

大模型“降智”真相,找到了




独家抢先看

作者 | 陈骏达
编辑 | 云鹏
智东西4月30日报道,今天,智谱发布了一篇名为《Scaling Pain:超大规模Coding Agent推理实践》的技术报告,披露了GLM-5系列模型在Coding Agent场景下遇到的推理基础设施挑战与对应解法。
报告透露,在每日数亿次Coding Agent调用压力下,部分用户遭遇了GLM-5系列模型乱码、复读和生僻字等异常,这些现象在表面上与长上下文场景下常见的“降智”相似,但智谱并未进行降低模型精度的优化,相关问题主要由高并发、长上下文的极端条件触发。
通过数周排查,智谱锁定了两个底层竞态问题:PD分离架构下的KV Cache异步Abort引发显存写入冲突,以及HiCache加载流水线缺少同步约束导致“数据未就绪即被读取”。针对性修复后,相关异常发生率从约万分之十几降至万分之三以下。
报告还公开了智谱自研的KV Cache分层存储方案LayerSplit,在Context Parallel场景下将单卡KV Cache显存压力大幅降低,实测系统吞吐提升10%至132%,且上下文越长收益越大。
一、本地无法复现,高压才露头:投机采样指标成“照妖镜”
从今年3月起,智谱GLM-5出现了三类异常:乱码、复读、生僻字。排查初期,智谱对线上异常案例做了本地回放,但未能复现,说明大概率不是模型问题。进一步模拟线上高压环境后,在每万次请求中稳定复现3-5次异常。这种“与内容无关、与压力相关的特征”,将问题指向高负载下的推理状态管理。
三类异常中,复读较易检测,乱码和生僻字则难以用正则或模型判别高效覆盖。分析推理日志后,智谱发现投机采样指标可作为重要参考:
投机采样本为性能优化而设计:草稿模型生成draft token,目标模型校验后决定是否接受,并记录spec_accept_length与spec_accept_rate,从而在不改变最终输出分布的前提下提升解码效率。
针对乱码/生僻字问题,智谱发现spec_accept_length极低,draft token几乎全被拒绝,表明KV Cache状态存在显著偏差。
针对复读问题,智谱发现spec_accept_rate偏高,损坏的KV Cache使注意力退化,陷入重复循环。
据此,智谱团队建立了在线监控策略。将投机采样从一项单纯的性能优化技术,拓展为质量监控信号。
二、锁定时序漏洞,两个竞态Bug如何导致输出异常
定位问题后,智谱进一步分析其原因。通过对请求生命周期以及推理引擎中PD分离执行时序的分析,智谱发现该问题源于请求生命周期与KV Cache回收与复用时序之间的不一致,从而引发的KV Cache复用冲突。
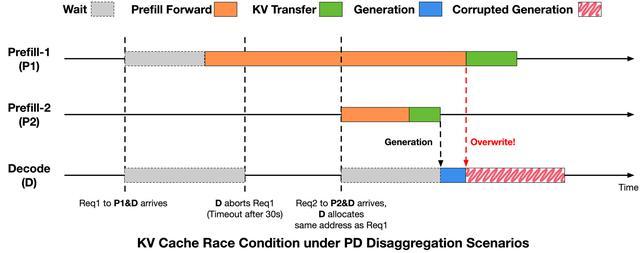
为消除上述问题,智谱在推理引擎中引入了更严格的时序约束,在请求终止与KV Cache写入完成之间建立显式同步关系。
这一问题的具体修复方案是在Decode触发Abort后通知Prefill侧,仅在RDMA未开始或已完成时才允许回收复用,确保KV写入不跨越显存复用边界。修复后,异常发生率从万分之十几降至万分之三以下。
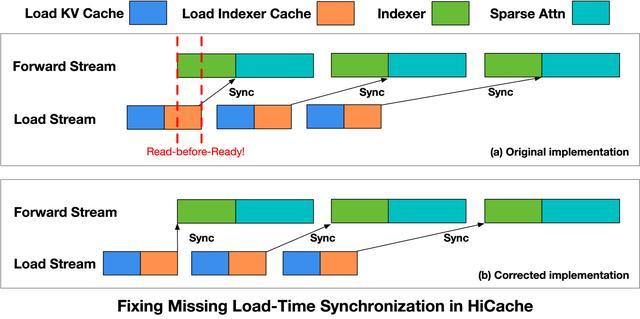
智谱面临的第二个bug与Coding Agent场景的特性有关。Coding Agent场景输入长、前缀复用率高,HiCache成为关键优化。但KV Cache换入与计算重叠执行时,未保证数据加载完成后再使用。
为修复这一问题,智谱在Indexer算子启动前引入同步点,确保数据就绪后才启动计算。修复后,相关问题完全消失,相关修复已提交至SGLang社区。
三、Prefill吞吐成瓶颈,LayerSplit让吞吐最高涨132%
上述两个问题揭示了一个共同的系统瓶颈:在长上下文的Coding Agent服务场景中,Prefill阶段主导了系统性能。修复状态一致性问题后,核心挑战回归瓶颈本身,也就是如何提升Prefill吞吐、降低KV Cache显存占用。为此,智谱团队设计并实现了KV Cache分层存储方案LayerSplit。
Coding Agent负载具有上下文长、Prefix Cache命中率高的特征,使得Context Parallel(CP,上下文并行)成为Prefill节点的主要并行策略。然而,SGLang开源实现中每张GPU保存全部层的KV Cache,冗余存储导致显存容量成为计算资源利用率的瓶颈。
LayerSplit方案的核心思路是:每张GPU仅持有部分层的KV Cache,从而显著降低单卡显存占用。计算时,持有某一层Cache的CP rank会在Attention计算前将其广播给其他rank。
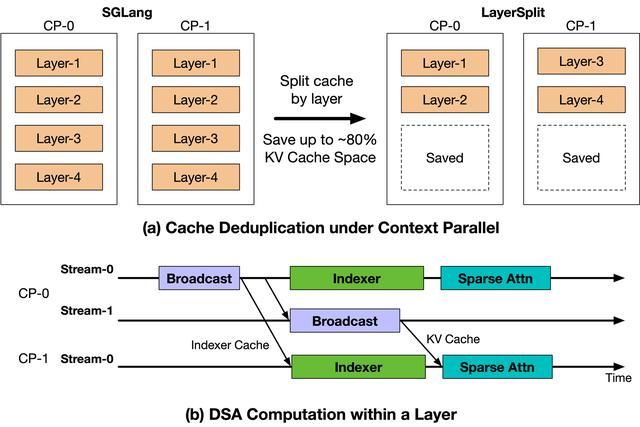
为进一步减少开销,智谱设计了KV Cache广播与Indexer计算的重叠机制,使二者在时间上相互掩盖。整个流程仅额外引入约为KV Cache体量1/8的Indexer Cache广播,通信成本对性能影响可忽略。
实验结果表明,在Cache命中率90%的条件下,请求长度从40k到120k区间内,系统吞吐量提升幅度在10%至132%之间,且上下文越长收益越显著。
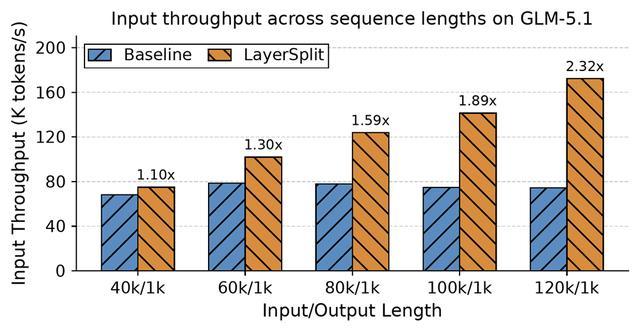
该优化从架构层面缓解了Prefill侧的显存瓶颈,与此前两项BugFix共同构成了一套完整的推理基础设施优化方案,提升了智谱GLM-5在Coding Agent场景下的服务能力。
结语:输出质量成高并发长上下文场景新痛点
高并发长上下文场景下,推理基础设施的挑战已不止于吞吐和延迟,输出质量同样不可忽视。智谱此次公开的技术细节,从异常识别方法、两个竞态Bug的定位与修复,到LayerSplit显存优化,构成了一套相对完整的排查与优化链路。
对于同样在大规模部署推理服务的团队而言,这份报告在故障复现、指标选型、架构层面的时序一致性等方面提供了可参考的实践经验。智谱将这些经验公开分享,客观上为社区填补了部分长上下文推理场景下的工程资料空白。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

