

省钱,我只服梁文锋




独家抢先看

DeepSeek最让人诟病的地方就是服务器总崩,但是从现在开始,DeepSeek可能再也不会出现服务器卡顿和宕机了。
原因在于,梁文锋挂名发表了一篇论文,标题为《DSpark:基于置信度调度的推测解码与半自回归生成》。按照DeepSeek的传统,DSpark读起来应该是D·Spark,而不是DS·park。
这是梁文锋从2024年发表的《DeepSeek LLM》之后,他挂名发表的第12篇论文。不只是如此,DSpark这篇论文,还和梁文锋在2010年发表的硕士毕业论文“撞车”了。
DSpark相当于是给DeepSeek装上了加速器,对用户来说,体感就是快、稳、不崩。
同样质量的回答,速度直接快了60%到80%,原来等10秒的回复现在五六秒就出来.
最关键的是,高峰时段,DeepSeek也不会再一直“转圈”了。
这个DSpark到底有多神奇?别急,我讲给你听。

DSpark到底是什么,
解决了DeepSeek什么老问题
大模型生成文字这件事,本质上是一个“猜字游戏”。模型每写一个字,都要把前面所有写过的字重新看一遍,算一遍,才能决定下一个字该写什么。
每写一个字,AI就得从头到尾跑一次,写100个字,就要把自己写的东西重新消化99遍。学术上,把这个“自己回归自己”的过程,叫做“自回归生成”。
整个过程就是现在的自己在跟上一步的自己较劲,上一步没算完,下一步就动不了。
所以过去几年,业界都在琢磨同一件事,能不能让模型一口气猜一串字?
这个思路,就是DSpark论文中提到的核心机制——投机解码(Speculative Decoding)。
它的运行逻辑是这样的,找一个跑得快但水平一般的模型当草稿,让它先凭感觉一口气猜出后面好几个字,然后把这一串字一次性拿给大模型验证。
大模型扫一眼,前面连续猜对的直接保留,从第一个猜错的地方开始,大模型自己写一个对的,草稿模型再接着往下猜。
这样就可以确保,输出的内容是大模型认可的,而且速度还比一个字一个字猜地要快。
业内普遍认为有两种投机解码。
第一种是“老实人”打法。草稿模型也一个字一个字地猜,猜完一个、看一眼前文、再猜下一个。好处是输出质量更高,坏处是它猜得太慢了,速度跟大模型自己写都差不多了。
第二种是不管三七二十一,刷刷刷一口气把后面所有字全猜出来。虽然速度快,但是猜字时根本不会考虑前面完整的句子,它只看上一个字是什么。
这就导致一开始还好,但是猜字越往后,输出质量就会越低。
论文里把这个现象叫“后缀衰减”:第一个字的正确率还行,第二个大幅下滑,到了第五个第六个基本上就是在瞎猜了。
DSpark的核心思路叫半自回归生成。简单来说,它把上述两种办法给结合在一起了。
第一步,以极快的手速哗哗哗把后面的字全给你猜出来。猜完之后回过头来检查一遍,看看有没有什么语句不通顺、错别字之类地。
第二步,DSpark会给每个字打个“靠谱分”,比如第一个字90分,第二个80分,第三个60分,第四个30分。但是这里有个问题,打完分之后,DSpark就知道哪个字写错了,如果要给它改对,相当于回到了一开始自回归的方法当中,好不容易提高的效率,又送回去了。
所以DSpark提出了一个方法,它会提前测量好大模型在不同批大小下的处理速度,然后每个请求的草稿按靠谱分从高到低排好队。
它先把所有请求里最高分的那一批,拿给大模型验。
这个过程很快,因为量少。然后它问自己:要不要把第二批也加进去?加了之后大模型要多花一点时间,这批字有80%是对的,能多赚几百个正确结果。多花的时间除以多赚的正确字,算出来一个效率值。赚了,加。第三批,60%正确率。以此类推。
根据当前服务器的忙碌程度,不忙的时候,全拿过去,能多猜对一个就多猜对一个。
如果大模型此时很忙,那就只把前几个高分拿过去让大模型验,后面那些大概率错的就别去添乱了,省下时间多服务几个用户。
整个过程,叫做置信度调度验证。
之前有很多加速方案,但它们都有一个共同的毛病,那就是单用户测起来快得不得了,一上高并发就崩。
现在的DeepSeek,一到晚上高峰就卡、就崩。
本质上就是高峰时段用户请求多,GPU的批处理压力极大,但之前MTP-1的投机解码方案会把大量算力浪费在验证那些大概率猜错的token上。
这些token被草稿模型随便猜出来,大模型看了一眼就驳回,但驳回的过程已经消耗了宝贵的GPU周期。
有效吞吐量被严重拉低,请求越积越多,排队越来越长,用户体验就是卡顿甚至加载不出来。
DSpark部署后,这个问题应该会得到缓解。
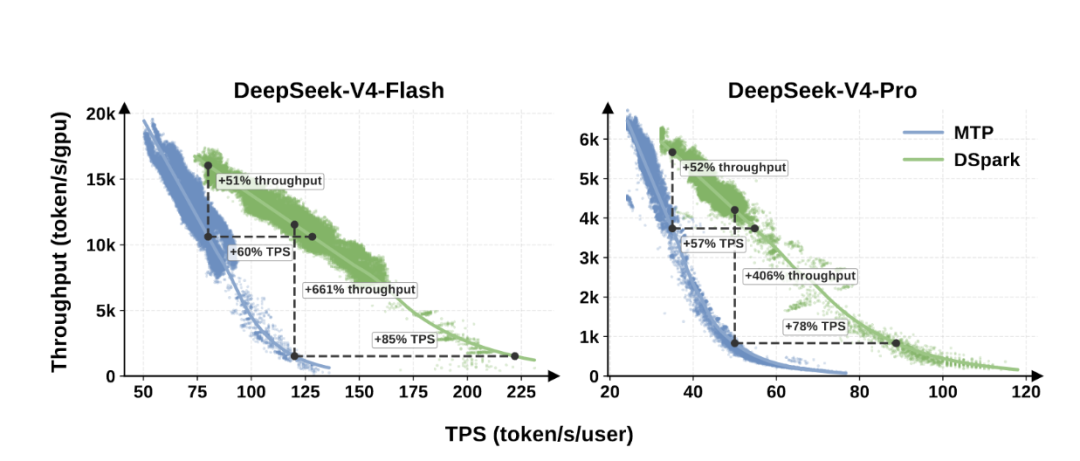
实测数据显示,在严格的低延迟要求下,比如V4-Flash要保证每个用户每秒看到120个字,之前的MTP-1系统基本撑不住多少并发就崩了,而DSpark还能保持6倍以上的吞吐量。
在更常规的中等负载场景下,要求每个用户每秒80个字,DSpark单GPU的总吞吐量从10000 token每秒提升到15100 token每秒,直接涨了51%。

成本打下来多少,
会不会牺牲回答质量?
在AI行业,训练成本是一次性的,推理成本却是永续的。
怎么理解这个问题呢?你训练一个大模型,不管你花了几个亿、几十个亿,花完就花完了。
推理不一样,模型上线之后,用户每问一个问题,GPU就要跑一次,这个成本7×24小时不停,用户越多跑得越多,永远停不下来。
这就意味着,谁能把推理成本打下来,谁就能赚钱。也可以反过来说,模型再强,如果推理成本控制不住,那么模型的规模越大,厂商死得就越快。
同样的GPU数量,DSpark在完全不改变硬件的前提下,可以让每个用户的生成速度快60%到85%。
原来等10秒钟才出来的回复,现在五六秒就出来了。
DeepSeek还给出了一个非常极端的场景。遇到热点事件、大量用户同时涌进来的时候,之前的系统如果扛不住,要么排队排到用户放弃,要么直接崩掉。扩容需要时间,GPU也不是你说加就能立刻加上的。
DSpark靠动态调度,负载一高,自动缩短验证长度,避免占用关键的批处理容量。这样就能在不扩容的情况下扛住流量尖峰。
那么问题又来了,快是快了,DeepSeek会因此而偷工减料?回答质量会不会下降?

答案是零损失。
这是投机解码这个技术路线本身的数学性质决定的。拒绝采样机制从数学上严格保证:大模型最终输出的每一个token,它的概率分布和大模型自己一个字一个字写出来的分布完全一致。所以单从数学验证上来讲,质量不会下降。
DSpark论文原文写到:“the acceptance rule preserves the target distribution exactly, speculative decoding accelerates generation without any quality loss.”接纳规则能够精准完整地保留目标分布,投机解码可在不损失输出质量的前提下加速生成过程。
不仅如此,论文还在数学推理、代码生成、日常对话三个领域做了离线准确率测试,和原模型没有统计显著差异。
线上部署之后,也没有收到回答质量下降的用户反馈。
而且由于草稿模型本身体积非常小,只占总计算量的不到10%,虽然多多少少会影响服务器负载,但是在51%的实测提升面前,这点负载可以忽略不计。
DeepSeek向来以便宜著称,推理成本打下来40%之后,DeepSeek就有了更大的降价空间。
它本来的API定价就已经是行业最低的了,现在成本再降一截,token价格可能也会跟着降。甚至有可能进一步提高免费用户的额度。
更关键的是,这次DeepSeek不光是发了模型权重,还把整个DeepSpec训练框架开源了。
DeepSpec是专门用来训练投机解码草稿模型的统一训练工具箱,也就是说,你可以用这套工具给自己的Qwen3、Gemma等模型训练草稿模型。
等于把整个行业的推理成本基准线又往下拉了一个台阶。

坚持省钱16年
2010年,梁文锋在浙江大学读硕士,他的硕士论文题目叫《基于低成本PTZ摄像机的目标跟踪算法研究》。
这个名字现在看起来非常“梁文锋”。
当时做计算机视觉目标跟踪的实验室,标配是几万块一台的工业相机,精度高、可控性强。梁文锋不买,他用的是几百块钱的普通民用球机。
他的论点是,硬件的差距可以用算法补。通过自研的跟踪算法优化,他把便宜摄像头的跟踪精度做到了接近贵价设备的水平。
16年过去,梁文锋依然执着于用算法给硬件省钱,可以说是相当的不忘初心了。
为什么别的大模型公司都想方设法提升性能,DeepSeek却想要省钱?因为钱是梁文锋自己的。

在DeepSeek完成融资后,外媒爆料称,DeepSeek成立近三年,完全由梁文锋创立的幻方量化用利润养活,并且期间多次拒绝外部投资。
幻方量化2025年平均收益率高达56.55%,全年营收约86亿元,梁文锋个人持股85%,每年分红数十亿元,个人资产据估算在500亿至1000亿元之间。今年启动的首轮超500亿元融资中,梁文锋个人掏了200亿,占总融资额的40%,是最大单一出资方。
外部投资者的钱不直接进 DeepSeek 主体,而是先注入由梁文锋担任普通合伙人的有限合伙企业,外部投资方成为有限合伙人,只有收益权和财务信息查阅权,没有任何投票权,全部股份锁定五年,禁止转让和退出。
在DeepSeek,梁文锋同时扮演投资者、管理者和研究者。
省下来的每一分成本,都是直接装进梁文锋自己的口袋里。
面对“多买100张GPU还是让团队做工程优化”这道题时,大多数人的答案都是前者。快,并且有OpenAI和Anthropic作为开路先锋,花的又不是自己的钱,是投资人的钱,也没什么好心疼的。
梁文锋选后者,因为他比任何人都清楚这张卡要跑多少token才能回本。
三个角色叠在一个人身上,产生了一个AI行业里极其罕见的决策闭环。
研究者提出“可以省”,管理者判断“应该省”,投资者确定“自己买单也愿意省”。没有层级汇报,没有跨部门拉齐。
DSpark就是这条决策链的最新产物。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

