

蚂蚁集团百灵大模型Ling-2.6-flash发布




独家抢先看
IT之家 4 月 22 日消息,蚂蚁集团旗下的百灵大模型今日宣布,推出一款总参数量 104B、激活参数 7.4B的 Instruct 模型Ling-2.6-flash。
一周前,代号为 Elephant Alpha 的匿名模型登陆 OpenRouter。上线以来,其调用量持续增长,连续多日位列 Trending 榜首,日均 tokens 调用量达 100B 级别。百灵大模型今日宣布 Elephant Alpha 正是百灵模型 Ling-2.6-flash 的匿名测试版本。
官方表示,面对持续攀升的 Token 压力,Ling-2.6-flash 选择了一条不同的技术路径:不是单纯依赖更长输出换取更高分数,而是围绕推理效率、Token 效率与 Agent 场景表现进行系统性优化,在保持竞争力智能水平的同时,尽可能做到更快、更省和更适合真实业务场景。
Ling-2.6-flash 的核心能力体现在三个方面:
混合线性架构,释放推理效率:通过引入混合线性架构,模型从底层优化计算效率,在 4 卡 H20 条件下推理速度最快可达到340 tokens/s,Prefill 吞吐达到 Nemotron-3-Super 的2.2 倍
Token 效率优化,提升智效比:在训练过程中对 Token 效率进行了针对性校准,力求以更精简的输出完成既定目标。在 Artificial Analysis 的完整评测中,Ling-2.6-flash 仅消耗15M tokens,约为 Nemotron-3-Super 等模型的1/10
面向 Agent 场景进行定向增强:针对当前需求最旺盛的 Agent 应用,在工具调用、多步规划与任务执行能力上持续打磨,使模型在 BFCL-V4、TAU2-bench、SWE-bench Verified、Claw-Eval、PinchBench 等评测中,即使面对激活参数更大的模型,依然能够取得相近甚至 SOTA 级别的表现
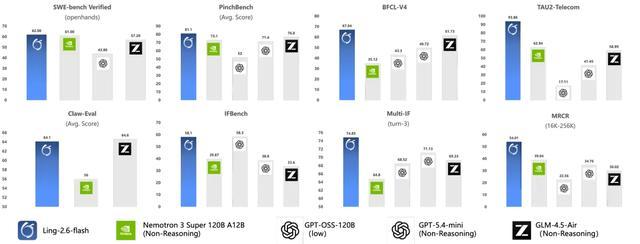
Ling-2.6-flash 在 Agent 相关基准上达到同尺寸 SOTA 水平
为方便更多开发者快速体验 Ling-2.6-flash,百灵大模型将在 OpenRouter 与官方平台同步提供一周免费 API 调用。
免费期结束后,将按使用量计费:输入 0.1 美元 / 百万 tokens,输出 0.3 美元 / 百万 tokens,缓存命中 0.02 美元 / 百万 tokens(按 20% 计费)。
Ling-2.6-flash 官方 API 服务也已正式开放,官方免费期结束后,平台仍将提供每日 50 万 tokens 免费额度;超出部分按量计费:输入 0.6 元 / 百万 tokens,输出 1.8 元 / 百万 tokens。
IT之家注意到,官方表示,模型的 BF16、FP8、INT4 等版本也将于近期正式开源。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

