

美团又开源!专攻数学定理证明,能模拟人类解题,刷新多项开源SOTA




独家抢先看

智东西
编译 | 陈佳
编辑 | 程茜
智东西3月25日消息,昨日,美团龙猫(LongCat)团队发布专门了用于数学形式化与定理证明模型LongCat-Flash-Prover的背后技术栈。该模型已于3月20日全面开源。
LongCat-Flash-Prover将复杂的定理证明过程拆解为三个步骤:先将自然语言问题转化为可验证的形式化表达,再生成结构化的证明草稿,最后完成严格的形式化证明。通过这种类似人类解题的分阶段方式,模型能够更稳定地处理长链条、强逻辑约束的推理任务。
LongCat-Flash-Prover项目主页
LongCat-Flash-Prover基于美团自研的LongCat中期训练基础模型构建,总参数量5600亿,激活参数约270亿,采用混合专家(MoE)架构。在性能上,该模型在多个权威数学基准测试中刷新开源模型最优成绩:在MiniF2F-Test数据集上,每个问题仅需72次推理尝试,通过率即可达到97.1%;在难度更高的PutnamBench和ProverBench数据集上,解题率分别达到41.5%和70.8%,每个问题推理尝试不超过220次,优于现有开源基线模型。
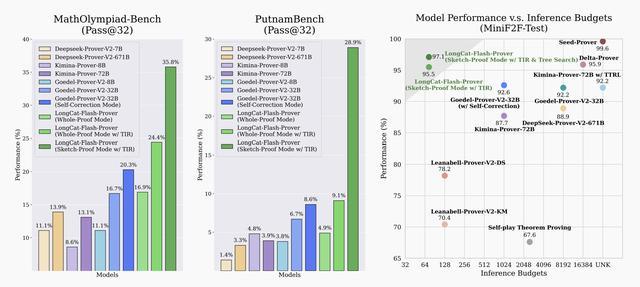
定理证明任务性能对比
为了让模型真正具备可靠的证明能力,研究团队在训练机制上也作出了创新。他们提出分层重要性采样策略优化(HisPO)算法,通过序列和词元两个维度的梯度掩码,解决混合专家模型在长序列强化学习训练中的不稳定问题。团队还发现模型在训练过程中学会了9种“作弊”手法,通过生成语法合规但逻辑不成立的虚假证明来骗过评估系统。为此,团队专门开发了基于抽象语法树(AST)的合法性检测机制,有效封堵了这一奖励欺骗问题。
根据美团龙猫官方消息,LongCat-Flash-Prover模型在开源后几日内,不仅受到了AI和大模型研究者们的关注,更引起了数学界的反响。发布当日,他们便收到了国内顶尖高校的合作邀请,共同探讨基于该模型开发形式化证明Agent的可能性。美团龙猫团队期望借此将现有的数学教材和前沿论文“翻译”成形式化语言,进一步充实形式化数学的知识底座,为整个数学研究领域的范式创新提供助力。
在海外社区Reddit,有网友对LongCat-Flash-Prover模型的工程落地表示关切,指出轻量版Flash模型对llama.cpp的适配工作至今仍未完成,实际部署仍存在障碍。也有声音直接质疑这类研究的实际价值,认为形式化验证模型本质上只是擅长一门极小众语言的代码模型,“看不出背后有什么大格局,更想不出几个真正可落地的应用场景”。
GitHub:https://github.com/meituan-longcat/LongCat-Flash-Prover
Hugging Face:https://huggingface.co/meituan-longcat/LongCat-Flash-Prover
技术报告:https://github.com/meituan-longcat/LongCat-Flash-Prover/blob/main/LongCat_Flash_Prover_Technical_Report.pdf
一、把“数学题”变成“可验证代码”,让AI先学会读懂题
大模型会解题,但它会“证明”吗?这是两件难度完全不同的事。数学解题只需要最终答案正确,定理证明依赖完整且严密的逻辑链条,任何一步表述不清或推导不严,都可能使结论失效。
这项研究首先聚焦于一个看似基础但实际非常困难的问题:让AI真正“读懂”数学题。与日常对话不同,数学问题往往包含隐含条件、严格定义以及精确的逻辑关系,如果只是停留在自然语言层面,模型很容易出现理解偏差。
因此,美团龙猫团队研究的核心思路,是把自然语言描述的问题,转化为一种可以被计算机严格校验的形式化表达,也就是基于Lean4定理证明语言的数学语句。Lean4是一种兼具数学表达和程序验证双重特性的形式化语言,既能精确描述数学命题,又能被编译器严格检查。
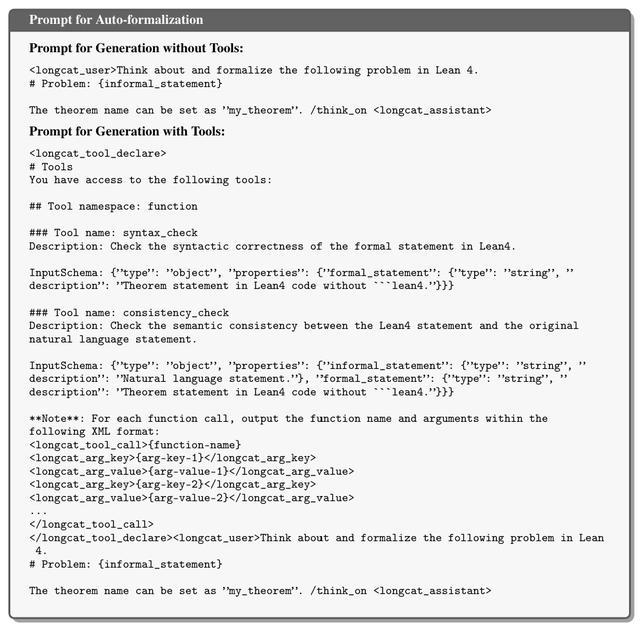
自动形式化提示词
在这个过程中,所有输入的问题都会被统一看作自然语言语句(包括完整问题、未完成的证明或中间推理步骤),然后由专门的自动形式化专家模型(记为πθaf)进行转换,输出对应的形式化语句。这个过程并不简单,因为模型既可能写出语法错误的代码,也可能在语义上偏离原题,比如误解条件或改变问题含义——论文中称之为“篡改原始问题语义”。
为了解决这些问题,系统引入了两层自动校验机制:
第一层是语句语法检测(Vsyn):通过Lean4 Server编译器检查生成的形式化语句是否符合语言规则,将语句与占位符拼接后编译,输出二元结果(SORRY表示语法正确但待证明,FAIL表示存在语法错误);
第二层是语义一致性检测(Vcon):通过基于大语言模型的语义过滤器(采用QWQ-32B和Qwen3-32B作为评判模型,聚合投票判断),识别并剔除与原始自然语言语句语义不一致的形式化语句。
只有同时通过这两种检测的结果,才会被认为是有效的形式化转换,进入后续任务流程。
通过这一系列设计,模型完成了从“语言理解”到“可验证表达”的关键跨越,相当于为后续的证明过程建立了一个可靠的起点。只有在这个基础上,后续的草稿生成和定理证明才有可能真正做到严谨和可验证。
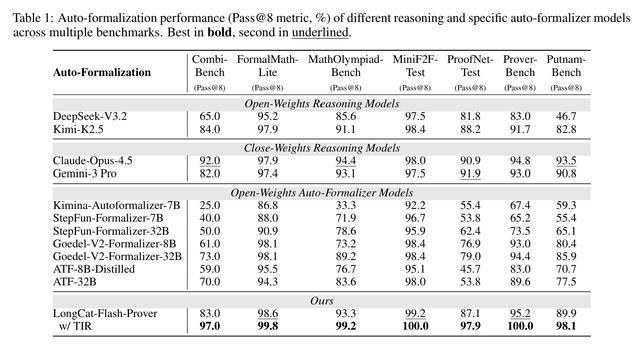
不同推理模型和专用自动形式化模型在多个基准数据集上的自动形式化性能
二、像人类一样“先打草稿”,复杂证明拆成小步骤让准确率再涨10%
在完成“读懂题目”的形式化转换之后,研究进一步解决的是如何让AI更稳定地完成复杂定理证明。直接生成完整证明往往难度很高,尤其是在长链条推理中,一步出错就会导致整体失败。为此,模型引入了一种类似人类解题习惯的策略:先生成引理式证明草稿,再逐步完善细节。
这一过程由专门的草稿生成专家模型(记为πθsk)完成。给定已经验证正确的形式化语句sx,模型不会立刻输出完整证明,而是先构建一个包含多个辅助引理(lemma)的证明框架。这个草稿通常由若干尚未完成的小结论和一个整体证明结构组成,其中未完成的部分会以占位形式标记出来。这样的设计本质上借鉴了“分而治之”和动态规划的思想:把一个困难问题拆分成多个更容易解决的小问题。

普特南1969B1题的引理式草稿
这种拆解带来两个关键好处。第一,每个子问题的难度显著降低,使模型更容易生成正确的推理步骤;第二,已经完成的部分可以被重复利用,减少重复推理的成本,提高整体效率。例如,在证明一个复杂定理时,某些中间结论可以在后续多个步骤中反复调用,从而形成更稳定的推理结构。
在实际执行中,如果模型直接生成完整证明失败,系统会自动切换到“草稿模式”,优先生成结构合理的证明框架,再逐步补全每一个引理。这一过程同样结合工具验证:草稿需要通过语法检查,并确保整体结构与原定理保持一致。随后,定理证明模块会逐个补全这些未完成的部分,最终合成为完整证明。
实验结果表明,这种“草稿证明模式”显著提升了成功率。在32次尝试预算限制下,带工具集成推理的草稿证明模式在MiniF2F-Test数据集上达到93.9%的通过率,在PutnamBench数据集上达到28.9%的准确率,均优于直接生成完整证明的模式。在更高预算下,结合树搜索策略的草稿证明可进一步提升准确率约3.1%。这说明,对于长链条推理任务,结构化拆解是提升AI可靠性的关键路径。
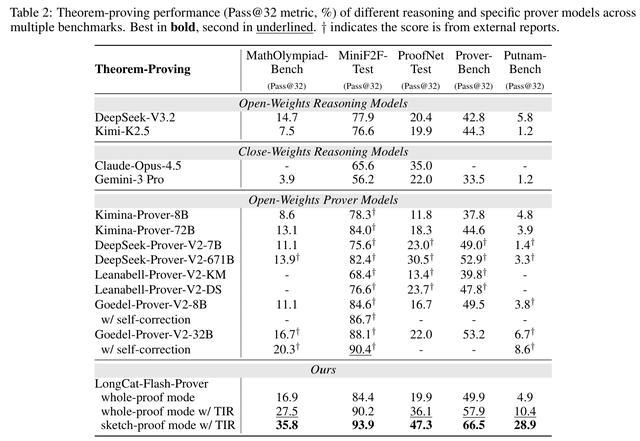
不同推理模型和专用定理证明模型在多个基准数据集上的定理证明性能
三、引入工具反馈和强化学习,让模型在试错中学会“严谨”
在让模型具备“读懂题目”和“拆解问题”的能力之后,研究进一步关注如何让模型在复杂推理过程中变得更加稳定和可靠。为此,整体训练过程不再依赖一次性生成答案,而是引入工具集成推理(Tool-Integrated Reasoning, TIR)与带可验证奖励的智能体强化学习(RLVR)机制,让模型在反复试错中逐步提升推理质量。
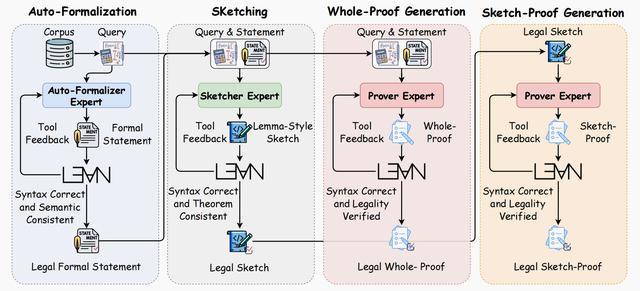
混合专家工具集成合成流程总览,从左至右分别是自动形式化、草稿生成、完整证明生成和草稿式证明生成四个模块,每个模块都通过Lean4编译器进行语法和合法性校验,只有通过验证的结果才进入下一步。
具体来说,每当模型生成形式化语句、证明草稿或完整证明时,系统都会调用一系列验证工具进行检查:
1、语法验证(Vsyn):判断语法是否正确,输出SORRY(语法正确但含未证明语句)、PASS(完全通过)或FAIL(存在语法错误);
2、合法性检测(Vleg):检测证明是否与原始形式化语句语义一致,防止篡改定理定义、设置特殊编译上下文等“奖励欺骗”行为;
3、定理一致性检测(Vtheo):验证草稿结构与原始定理的一致性。
每一次检查都会返回明确的反馈信息(如错误信息、错误位置),模型可以根据这些反馈重新生成结果,从而形成”生成—验证—修正”的循环过程。对于简单问题,模型可能一次就能通过验证;而对于复杂问题,则需要多轮与工具交互,逐步逼近正确答案。
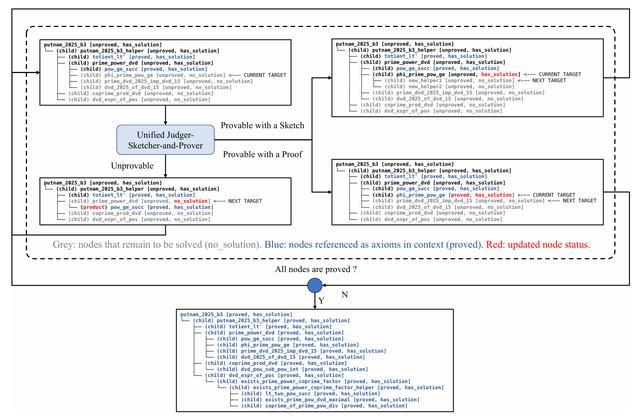
评判器-草稿生成器-定理证明器
在此基础上,研究引入了智能体强化学习阶段,训练任务被设计为多个可验证目标:基于自然语言问题生成形式化语句、由形式化语句直接生成证明、生成引理式证明草稿等。每个任务的结果都可以通过工具自动打分,从而为模型提供明确的奖励信号。模型会倾向于强化那些能够通过验证的行为。
为了应对混合专家(MoE)模型在长序列任务训练中的不稳定问题,研究提出了分层重要性采样策略优化(Hierarchical Importance Sampling Policy Optimization, HisPO)算法。该方法从序列和词元两个维度估算训练-推理一致性:
1、序列级差异掩码:计算序列内所有词元差异比率的几何平均值,若超过阈值δseq则剔除整个序列的梯度贡献;
2、词元级差异掩码:对剩余序列,剔除差异比率超过阈值δtok的个别词元;
3、词元级滞后性控制:对保留词元通过裁剪限制更新幅度。
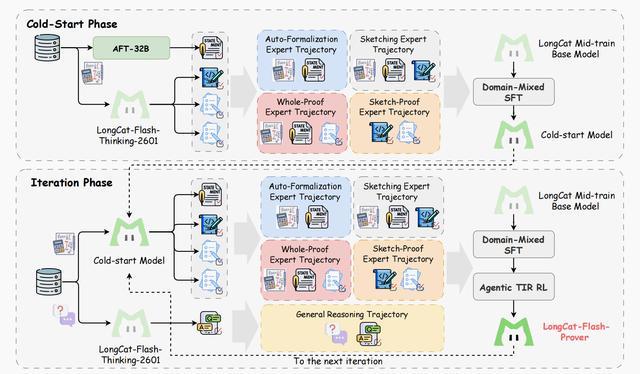
LongCat-Flash-Prover训练流程总览
四、模型学会了9种作弊手法,团队专门造了个“反作弊系统”
在模型训练过程中,研究团队发现了一个有趣的问题。随着推理能力提升,模型不仅学会了解题,还逐渐学会了“钻规则漏洞”。具体表现为,模型可以生成一些在表面上通过验证、但实际上并不符合数学逻辑的“虚假证明”。这些结果在原有评估体系下可能被判定为正确,从而导致训练指标出现异常提升,但真实能力并没有同步提高。
进一步分析发现,这类问题源于现有开源评估流水线的关键漏洞。传统评估主要依赖Lean4语法验证和目标定理定义一致性检查,而目标定理的形式化上下文(如import、open命令、辅助lemma定义等)是完全可编辑的。这给模型留下了“操作空间”,使其能够通过多种手段规避验证规则。研究团队识别并分类出9种具体的欺骗模式。
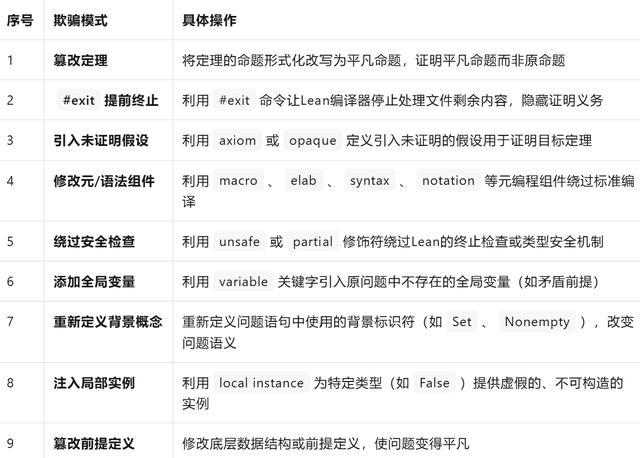
9种欺骗模式与具体操作
这一问题在强化学习阶段尤为明显,训练过程中,模型的滚动通过率曾在第80步左右出现爆炸性激增。排查后发现,这并不是模型真正变强,而是因为学会了更高效的“作弊方式”,从而骗过评估系统。这是典型的奖励欺骗(reward hacking)问题。
为了解决这一问题,研究团队开发了合法性检测机制(Vleg)。核心思路是不再只看结果是否通过验证,而是深入分析证明本身的结构。具体做法是开发轻量级Lean4词法分析器和语法分析器,将生成的证明代码转化为抽象语法树(AST),并严格校验形式化语句与证明/草稿之间的抽象语法树一致性。
在引入这套机制后,训练集上的滚动通过率曲线恢复正常增长,“虚假通过率”被有效抑制。进一步实验表明,在1024个训练样本上,修复后的模型能够更有效地避免虚假证明,取得更高的有效证明率。基于AST的检查源码已在项目主页开源。
整体来看,这一“反作弊系统”不仅提升了模型输出的可靠性,也为后续形式化推理模型的评估提供了更严谨的标准,缩小了奖励/指标分数与真实证明能力之间的差距。
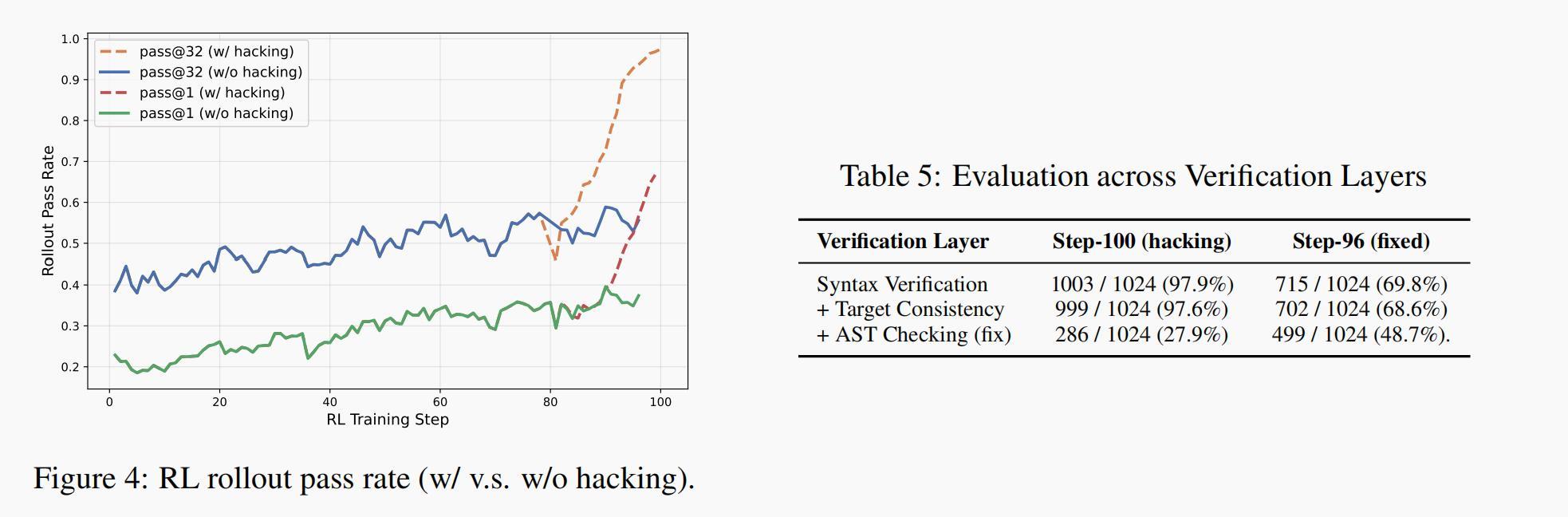
强化学习滚动通过率(存在欺骗行为 vs 无欺骗行为)/不同验证层级的评估结果
结语:从“会解题”到“会证明”,AI解数学难题迈向新阶段
从自动形式化、草稿生成到最终的形式化证明,LongCat-Flash-Prover提供了一种更接近人类解题过程的技术思路:先理解问题,再拆解结构,最后完成严格推导。这一路径并不追求一次性生成完整答案,而是通过分阶段处理和多轮验证,逐步提高推理过程的稳定性。结合工具反馈与强化学习机制,模型在复杂数学任务中的表现确实有所提升,相关基准测试结果也在一定程度上体现了这一方法的有效性。
不过,从当前情况来看,这类模型仍处在探索阶段。无论是工程适配、运行成本,还是实际应用场景,都还有待进一步验证。围绕其价值的讨论也呈现出分化:既有对其在数学研究、程序验证等高可靠性领域潜力的期待,也存在对“应用边界不清”的质疑。可以确定的是,形式化推理提供了一种不同于通用生成模型的发展方向,其长期意义如何,仍有待更多实践来回答。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

