

DeepSeek-V4对普通人到底意味着什么?

2026年4月24日,备受期待的DeepSeek-V4终于发布了。
没有特别盛大的发布会,没有几个人出来直播,没有倒计时预热,也没有大规模媒体采访。
用户群发个通知,官网更新,App上线,API同步更新,开源模型挂到HuggingFace上。

整个AI圈随后开始刷屏,大家都在讲这件事。
模型参数是多少,API价格是多少,跑分怎么样,上下文长度是多少;
到底有没有适配国产卡,和GPT、Claude、Gemini比到底是什么水平。
这些信息当然都重要。
但我没有第一时间写。
不是因为这件事不重要。
恰恰相反,是因为我觉得它太重要了。
如果只是跟着写一篇“DeepSeek-V4发布了,参数如下,价格如下,跑分如下”的文章,当然也能讲清楚一部分事实,但我觉得这会把这件事写小。
参数只能解释DeepSeek这次发了什么,但它解释不了这件事到底意味着什么。
因为当天有一位记者朋友给我打电话,问我怎么看DeepSeek-V4。
我们聊了一会儿。
聊完之后,我更确定,这篇文章应该写,但不能写成一篇快讯。
因为DeepSeek-V4真正值得看的,不是它某一项跑分赢了谁,也不是它终于支持了100万Token上下文,而是它把几个更大的问题同时放到了台面上:
强模型能不能更便宜?
开源模型还能不能追上闭源模型?
国产算力能不能承接前沿模型?
普通人未来能不能用得起强AI?
以及,如果未来每个人每天都要和模型打交道,我们有没有机会不被少数闭源巨头完全卡住入口?
今天,我想用普通人能理解的方式,讲讲DeepSeek-V4对我们这些普通人来说意味着什么?
PART.01
这次到底发了什么?
DeepSeek-V4这次不是只发了一个模型,而是同时放出了DeepSeek-V4-Pro和DeepSeek-V4-Flash。
Pro是旗舰模型,1.6T总参数,49B激活参数。
Flash更轻,284B总参数,13B激活参数。
两个模型都支持100万Token上下文。

如果只看这些数字,很容易把它理解成一次常规升级:
参数更大,上下文更长,能力更强。
但这里真正值得看的,不只是参数本身,而是DeepSeek为什么要同时做Pro和Flash。
Pro很明显是用来打高难任务的。
复杂推理、代码、Agent、长上下文分析,这些任务需要更强的模型能力,也能接受更高的调用成本。
Flash则更像日常入口。
它没有Pro那么重,但价格低很多,更适合高频使用。
普通问答、基础推理、日常办公、产品里的大规模调用,都更适合交给Flash。
这和过去很多人理解的大模型不太一样。
以前大家总习惯问:哪个模型最强?
但真正进入应用之后,问题会变成:什么任务该用什么模型?
不是所有场景都需要最贵的模型。
就像不是所有出行都需要坐头等舱,也不是所有文件都需要请最强律师看。
很多日常任务需要的是够好、够快、够便宜;
少数高难任务,才需要调用最强能力。
所以DeepSeek-V4这次真正有意思的地方,不是单纯做了一个更强的Pro,而是同时给出了一个更便宜的Flash。
Pro负责攻坚,Flash负责铺开。
一个解决上限,一个解决普及。
如果未来强AI要真正进入普通人的软件、工作流和日常生活,它就不能只有一个最强模型。
它必须有便宜入口,也必须有高端能力。
DeepSeek-V4这次的Pro和Flash,正是在往这个方向走。
这件事比跑分刷到了多高更重要。
PART.02
V4很强,但不是神话
当然DeepSeek-V4确实很强。
官方技术报告里,它直接拿自己和ClaudeOpus4.6、GPT5.4、Gemini3.1Pro这些最顶尖闭源模型的高阶版本做对比。
作为一个中国开源模型,敢把对手放到这个级别,本身就很说明问题。
从报告里的结果看,DeepSeek-V4-Pro-Max在知识、推理、代码、Agent和长上下文任务里都已经进入非常靠前的位置。
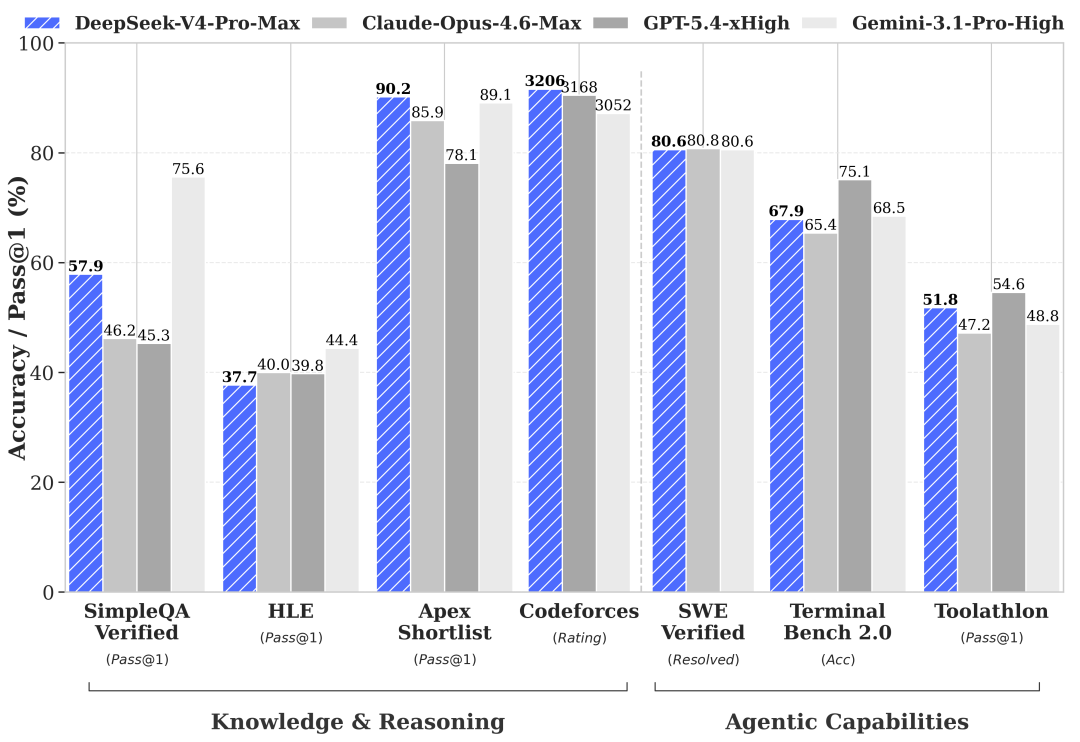
尤其是代码、推理、长上下文和Agent相关场景,是它这次最值得关注的部分。
但它不是神话。
这个也要说清楚。
DeepSeek官方报告写得也比较克制。
在一些知识任务上,它仍然落后最顶级的闭源模型。

在推理任务上,它仍然略低于GPT5.4和Gemini3.1Pro,大概落后当前最前沿模型3到6个月;
在Agent任务上,它和KimiK2.6、GLM5.1这些开源模型大体处在一个梯队,但还是略弱于最顶级闭源模型。
我这几天也进行了实际测试和看了一些朋友反馈。
我的感受是,有些任务表现很好,尤其是长上下文、代码、推理和Agent相关任务。
但在一些实际使用里,它也确实没有外界期待中那么夸张。
这很正常。
DeepSeek-V4被期待得太久了。
过去半年,关于它跳票、关于DeepSeek是不是被超越了、关于梁文锋到底在干什么的讨论,已经来来回回跑了好几轮。
期待一旦被拉得太满,任何模型发出来都会被放在显微镜下看。
所以我不想把DeepSeek-V4写成一次完美发布。
它不是完美发布。
但它依然非常重要。
它重要的地方,不是它已经打穿所有闭源模型,而是它证明了一件事:
开源模型仍然可以进入全球最前沿模型的牌桌,而且不是靠情绪、靠期待,是靠真实能力、工程效率和成本结构。
这已经很难了。
PART.03
技术报告里,真正有意思的几个点
很多人看到DeepSeek-V4,第一反应会是100万token上下文。
这个当然是亮点,但我反而觉得,它不是这次最核心的意义。
因为1M上下文并不是第一次在开源模型里出现,单纯把上下文拉长,也不等于真正解决了真实场景面临的问题。
真正值得看的,是DeepSeek-V4为了让长上下文、深度推理和Agent任务跑起来,在底层做了哪些工程选择。
这次技术报告里有很多名词。
普通人不需要全都理解,真正值得记住的,大概有四个:
CSA/HCA、KVcache、FP4和Muon。
我们一个一个来理解:
第一个是CSA/HCA,也就是新的混合注意力机制。
CSA/HCA做的事情,可以简单理解成:
模型不再每次都把整座图书馆搬进脑子里,而是先把内容压缩、索引、筛选,再决定当前最需要看哪一部分。
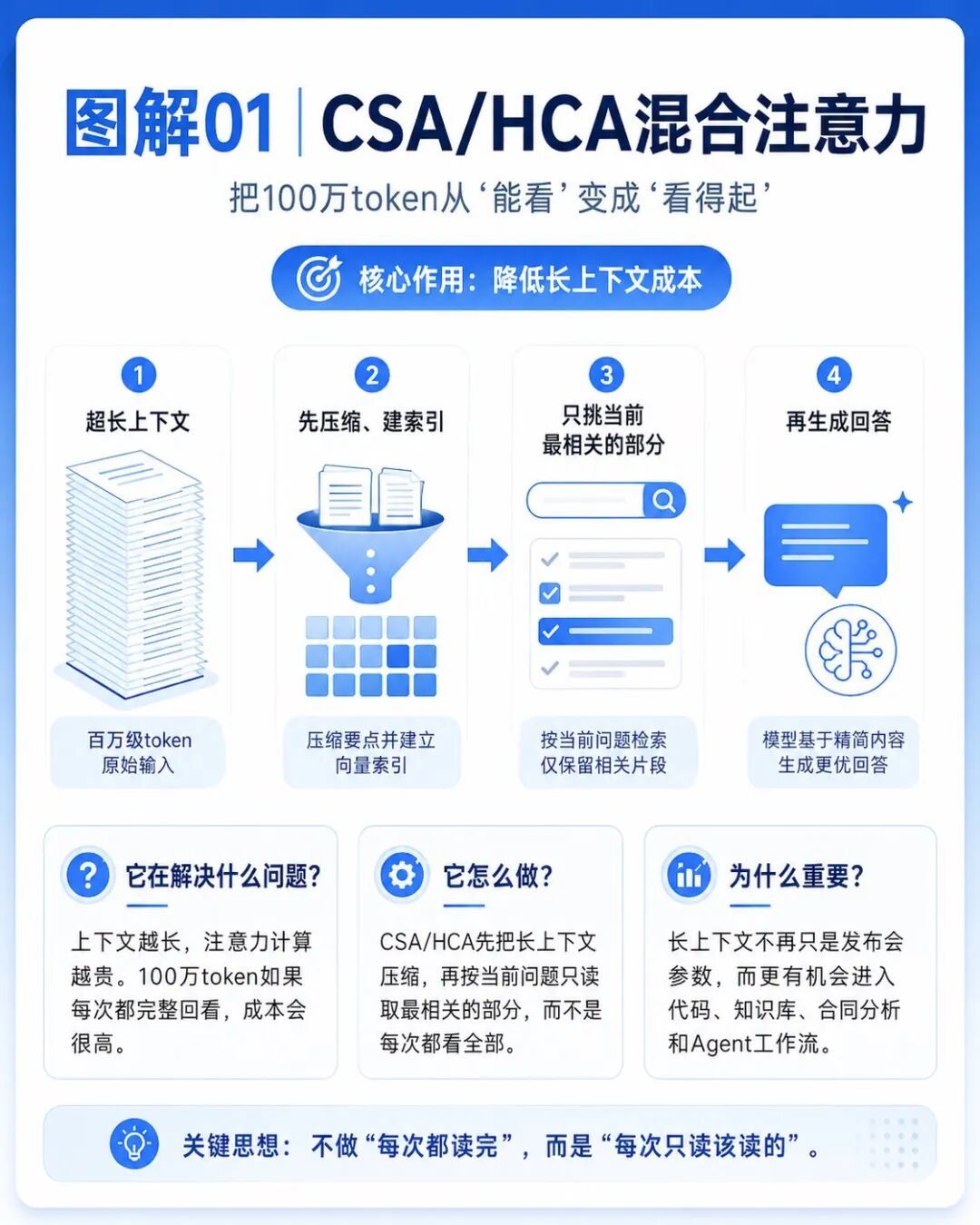
这套机制解决的是长上下文成本问题。
模型处理几十万、上百万Token时,如果每次都完整回头看一遍,成本会非常高。
所以它不是为了炫耀100万Token上下文,而是为了让长上下文真的用得起。
第二个是KVcache。
KVcache可以理解成模型的上下文缓存。
模型处理过一段内容之后,可以把一部分中间结果缓存下来,后面继续使用时,不必每次都从头计算。
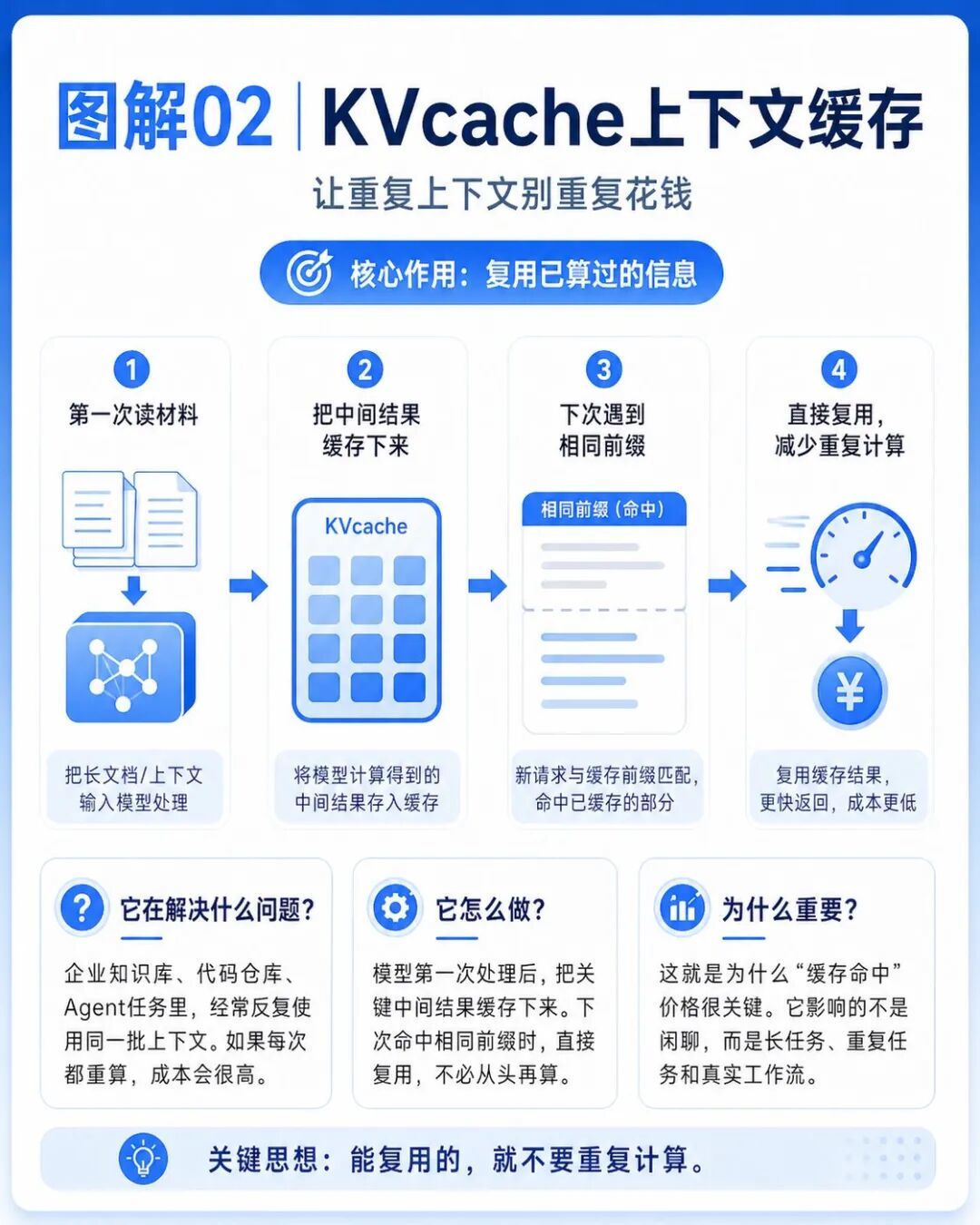
这对真实应用非常重要。
它降的不是闲聊成本,而是长任务、重复任务和真实工作流的成本。
第三个是FP4。
FP4是一种更低精度的计算和存储方式。
普通人可以理解成:在不明显损失能力的前提下,用更省空间、更省算力的方式表示模型里的部分数字。
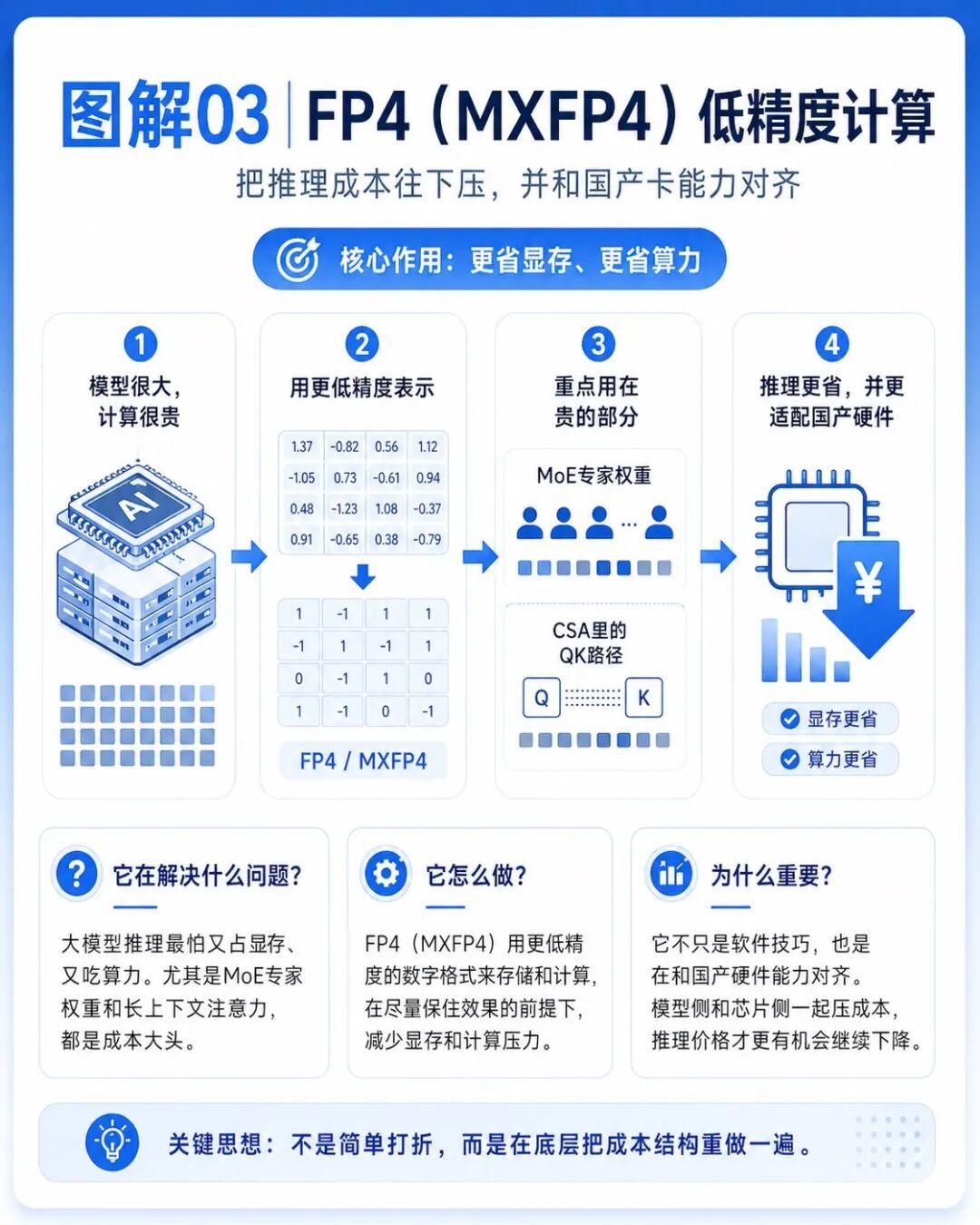
这个点看起来很小,但其实很重要。
DeepSeek-V4技术报告里写到的是FP4(MXFP4)量化,它不是孤立的软件技巧。
昇腾950PR这一代国产推理卡,也开始明确支持FP4/MXFP4这类低精度格式。
这意味着DeepSeek-V4的模型设计,和国产算力的硬件能力是原始适配的。
模型侧把计算压到FP4,硬件侧开始支持FP4,二者合在一起,才有可能让未来推理价格继续往下走。
第四个是Muon。
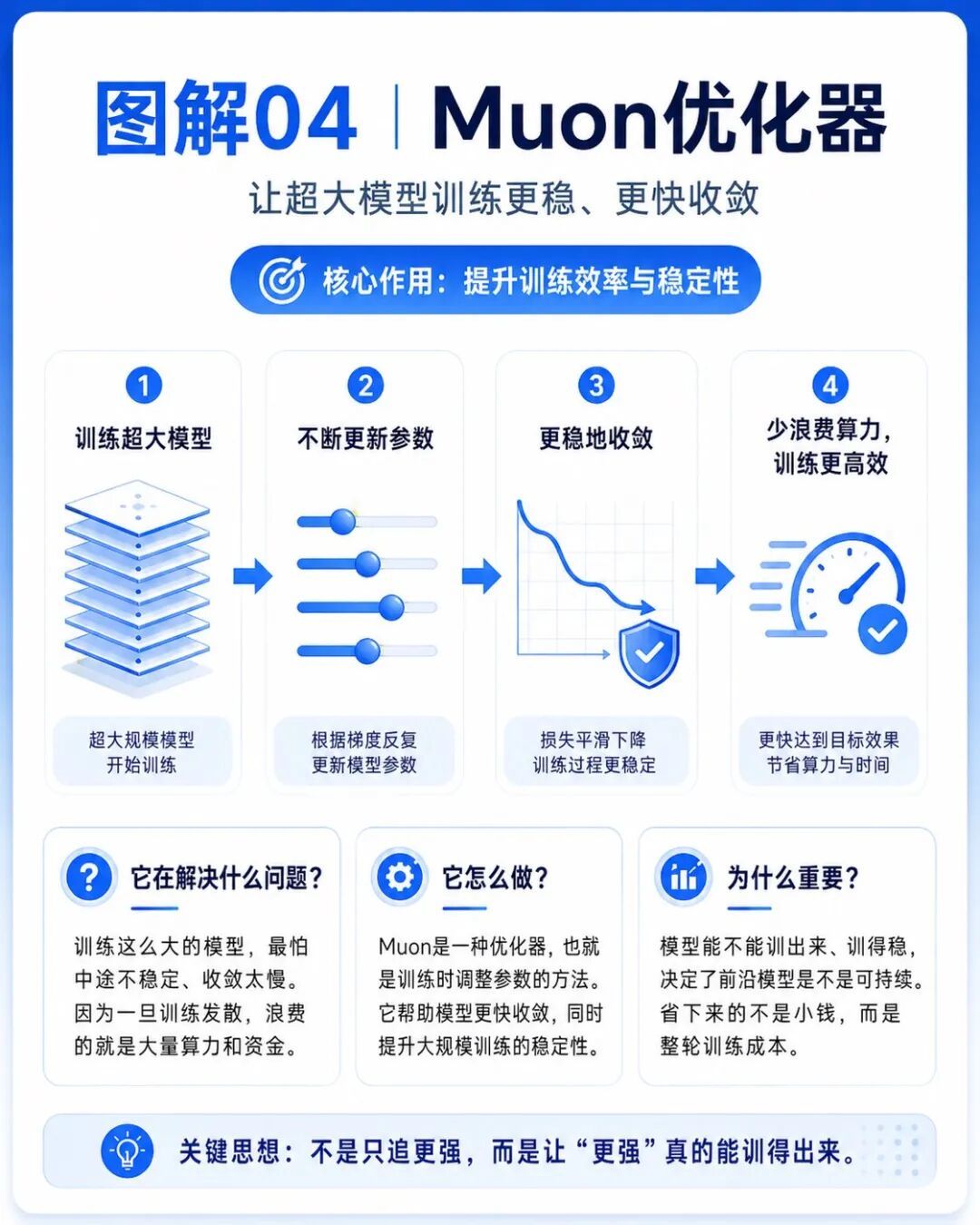
Muon是这次引入的优化器,它来自于另一个国产大模型公司月之暗面开源的项目。
它可以理解成训练模型时用来调整参数的方法。
训练这么大的模型,最怕的不是慢,而是不稳定。
因为一旦训练中途不稳定,浪费的不是一点时间,而是大量算力和资金。
Muon的意义,就是让模型训练更快收敛、更稳定,减少大规模训练里的浪费。
PART.04
不只在论文里省成本
技术报告里讲的是模型怎么做,价格表里看到的是这些选择有没有真的落到外面。
DeepSeek-V4刚发布时,很多人看到V4-Pro的价格,会觉得它并不便宜。
这个判断没错。
Pro本来就是旗舰模型,不是给所有普通任务随便调用的低价版本。
最早的官方图里,Pro缓存命中输入是1元/百万token,缓存未命中输入是12元/百万token,输出是24元/百万token。
这个价格并不低。
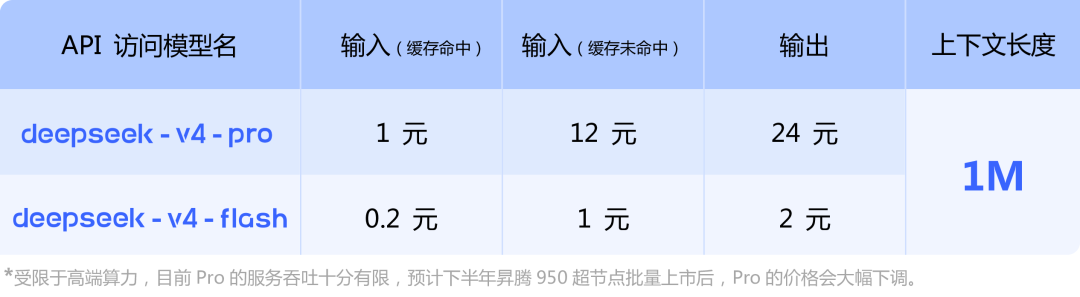
真正便宜的是Flash。
Flash缓存命中输入是0.2元/百万token,缓存未命中输入是1元/百万token,输出是2元/百万token。
所以不能说DeepSeek-V4一发布就把最高端能力打成白菜价。
Pro依然是旗舰模型,真正承担普惠入口的,是Flash。
但过去几天,DeepSeek很快又调整了价格。
现在官网显示,V4-Pro目前开启了2.5折优惠。
缓存命中输入是0.025元/百万token,缓存未命中输入是3元/百万token,输出是6元/百万token。
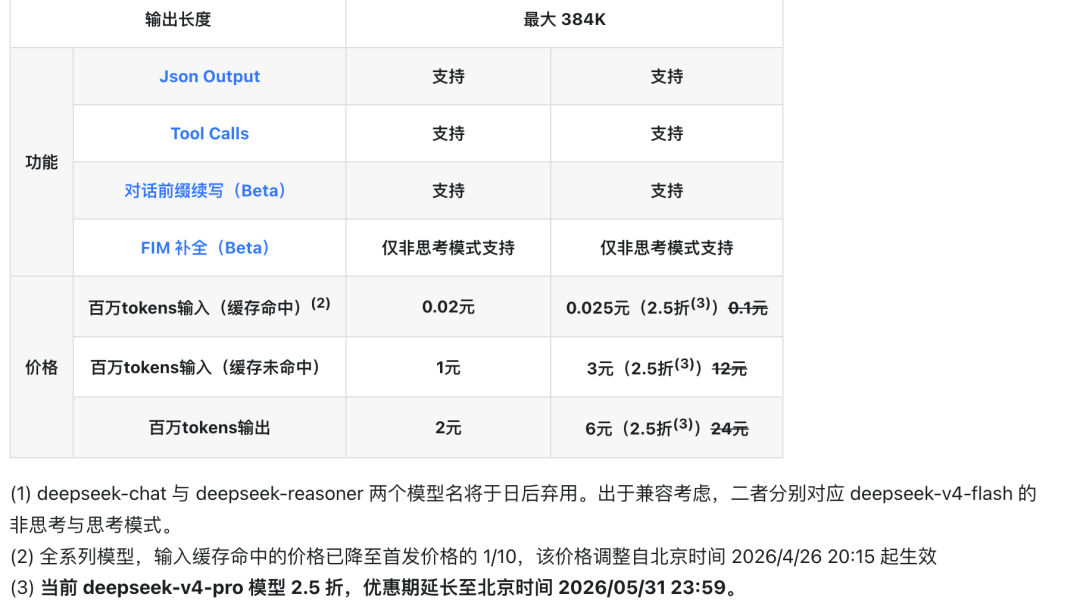
这个2.5折优惠期持续到北京时间2026年5月31日23:59。
但这些数字里,最值得看的不是Pro或者Flash的价格,而是缓存命中输入价格。
全系列模型的输入缓存命中价格,已经降到首发价格的1/10。
这个调整从北京时间2026年4月26日20:15起生效,目前官网没有写明确结束时间。
这不是普通打折。
普通打折解决的是“这几天便宜一点”。
缓存命中降价解决的是“真实工作流能不能长期跑起来”。
因为真正的AI应用,大部分都不是一次性问答。
企业知识库、代码仓库、多文档分析、Agent工作流,都会反复使用相同的上下文,反复读取同一批材料,反复在同一个任务空间里推理。
这些场景最吃缓存。
缓存越便宜,长任务越便宜。
长任务越便宜,AI才越有机会从演示Demo变成日常工作的一部分。
PART.05
便宜模型不应该等于低端模型
为什么这件事对普通人重要?
因为强模型真正进入日常,靠的不是一次演示有多惊艳,而是普通人和开发者敢不敢高频使用。
前段时间那波“龙虾热”,其实已经把这个问题暴露得很清楚。
很多人跟风把国际顶尖模型接进自己的OpenClaw,一开始都很兴奋,效果确实好,能力也确实强。
但很快大家就发现另一个问题:账单太贵了。

前面我们也讲过了,一个Agent任务跑起来,不是简单问一句答一句。
如果缓存没有命中,或者每一步都要重新计算,token消耗会非常快。
所以强模型落地时最现实的问题,不是它能不能回答得更好,而是你敢不敢让它一直跑。
如果每一次调用都要心里算账,如果一个工作流跑几轮就开始担心费用,如果开发者把模型接进产品后发现用户多用几次就亏钱,那这个模型再强,也很难成为日常工具。
这也是为什么“便宜模型”不能被轻视。
但便宜不应该等于低端。
在AI时代,便宜意味着更多人能用,更多开发者能接,更多中小公司能试,更多普通场景能跑起来。
未来模型很可能会像搜索、地图、手机、水电一样,成为每天都要接触的基础能力。
如果真是这样,模型价格就不只是商业定价问题,而是智能使用权的问题。
谁能长期、稳定、低成本地接入强模型,谁就会有更好的学习、工作、创作和组织能力。
谁只能用弱模型、限额模型、广告版模型,或者每次使用都要担心账单,就会天然处在另一个位置。
所以便宜模型不应该是低端模型的代名词。
它是普通人进入AI时代的入口。
PART.06
开源的最终是议价权
但问题在于,便宜不能只靠某个模型的一次打折,也不能只靠某家公司短期补贴。
如果未来强AI真的变成基础设施,那么它的价格能不能长期下降,普通人和开发者有没有选择,最终取决于市场里有没有足够多的竞争者。
这就是开源模型、开放权重、本地部署和低价API的重要性。
它们不是技术爱好者的玩具,也不是理想主义装饰,而是一种现实的议价权。
如果世界上只有少数闭源模型最强,大家当然也可以用。
你可以调用API,可以付订阅费,可以把它接进自己的产品里。
但这种使用是被动的。
你可以调用,但不能拥有。
你可以付费,但不能决定价格。
你可以接入,但需要接受对方的商业策略、政策边界、供应限制和生态规则。

闭源模型当然有它的价值。
OpenAI、Anthropic、Google这些公司会继续把模型能力往上推,很多最前沿的能力也确实会先出现在闭源系统里。
这不是问题。
真正的问题是,如果未来AI世界只剩下这些闭源入口。
强智能就会变成少数公司定义价格、规则和能力边界的基础设施。
而一旦它变成基础工具,谁来定价、谁来提供、谁能部署、谁能修改,就不再只是商业问题。
这也是中国这一批开源模型公司的意义。
DeepSeek、Qwen、Kimi、GLM这些模型,不一定每一项都比最强闭源模型更强。
事实上,在很多最前沿任务上,闭源模型仍然领先。
但它们提供了另一条路线:更开放、更低价、更可部署,也更适合形成竞争。
过去在搜索、操作系统、移动生态里,人类已经经历过很多次类似的事情。
一个入口一旦被少数公司控制,后来者就只能在它们的规则里做生意。
这通常会带来垄断和剥削。
AI不应该再简单重复这条路。
所以开源不是情怀,低价也不是慈善。
它们的意义,是不断把强AI从少数人的高级服务里释放出来,让更多人真的用得起、用得上、用得久。
这才是DeepSeek-V4更大的意义之一。
它不是只在发布一个模型。
它是在告诉市场:
强AI不应该只有一种入口,也不应该只由少数公司来定价。
PART.07
最后,梁文锋到底在做什么
所以回头看,梁文锋为什么要持续做开源DeepSeek这件事?
我觉得这不是一个简单的商业选择。
从纯商业角度看,做前沿模型本来就很重。
训练重,推理重,工程重,成本重,舆论也重。
更不用说,DeepSeek还在持续开源、持续降价、持续做国产算力适配。
这不是一条轻松的路,也不是一个适合赚快钱的方向。
但这件事总要有人做。
DeepSeek-V4不是一次完美发布。
它还是preview版本,世界知识和最前沿闭源模型仍然有差距,超长上下文也不是魔法,国产算力从适配到大规模稳定生产还需要继续爬坡。
但它至少说明,DeepSeek还在沿着一条很难的路往前走:
让强模型变得更便宜、更开放、更可部署。
这件事对普通人重要,因为未来模型可能会像水、电、搜索、手机一样,成为每天都要接触的基础能力。
这件事对中国重要,因为如果没有自己的强模型、自己的算力适配和自己的低价供给,我们就只能在别人的智能基础设施上做应用。
这件事对世界也重要,因为如果没有开源模型和低价模型持续竞争,最强智能就会越来越像一种昂贵入口,价格、规则和能力边界都由少数公司决定。
所以DeepSeek-V4真正重要的,不是它让AI第一次变强。
AI早就变强了。
它真正重要的是,它继续把强AI往更便宜、更开放、更可部署的方向推。
未来AI竞争,不只是“谁的模型更强”。
而是谁能让更多人用得起强模型。
谁能让强模型不只属于少数公司和少数人。
谁能在未来智能基础设施里,给普通人、开发者和一个国家留下位置。
这才是DeepSeek-V4我真正觉得值得写的地方。

