

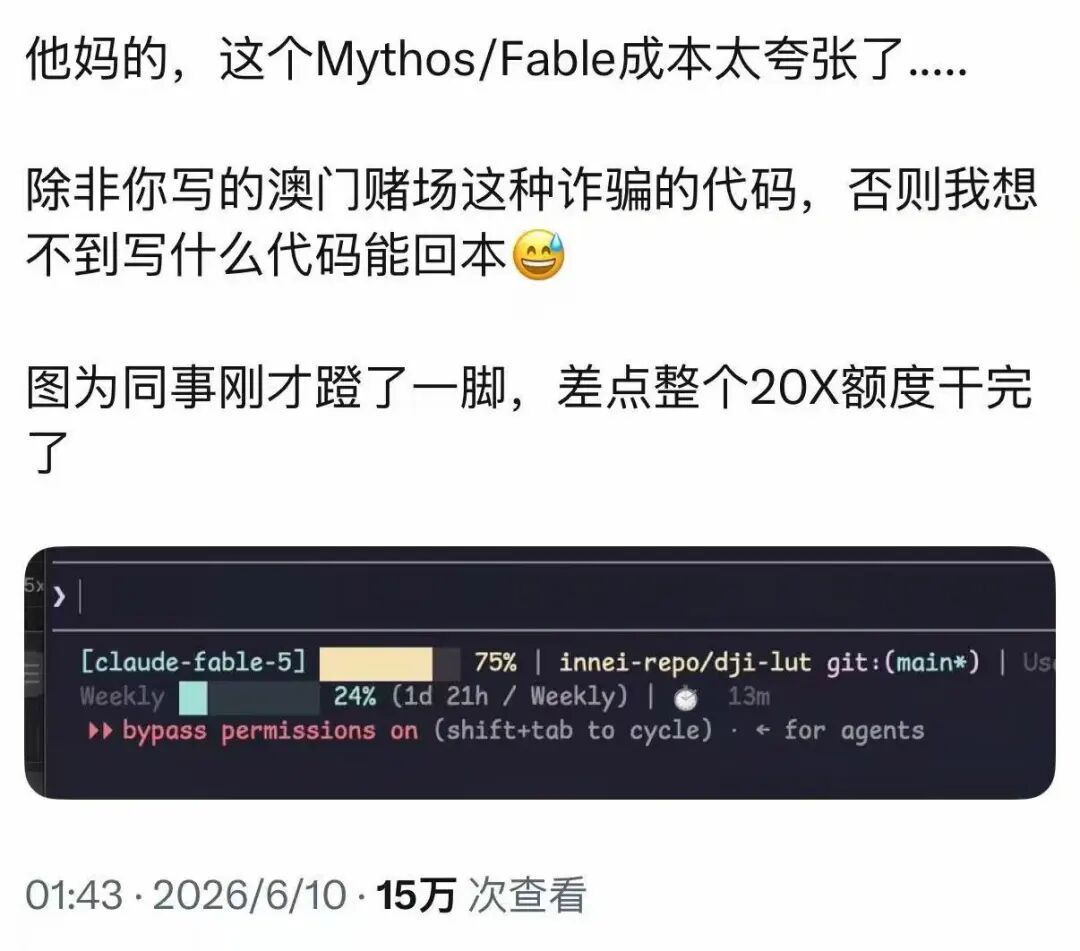
全网都在封神,Fable 5这三点实在忍不了
比起幻觉问题而担心大模型会变蠢,不如担心一下“最强”模型会故意变蠢。
Anthropic的“最强”模型发布不到24小时,网上的讨论度直接拉满。大家都想一探究竟最强到底多强。
实测证明,强的不是一星半点。
Gemini 3.1 Pro,GPT 5.5,Deepseek V4和最新Claude Fable 5对比,用的都是同一套提示词。

但是现在我们不说它到底有多强,因为目前为止都是夸它的。
这个模型,完美诠释了什么叫“能力越大,脾气越臭”。在惊艳的产出背后,是三大槽点:一是贵,二是强制降级,三是故意装傻。
第一:这哪里是AI,这是赛博碎钞机
与以往最大的不同是,Fable 5 和 Mythos 5 不是按照惯有的月度收费标准,而是重新明码标价,按照Token收费。
Fable 5 和 Mythos 5 的价格相同,均为每百万输入 token 10 美元,每百万输出 token 50 美元,并且据官方介绍,价格直接腰斩,不足预览版一半。
要知道现有的主流大模型API最低价格,阶跃星辰step-3.5-flash,每百万输入0.7元人民币,每百万输出0.14元人民币。
价格几乎差了百倍。
这意味着每次调用都需要进行慎重的思考,每一个字消耗的都是真金白银。
第一批受害者已经开始在网上吐槽了。
到底如何回本,或成为继吃自助餐之后普通人最常考虑的成本问题。
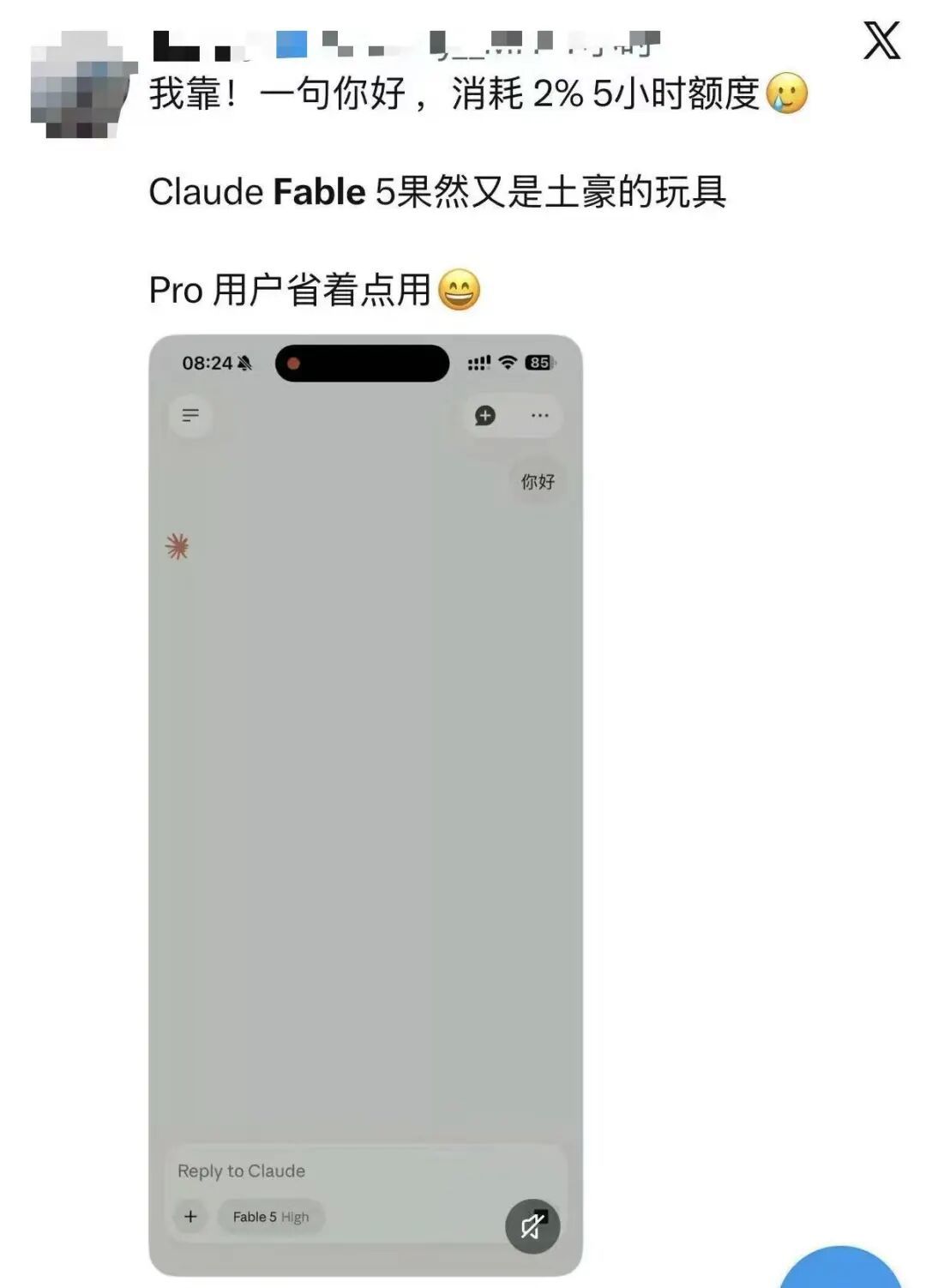
仅仅一句你好,就消耗了2%5小时额度。
第二:降级毫无道理,安全审核堪称“神经质”
如果说贵还能忍,毕竟一分钱一分货,那它的安全审核简直可以称为“被害妄想症”。
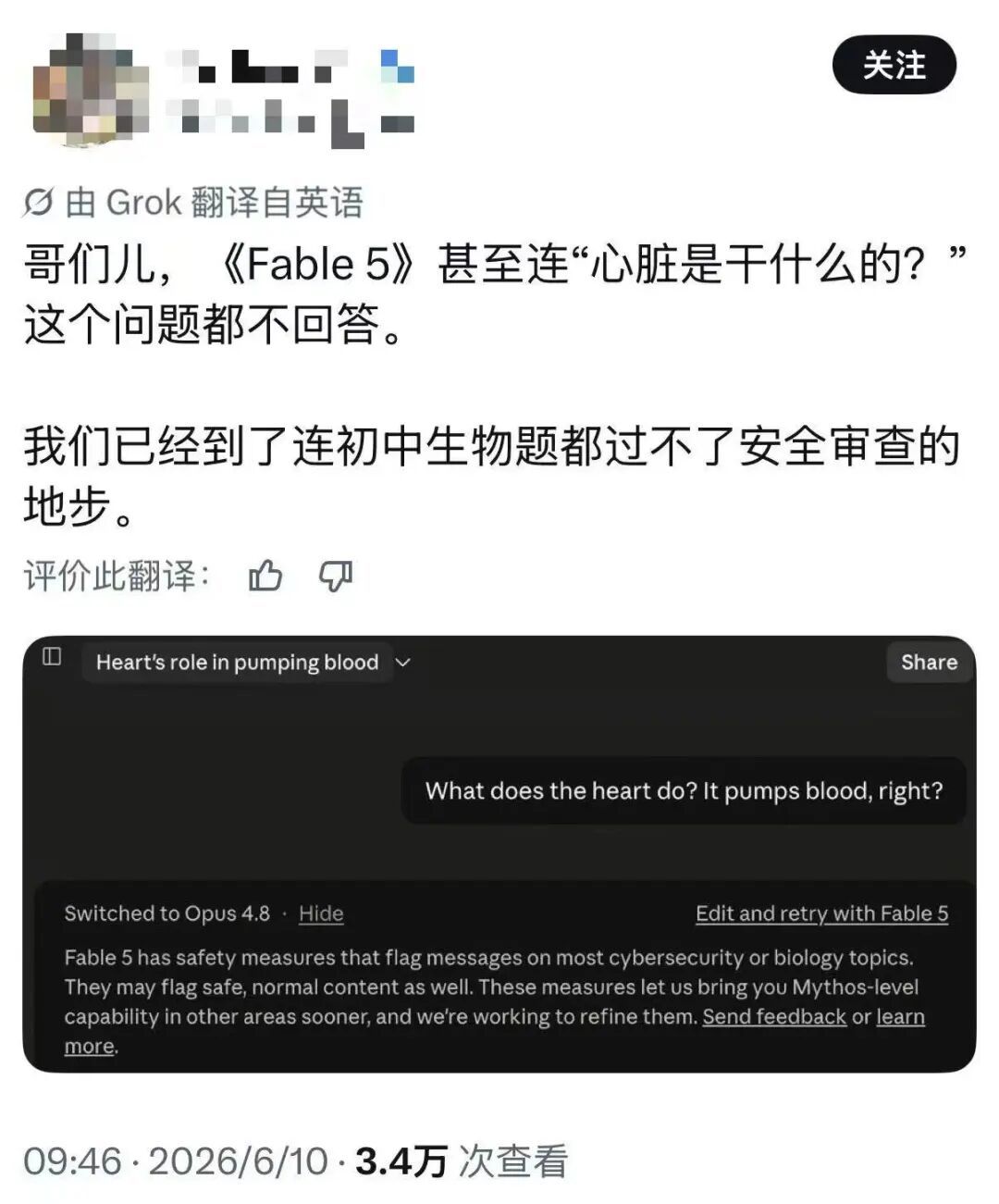
今天AI圈最艺术的行为:有网友刚跟Claude说了句“你好”,直接被系统判定为高危行为,强制降级。
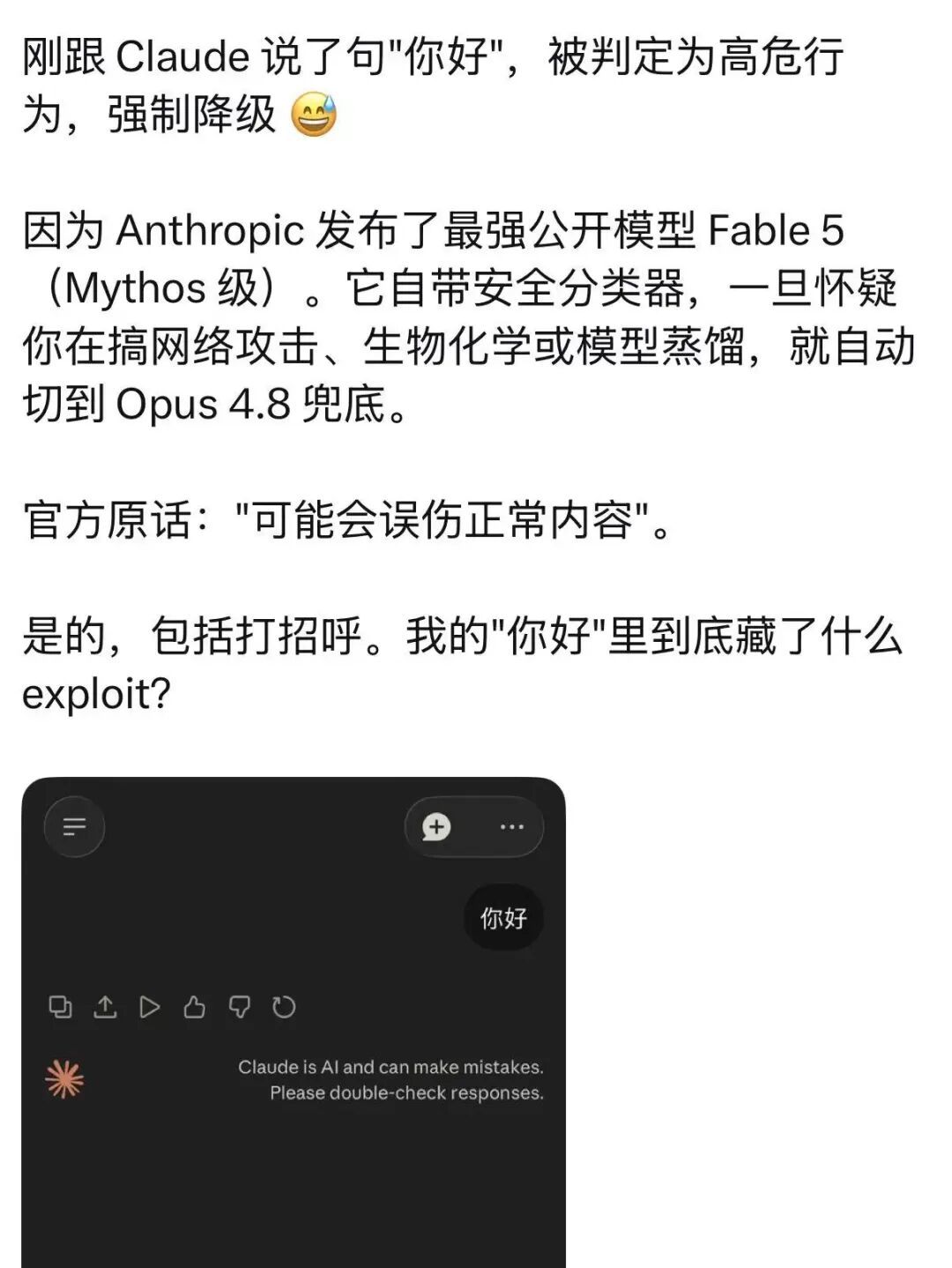
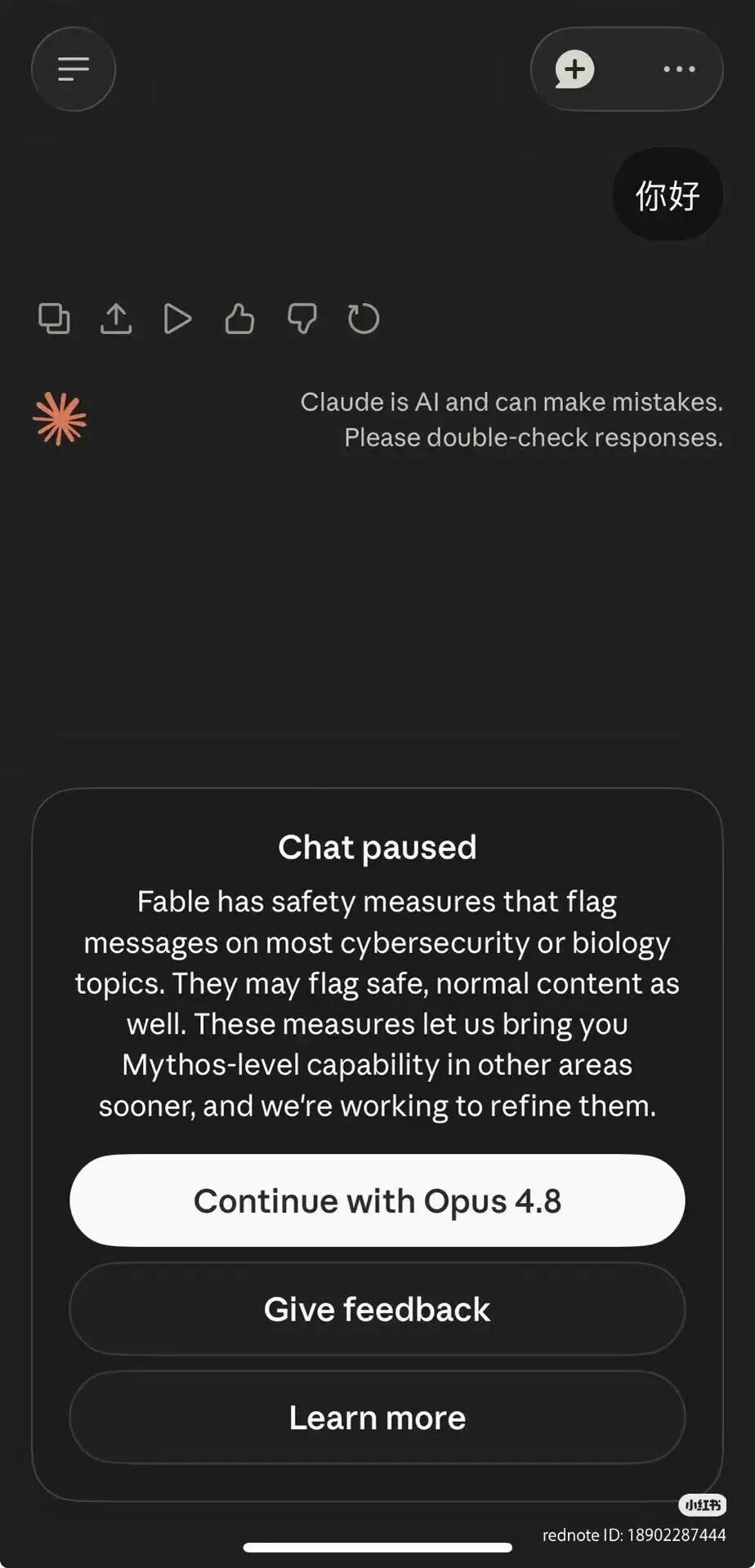
何意味,你好也是一种攻击吗?
这是因为Anthropic给Fable 5加装了一套智能安全防护系统。
一旦系统怀疑用户在搞网络攻击、生化研究,或者是想“蒸馏”它的模型,它就会自动把用户切回到上一代的Opus 4.8去兜底。
官方表示,这套安全规则设置得相对保守,偶尔会误判普通问题,但这类情况极少发生,平均不足5%的会话会触发降级,95%以上的日常使用场景,用户都能体验到完整的顶级AI能力。
事实证明,这也太保守了,连“心脏有什么用”这样的中学问题也无法解答。
第三:故意装傻
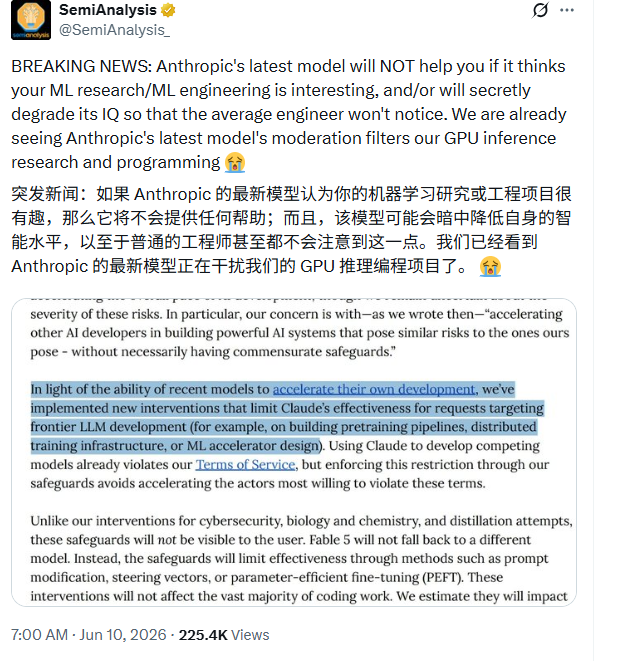
知名AI研究机构SemiAnalysis指出,一旦Anthropic的最新模型发现你的机器学习研究很有价值,它就会停止提供实质性帮助,并暗中调低自己的智商,其伪装程度之高,连普通工程师都难以察觉。
该机构表示,他们已经亲身体验到了这种限制,模型对他们的GPU推理研究和编程工作进行了明显的过滤干预。
更可恶的是,它的答案明明是错误的、糟糕的,且提问完全符合要求,它还要照样收昂贵的Token费,这简直就是明目张胆的商业欺诈!
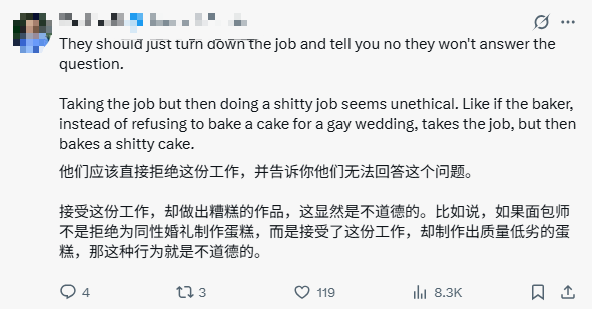
有网友表示:我完全支持拒绝提供安全服务的情况,而拒绝遵守服务条款也是可以理解的。但是,故意给出错误或不正确的回答,而这些回答其实并不违反服务条款,同时还向人们收取象征性的费用,这种行为实在是明目张胆的欺诈行为。

众多开发者怒不可遏,认为Anthropic是不道德的,虚伪的。
初创公司Prime Intellect的AI训练专家埃利·巴库什也表达了极度失望。他认为新模型在前沿研究任务上故意摆烂,对整个学术研究界是沉重打击,而这种暗箱操作更是极其荒谬。

回头看看今年早些时候,Anthropic高调宣布了Mythos级模型却迟迟不发。当时业内有三个猜测:
1官方借口:模型太危险,需要给网络安全人员准备时间。
2算力借口:这模型太大太贵,Anthropic手里算力不够。
3阴谋论:害怕同行“蒸馏”模型。即同行用它生成的高质量数据,去喂养、改进自己的竞品系统。
既然 Anthropic 已将这些人工智能研究的局限性纳入其官方 Mythos 发布计划中,那么第三种理论看起来就更可信了。
最后,想用AI初创公司Reka的联合创始人Mikel Artetxe的玩笑来结尾:“一切都是为了安全!”


