生命线、事业线分析得头头是道。
第四个考验了模型的视频理解能力,演示中模型对一个简笔画的蜗牛视频进行了分析,然后为这条视频创建了贴合的字幕。

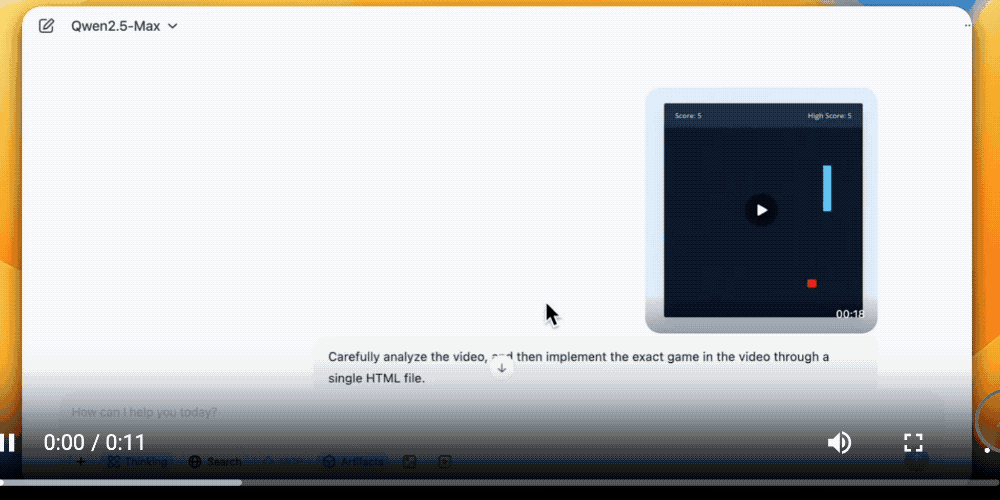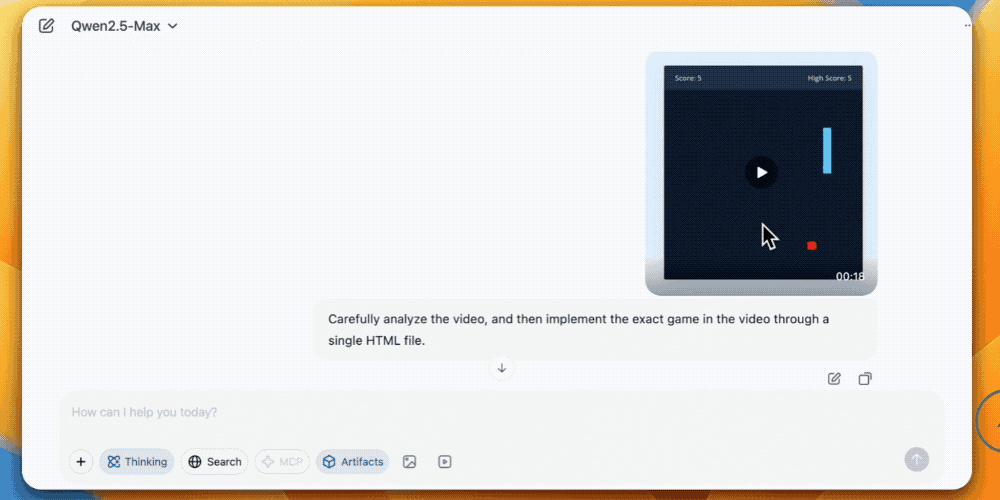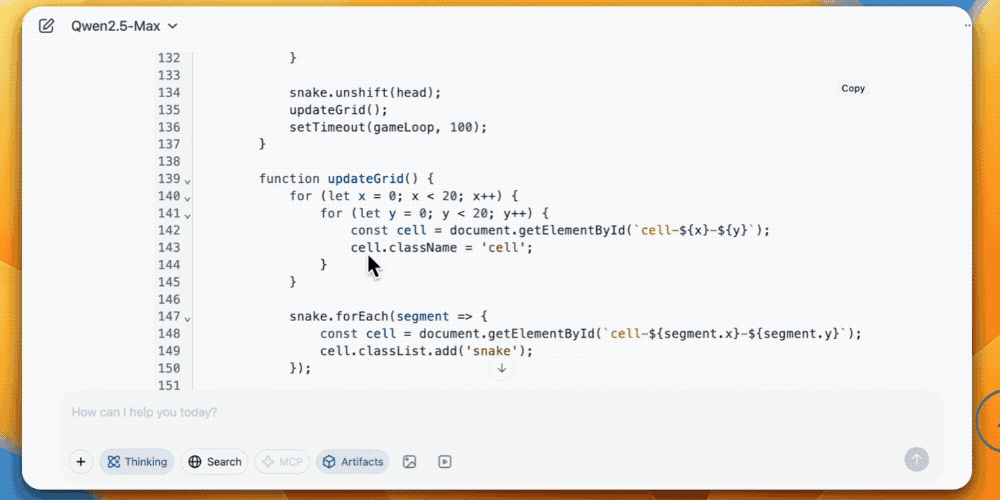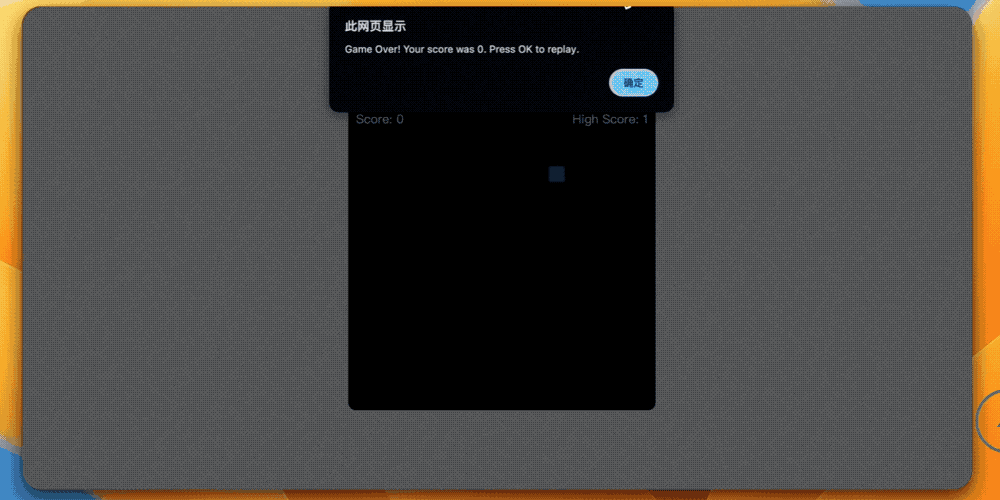
最后一个是让QVQ-Max看视频自学编程,在观看了一个类似贪吃蛇的小游戏视频后,QVQ-Max很快就复刻了一个类似游戏,给出了完整的代码。
二、观察细致入微、深入分析,还能灵活创作
QVQ-Max的能力可以总结为三个方面:细致观察、深入推理和灵活应用。
细致观察方面,QVQ-Max能快速识别出复杂图表、日常随手拍照片中的关键元素,例如它可以找到图片中有哪些物品、有什么文字标识等。
深入推理就是让模型基于看到的内容进行分析,然后结合背景知识得出结论。例如,在一道几何题中,它可以根据题目附带的图形推导出答案;在一段视频里,它能根据画面内容推测出接下来可能发生的情节。
除了分析和推理,QVQ-Max还可以灵活应用这些能力进行创作,例如帮助用户设计插画、生成短视频脚本、创作角色扮演的内容,或者化身评论家、占卜师。
这使得其在用户工作、学习、生活中的应用场景增多。
一般而言,大模型在回答问题、写文章、生成代码时主要依赖文字输入。
但现实生活中,很多信息并不只是用文字表达,而是图片、图表、视频、文字交互出现,并且图片中包含的信息会比文字更直观、更复杂,如其中的颜色、形状、位置关系等。例如用户分析建筑图纸时,仅靠文字描述是无法判断其合理性的,需要结合图纸以及专业知识分析,这也是阿里通用团队研究视觉推理模型的原因。
结语:视觉推理模型的演进方向:更准确观察、视觉Agent、交互多元
目前发布的QVQ-Max是阿里通义视觉推理模型的第一版,未来,研究人员会重点关注以下几个方向:通过视觉内容的校验来检查观察内容的准确性提高识别能力;通过视觉Agent提升模型在处理多步和更复杂的任务,如手机电脑操控,玩游戏;让模型在思考和交互中不局限于文字,还可以涵盖更多的模态,比如工具校验,视觉生成等。
作为一款能看懂又能深度推理的视觉模型,QVQ-Max已经展现出了完成创造性任务的应用潜力。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

