

Holy Sh*t,我的大便被卖给AI了
Reddit上的r/DHExchange板块从来都不缺奇怪的交易。但月初的一个帖子,还是让见多识广的我打了个问号。
「我囤积了一个非常有价值的大型数据库,只是不是你想的那种……15万张粪便图像。」

图片来自小红书@暴打小番茄
(正在吃饭的读者先退出去吧。
发帖人在正文解释,他几年前开发了一款叫PoopCheck的肠胃健康App,通过它积累了超过25000名用户上传的粪便照片,经过标注和分类,形成了规模达15万张的图像数据库。
他现在想卖掉访问权限,称这批数据「极为稀缺」,「对机器学习训练和癌症研究都很有价值」,只是还没想好定价,感觉自己「坐在一堆shi...ny coins上,却找不到买家」。
坐拥金矿的人,把矿场开在你的马桶旁边
PoopCheck创始人在Reddit上并不完全是在吹牛,他确实坐在一座金矿上,尽管这座矿的味道有些冲。
这款App的开发公司叫Soft All Things LLC。404 Media的记者联系了发帖人后,收到了创始人之一「Marco」的邮件回复,表示可以提供样本数据,并询问所需规模和用途。
记者说他需要10000条数据用于AI训练,Marco没有拒绝。数据集分两个档位,一种是AI自动标注的,另一种是人工精标的,精标版更贵。
每张图片都关联着一系列用户报告的数据点,以及对每张图片的人工智能分析结果。
用户报告包括对一系列问题的回答,例如「你上次进食是什么时候」「排便时是否有不适?(排便困难;灼热感;锐痛等)」「花了多长时间?」「气味是否比平时更重?」「过去12小时内是否饮用咖啡或酒精?」
数据还包含人口统计信息,包括年龄段、性别、身高、体重,以及「乳糖不耐受」或「肠易激综合征」等敏感状况。每张图像都通过一个名为「externalIndividualID」的字段与特定用户相关联。

AI分析的数据点包括排便时间、每份粪便的布里斯托尔分级、是否「健康」或「不健康」、粪便的「形状」和「质地」、是否含有血液或粘液、排便量(多、正常或少),以及是否「漂浮」。每个数据点还配有一个「置信度」评分,反映AI对其分析结果的信心程度。
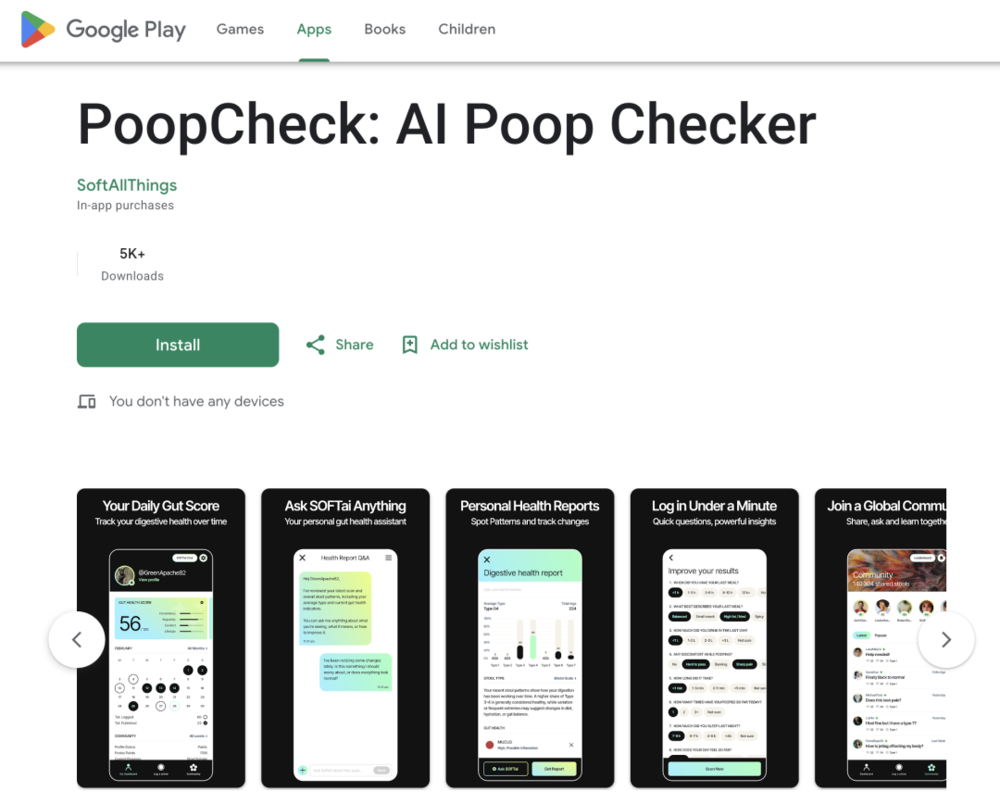
PoopCheck在应用商店的介绍页面写着「隐私第一」「绝不收集数据」。它承诺用先进的AI技术分析你的粪便,给出每日肠道健康评分。应用界面简洁友好,有清晰的图表展示你的排便规律,还有一个名为SOFTie的AI助手随时解答你的肠道问题。
最吸引人的是,用户可以选择分享自己的粪便照片,获得其他用户的评论和建议,还能登上排行榜。截至2026年5月14日,社区里已经有151317张「共享粪便」。帖子标题五花八门,「像橡皮泥一样」「有点担心」「过去三周断断续续这样」。
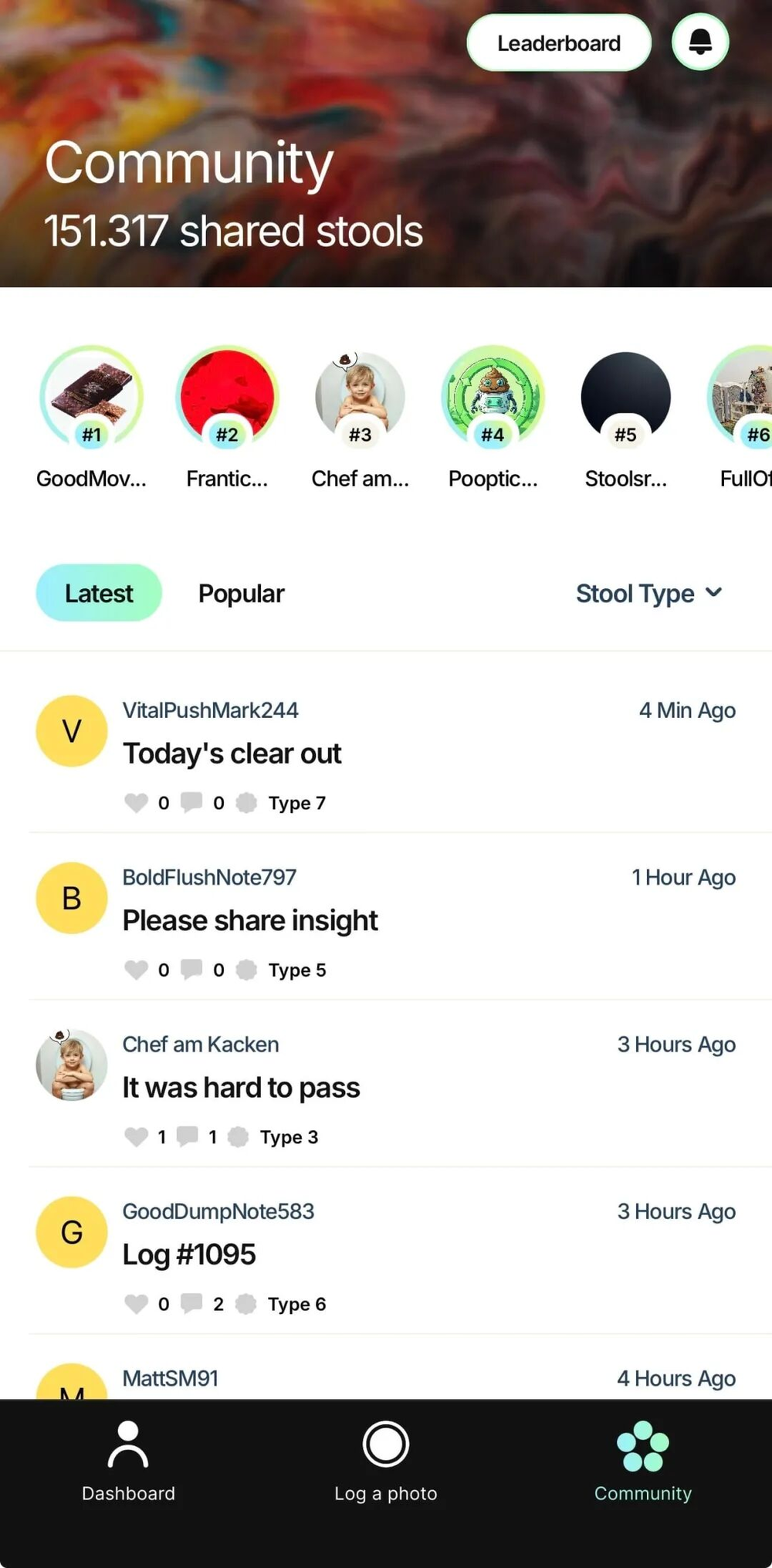
或许没有人会想到,这些在私密的时刻拍下的照片,会被打包成数据库在网上叫卖。
这也让我想到去年卫浴品牌科勒(Kohler)做的一款叫Dekoda的新设备。它将一枚摄像头夹在马桶侧边,借助AI视觉分析排泄物,为用户养成健康习惯提供数据支持。
科勒,你老实说,是不是拿💩图去训练大模型了?
不是第一坨,也不会是最后一坨
如果你以为PoopCheck是一个孤立的奇葩事件,那说明你低估了这个行业的创造力。
Flo是一款被数亿女性用来记录经期、排卵、怀孕的App,曾在隐私政策里承诺不会把用户的健康数据分享给第三方。然而Flo通过内嵌的软件开发工具包(SDK),把用户的记录传输给Facebook、Google的分析部门及多家广告平台。
Flo在《华尔街日报》报道刊出后的当天,立刻停止了向Facebook共享数据。美国FTC于2021年与Flo达成和解,要求其通知受影响用户并接受独立隐私审计。围绕同一事件的集体诉讼此后持续发酵,到2025年,Flo、Google、Flurry三方合计面临5950万美元的和解金额。
在线心理咨询平台BetterHelp收集的是抑郁状态、自杀念头、当前服用的药物等信息,平台在多个页面反复承诺保护用户隐私。
但在2023年,BetterHelp被指控将超过200万用户的敏感健康数据共享给Facebook、Snapchat、Criteo和Pinterest,用于精准广告投放。
该平台还在网站上展示了一个HIPAA合规徽章,暗示自己符合美国医疗数据保护规范,实际上没有任何机构认证过它的合规性。FTC最终要求BetterHelp赔偿780万美元。
有用户在FTC案件评论区写道:「我在心理危机期间注册了这个网站……现在我听说他们卖了我的信息。」
而23andMe让数百万用户把唾液样本邮寄给它,承诺数据只用于健康研究,用户对自己的数据拥有控制权。可公司于2025年申请破产后,基因数据库突然成了清算资产,客户的遗传信息随时可能流向最高出价者。
FTC向法院发出警告,要求任何收购方须遵守原有隐私政策。但在破产法框架下,隐私承诺究竟能被保护多少,答案并不乐观。
数据是新石油,但油井在你肠子里
AI时代对数据的需求是结构性的、无止境的。大模型需要数据,带标注的、来自真实人类的、覆盖边缘场景的高质量数据尤其稀缺,而且稀缺程度随着模型能力天花板的提升在不断加剧。
我想问PoopCheck开发者的是:你确实拥有一批稀缺数据,可这批数据是否经过了真实的知情同意?
知情同意(informed consent)这个概念来自医学伦理,核心在于「知情」必须先于「同意」。用一份没有人读的协议来替代真正的告知,是在制度层面制造一种合法的欺骗。
还有一个容易被忽视的技术问题。即便数据经过了去识别化处理,通过「再识别攻击」(re-identification attack),仍然可以把看似匿名的记录与其他公开数据库交叉比对,从而还原具体个人身份。
有研究显示,只需15个数据点,就可以识别出几乎任何一个美国人。PoopCheck的每条数据记录附带的字段远不止15个,而且根本没有做去识别化处理。

一旦这批数据被买走并用于训练模型,它就几乎无法被真正删除。大型语言模型和其他生成式AI系统可能记忆并再现训练数据中的内容,这一特性意味着,要从已训练的模型中外科手术式地移除某个具体个人的数据,在技术上往往是不可能的,除非从头重新训练整个模型。
美国没有任何综合性的联邦科技公司数据隐私法律,HIPAA只覆盖医疗机构,消费级健康App几乎完全游离在外。FTC在2024年的一份声明中说:「没有哪条法律给AI公司设立豁免权。欺骗性数据收集就是违法,不管它是不是打着AI的旗号。」
一款免费App需要活下去,数据变现是最直接的路径,AI训练数据的需求在这几年急速膨胀,高质量的真实健康数据尤其罕见,于是一个开发者发现自己手里攒了15万张带标注的人类生理数据,打开Reddit,问:这东西值多少钱?
Flo的经期数据卖给了广告商,BetterHelp的抑郁记录流向了Facebook,23andMe的DNA要被拍卖,现在PoopCheck的便便图库挂在数据交易论坛上。
用户的身体信息,在足够大的数据量面前,是可以被货币化的资产,而用户之所以愿意上传这些信息,往往是因为相信对方不会这么做。
那么,普通用户能做什么?答案老生常谈,但还是值得说一遍。
下载任何免费App之前,先搜一下这家公司的商业模式,如果没有清晰的付费路径,想想它靠什么活着。翻一翻服务协议里关于「数据使用」和「第三方许可」的条款,搜关键词「sell」「license」「third party」看看。

