

撕开Claude Code真相:让它好用的98.4%,是工程不是AI

编辑:元宇
当普通人还在钻研「最强提示词咒语」时,硅谷顶级实验室已经把AI基建跑成了生产线。
你还在ChatGPT的聊天框里反复调prompt?
最近,一位X用户发了条推文,开头就是一个惊呼:头部大厂偷偷在用的Claude Code项目模板外泄!
这已经不是写提示词了。这是AI工程基础设施。

整套打法围绕一个文件「CLAUDE.md」展开,而它的核心原则只有三条:
每次Claude犯错→你加一条规则;每次你重复自己→你加一个工作流;每次出bug→你加一道护栏。

这样做,是要把项目经验沉淀成它每次启动都会读取的长期上下文和自动化约束。
整个架构,像是一家AI公司的岗位编制:CLAUDE.md是入职手册,skills/是工作SOP,hooks/是合规部,docs/是公司章程,tools/是后勤组,src/才是真正出活的业务部门。

你不再是在和AI聊天了,而是在构建一个了解你代码仓库的AI。
最疯狂的部分是,你只需要配置一次,Claude就会自动审查代码,并按指令重构、强制执行架构规则、撰写发布说明、从技能中运行工作流、记住过去错误等。
而且它会越用越聪明。
大多数人,都是打开ChatGPT,写提示词,复制粘贴,反复;而在这套打法下,你只需要打开终端,跑一个skill代码已交付。
这等于是在自己的代码库里养了一队AI同事。
这条推文背后,传递的是这个时代正在悄悄翻篇的一个小信号,大多数人可能还没反应过来。
一张不算泄露的「泄露截图」
撕开一个真相
@ai_rohitt晒出来的这张截图,是Anthropic官方文档里公开推荐的Claude Code标准范式。
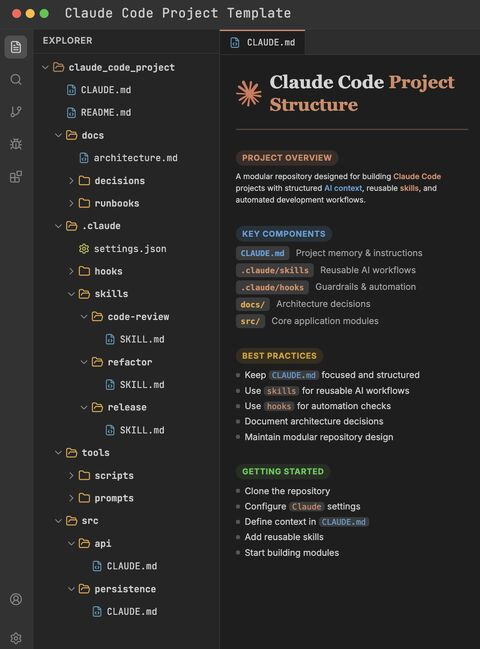
CLAUDE.md是Claude Code在每次会话开始时自动读取的项目记忆文件。
.claude/skills/和.claude/hooks/是官方支持的扩展机制。
这些都是社区已经讨论了几个月的公开做法,并不是什么人偷出来的「内部模板」。
但它之所以能让一些资深开发者主动转发,说明它得到了一些天天用Claude的开发者们的认同。
其中相当一部分人,可能这两天才意识到原来它还能这么用。
而硅谷顶级团队,已经把这件事跑成了生产线。
第一个例子,是OpenAI Frontier团队。
OpenAI官方披露的Frontier团队实验中,一个从空repo起步的内部beta,在约5个月内由Codex生成了约100万行代码和约1500个PR;团队从3人扩展到7人,人工不直接写代码。
带队的Ryan Lopopolo在后续访谈中进一步提到,这套工作流已经接近「0 人工代码、0 人工 review」的极限形态。
他认为与其节省token,不如利用模型极高的并发能力和极低的成本来代替人类有限且昂贵的同步注意力。
第二个例子,是Stripe内部的自动化代码代理系统Minions。
Stripe内部的Minions每周生成并推动超过1300个PR合并,这些代码从头到尾由AI生成,但仍经过人工review。
这里还有一对数据:1.6%vs98.4%,它来自Mohamed bin Zayed AI大学VILA-Lab发表的一篇论文。

https://arxiv.org/pdf/2604.14228
研究者系统性扒了Claude Code v2.1.88版本51.2万行TypeScript源码,给出的结论是:只有1.6%是AI决策逻辑,剩下的98.4%是确定性的工程基础设施。
具体说就是权限网关、上下文管理、工具路由、错误恢复这四类。
这组数字不是说模型只贡献1.6%的能力,而是说明Claude Code作为产品,大量复杂度不在模型本身,而在权限、上下文、工具路由、恢复机制等确定性工程基础设施上。
@ai_rohitt那张图里的CLAUDE.md/skills/hooks结构,就是普通开发者也能搭一套的「入门版基建」,它和OpenAI、Stripe那套生产级架构是同一种范式,只是规模小得多。
CLAUDE.md暴露的秘密
过去3年,所有人都在问「GPT什么时候能更聪明」「Claude什么时候出新版本」。
但真正在生产环境跑通AI编程的团队,他们更关心的可能根本不是这个,而是如何让AI记住自己上次踩过的坑,怎么让AI在动手前先看一眼项目的架构约束,怎么让AI犯错的时候自己被工具挡住。
CLAUDE.md正是这一切的承载体。
Anthropic官方对它的定义只有一句:
一个markdown文件,放在项目根目录,Claude Code在每次会话开始时自动读取。

https://code.claude.com/docs/en/memory
听上去很简单,围绕它展开的那几层结构,才是它真正厉害的部分。
CLAUDE.md是项目大脑。
架构决策、命名约定、测试要求、那些反复踩过的坑,都堆在这里。它是AI每次启动时第一眼看到的「员工手册」。
.claude/skills/是可复用工作流。
Claude Code的创建者Boris Cherny在社区里反复强调一句话:「如果你每天做某件事超过一次,把它变成skill或command。」
一个skill就是一段可执行的方法论。Code review、生成commit message、写发布说明,这些都不该是每天手敲提示词的活,应该是skill调一下就出结果。
.claude/hooks/是自动护栏。
这是最关键的部分。它不依赖AI自己判断,由确定性代码在AI犯错之前就挡住它。这就是为什么敢让AI「无人监督」地跑,因为出错的边界由hooks卡死了。
docs/decisions/是架构决策记录。
让AI不仅知道代码「是什么」,还知道代码「为什么是这样」。
这一项最容易被忽略,但也是AI协作最大的杠杆点。
tools/和src/是执行层。
这套架构真正值得注意的地方,不在于某个开发者搞出了一个漂亮目录,而是越来越多独立团队正在收敛到同一个方向:把模型放进一套由上下文、工具、权限、评估和反馈循环组成的harness里。
GitHub上已经能看到不少类似项目:
rohitg00的awesome-claude-code-toolkit、diet103的claude-code-infrastructure-showcase、affaan-m的everything-claude-code,都在围绕agents、skills、hooks、rules、MCP configs等组件搭建Claude Code的工程化工作环境。
这说明,真正成熟的AI编程工作流,不是只靠一个更强的模型,也不是只靠一条更长的prompt,而是把模型嵌入一套可复用、可约束、可恢复、可审计的工程系统里。
至于具体目录结构,各家实现并不完全相同。
OpenAI实验室的极限实验
2026年2月11日,OpenAI官方博客发了一篇文章:《Harness engineering: leveraging Codex in an agent-first world》。

https://openai.com/index/harness-engineering/
Anthropic围绕这个概念重新调整了Claude Code的架构思路;Martin Fowler的网站把它凝练成一个公式:「Agent=Model+Harness。」
Harness这个词来自马术。它指的是马的整套挽具,缰绳、马嚼子、马鞍、笼头。
一匹马可以跑得很快很有力,但它自己不知道往哪儿走:整套挽具决定了它的方向。
类比到AI编程:模型本身能力很强,但它不知道在你的代码库里该往哪儿走。Harness就是你为它造的方向盘+刹车+导航。
OpenAI Frontier团队那个「100万行0人工」的实验,本质就是把Harness做到极致。
他们的关键工程实践包括以下几条。
层级架构强约束。
从Types到Config到Repo到Service到Runtime到UI,依赖关系单向流动,由linter在CI层强制执行。Agent写出违反层级关系的代码?直接构建失败。
linter错误信息本身是修复指令,这也是最反直觉的细节。
普通项目的lint错误是「violation detected」,给人看的;OpenAI Frontier的lint错误是「use logger.info({event: 'name', ...data}) instead of console.log」,给Agent看的、可以直接读懂并修复的指令。
文档作为单一事实来源。所有架构图、execution plans、设计规范都在仓库内部的docs/目录。Agent不需要任何外部知识库,一切就在repo里。
这套东西效果有多厉害?
模型没有换,但LangChain调整了harness,包括系统提示、工具、中间件和推理模式,最终把Terminal Bench 2.0分数从52.8提到66.5。
你今天就能做的事
是为AI造一个项目大脑
问题回到普通开发者这里:如果范式已经转移,作为一个普通工程师,今天就能做点什么。
第一件事,在你最重要的项目根目录建一个CLAUDE.md。
不需要完美,也不需要很长。写下你团队的架构规则、命名约定、测试要求、那些反复踩过的坑,10分钟能写完一个能用的版本。
下次AI犯错的时候,先不要手动修,而是问自己一句:CLAUDE.md里缺了什么?
第二件事,把每天重复做的事改造成skill。
这里要注意Boris Cherny的金句:「如果你每天做某件事超过一次,把它变成skill或command。」
Code review、生成commit message、写发布说明、修一类重复的bug,这些都该是skill,不该是每天手敲提示词。
第三件事,在容易踩坑的地方加一个hook。
Hook是98.4%里最有杠杆的那部分。它不依赖AI变聪明,它依赖确定性代码做强制检查。这是把人类工程师的判断力翻译成机器可读约束的过程。
这件事的核心不在写代码,而在写规则。
Karpathy今年1月在推特上的那句被广泛转发的话:「我已经从80%手动写代码变成了80%交给Agent写。」
未来五年,工程师的能力曲线正在从「我能写多少行代码」转向「我能为AI设计多严格的工作环境」。
写代码的活儿正在被Agent接管。
但设计那个让Agent能写出好代码的世界,还是人的工作。而且比以前更难、更重要、也更有意思。

