

Kimi“打破Transformer架构”真相



独家抢先看
本周,一篇题为《Attention Residuals》的论文,将Kimi推至全球人工智能领域的聚光灯下。论文作者之一,甚至是一名年仅十七岁的高中生。xAI首席执行官埃隆·马斯克与Google高级人工智能产品经理Shubham Saboo,亦公开发文祝贺。后者更宣称,Kimi正在触及Transformer架构中“长达十年无人触碰的部分”。
一时间,舆论场喧嚣四起。诸如“打破Transformer架构”、“硅谷破防”、“改写行业规则”等标题,迅速占据头条。
本文结论先行:这是一项天才般的构想,一次极其硬核的研究,但其本质并未脱离Transformer架构的基本框架。至于那些耸人听闻的标签,大多出自营销号之手,缺乏事实依据。
事实上,针对残差连接的探索并非孤例。从2022年的DeepNorm到2024年的DenseFormer,优化这一深度神经网络的基石,始终是业界持续发力的方向。Kimi研究团队并非此技术路线的开辟者,却在这条既有路径上,贡献了一个兼具激进性、优雅性与工程潜能的解决方案。
01
深层Transformer的结构性困境
在规模化法则的驱动下,提升模型性能的路径愈发依赖于参数与规模的扩张,神经网络层数的激增成为必然。然而,研究团队注意到一个关键现象:数据在神经网络层间传递时,存在着“PreNorm稀释问题”。PreNorm作为一种归一化技术,因其能有效稳定训练、加速收敛,已成为现代架构的主流选择。
为便于直观理解,不妨将一个大模型比作一条由一百名程序员组成的流水线。每位程序员对应一层神经网络,共同协作完成一个大型软件项目。
在传统的标准残差连接模式下,层与层之间的状态更新遵循如下公式:
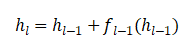
当前层的输出,等于上一层输出与该层自身“修改部分”(即变换函数输出)的直接相加。类比而言,每位程序员接收前一位的代码,附上自己的修改后,传递给下一位。
这种简单累加的方式,在实践中会引发连锁问题。从数学视角审视,它将导致两个互为因果的训练困境:
其一,早期信息被稀释掩埋。首层神经网络提取的原始特征——例如token的初始语义——在经历数十层累加后,其相对权重被逐层消解,面目模糊。流水线末端的程序员,无从知晓源头究竟起草了怎样的底层逻辑。模型越深入,对早期低级特征的精确检索与利用便越困难。
其二,数值尺度膨胀与梯度失衡。残差的持续累加,如同项目代码库的无休止扩充。后期加入的程序员若想使自己的改动产生可见影响,不得不添加更大量的代码。对应到网络,深层必须输出数值规模更大的信号,才能在累加中占据一席之地。这一现象在正向传播中或许尚可容忍,但在反向传播中则潜藏危机:浅层梯度可能剧烈震荡,深层梯度却趋于微小,整个网络的梯度分布极度不均,训练极易失稳。
因此,研究的核心命题便凝练为:如何让处于网络最深层的“程序员”,依然能够清晰辨识并调用首位“程序员”所撰写的基础代码?
02
时间维度与深度维度的对偶映射
Kimi研究团队的关键洞见,在于识别出神经网络演进史中,时间序列处理与网络深度构建之间存在的对偶关系。
Transformer并非神经网络的初始形态。约在2018年前,循环神经网络(RNN)主导着序列建模。RNN以时序方式逐词处理文本,将历史信息压缩为单一隐藏状态向后传递。其后果是,后序单元只能接收一个混杂了过往信息的“压缩包”,早期输入极易被遗忘——这一过程,与标准残差连接的信息传递机制惊人地相似。
Transformer则凭借注意力机制,颠覆了这一范式。在自回归解码中,每一位置的词元,都能直接“回望”序列中所有前置词元,并通过加权聚焦关键信息。在时间维度上,注意力机制完美消解了信息压缩与遗忘的难题。
一个自然的类比由此浮现:能否在网络的深度维度上,扬弃残差连接所隐含的“RNN式思维”,转而引入注意力机制?
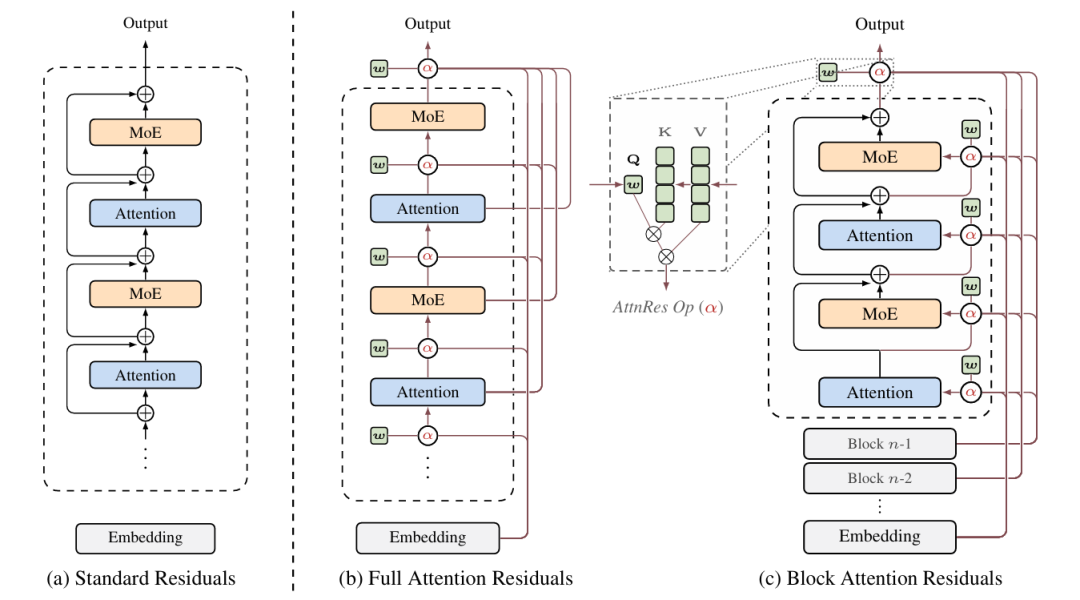
这正是Kimi论文的核心创新——注意力残差(Attention Residuals, AttnRes)。传统残差累加公式被重塑为一个基于Softmax的注意力加权形式:
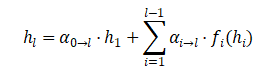
新公式不再将浅层输出简单相加,而是为每一层配备一个“伪查询向量”,使其能够动态扫描之前所有层的输出,并为那些包含关键信息的层赋予极高的Softmax权重。无关信息层的权重则被压至近零。
这套内容感知、输入依赖的选择机制,本质上是将Transformer的核心理念横向迁移至残差路径的设计中。残差连接由此从被动的“信息搬运”,转变为主动的“按需检索”,有效规避了深层信息稀释的痼疾。
03
从理论构想到系统级工程
若仅止步于此,注意力残差仍可能囿于实验室的理想图景。真实的大模型工程实践,尤其面对千亿参数、分布式训练的严苛环境,直接套用该机制将引发显存与通信的“爆炸”。
在分布式训练普遍采用激活重算、流水线并行等技术的前提下,若强行实现跨层全连接,深层网络将不得不跨物理GPU节点,获取所有浅层完整的输出张量。随着层数L增加,跨阶段数据传输量与显存占用将以O(Ld)规模急剧膨胀,对算力集群构成灾难性负担。
因此,Kimi团队为解决工程落地而提出的分块注意力残差,展现出极高的实用智慧。
为将理论付诸实践,Kimi团队设计了一套精妙的降维方案:
核心思路是“分块降维”。
回到程序员流水线的比喻:要求末位程序员洞悉每一位前序同事的具体贡献,意味着每位前序程序员都需保留完整的“草稿箱”——这在物理空间上是不可行的。解决方案是,将程序员划分为N个部门。部门内部沿用标准残差,并将多层的输出压缩成一个单一的“块级表征”。部门之间则启用注意力残差机制,只需关注这N个块级表征,而无需追溯每个具体层级的输出。
这一简单而大胆的策略,直接将显存与通信的复杂度从O(Ld)降至O(Nd),为理论落地扫除了最大障碍。
其次,训练阶段的跨阶段缓存设计进一步优化了通信开销。在主流的交错式流水线调度模式下,每个物理GPU常需处理多个计算阶段。团队为此设计了本地缓存机制,确保先前接收到的块级表征驻留于本地显存,从而避免跨节点重复传输。此举大幅压缩了流水线并行的通信峰值,并使跨块通信时间可被计算过程有效掩盖。
最后,推理阶段的双阶段计算与在线Softmax融合,缓解了内存带宽瓶颈。推理时反复读取大量历史块级表征,易导致严重的内存带宽压力。研究团队采用双阶段策略:第一阶段以批处理方式计算跨块注意力,摊销内存读取成本;第二阶段顺序计算块内局部注意力。两阶段结果通过在线Softmax技术无缝合并,并与RMSNorm等算子进行内核融合。
技术细节无需赘述,但结果令人印象深刻:上述复杂的跨层注意机制叠加后,Block AttnRes带来的额外训练开销几乎可以忽略;在典型自回归推理场景中,端到端延迟增幅低于2%。Kimi团队在改写大模型底层网络拓扑的同时,实现了如此程度的优化,堪称工程上的奇迹。
04
实证效果与产业意义
最终,Kimi研究团队将这套架构部署至一个参数规模为48B(激活3B)的小型MoE模型,并使用高达1.4万亿token的数据进行真实环境预训练。
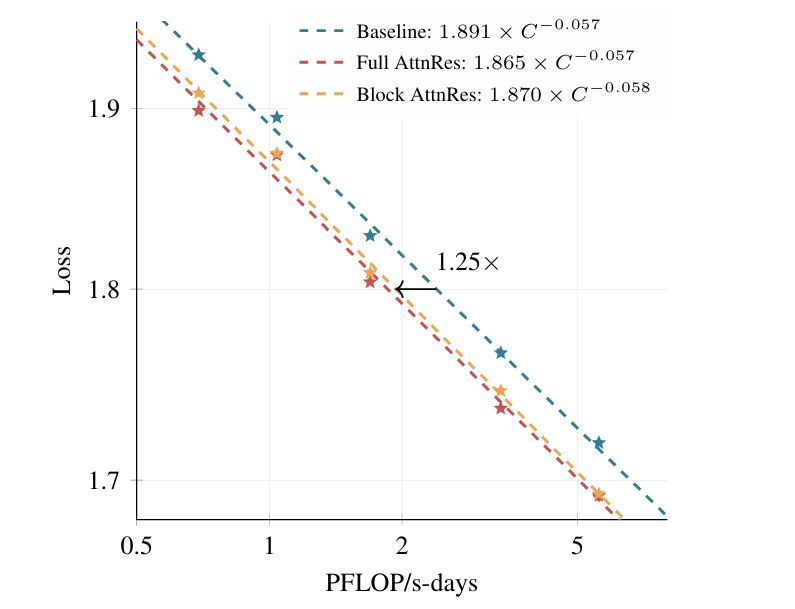
规模化法则曲线显示:在同等算力投入下,应用Block AttnRes的模型始终获得更低的损失值。简单换算,该架构使模型能达到传统基线模型需耗费1.25倍算力方可实现的性能。对于耗资动辄千万美元级的预训练阶段而言,“白嫖”25%的算力增益,蕴含着巨大的商业价值。
下游能力测试中,需要多步骤逻辑推理的任务获益最为显著:
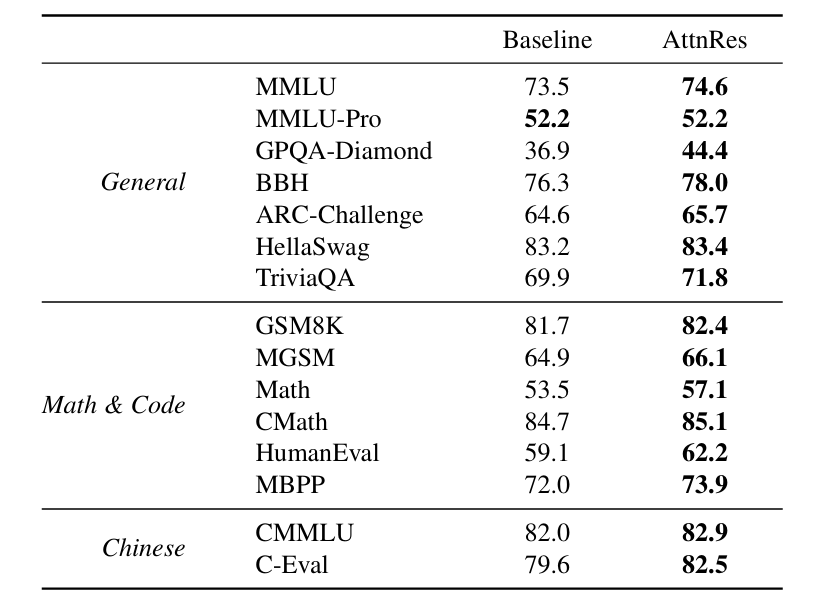
GPQA-Diamond提升7.5%,Math提升3.6%,HumanEval提升3.1%。这一结果在逻辑上高度自洽:数学推导与代码生成皆要求模型具备长时间推理与信息保持能力,AttnRes的深度检索机制恰好契合了这种“不忘初衷”的内在需求。
月之暗面创始人杨植麟在2026年英伟达GTC大会上的公开演讲,也从侧面印证了这套架构的价值:“要推动大模型智能上限持续突破,必须对优化器、注意力机制和残差连接等底层基石进行重构。”
当然,这项技术距离真正颠覆Transformer架构或改写行业规则,尚有显著距离。核心工程代码尚未完全开源,公开仓库中仅提供伪代码级别的演示。同时,论文中亮眼的实验结果,全部出自月之暗面自有的模型结构与私有数据。注意力残差能否在其他主流大模型上复现出稳定且显著的收益,仍有待第三方独立验证。
客观而言,在深度学习领域,对底层机制进行启发式修改的尝试并不鲜见。但一篇论文能获得马斯克的“光速”点赞,本身已说明其分量。
最准确的论断或许是:这是一个兼顾了学术美学与工程实用性、值得全行业深入跟踪的残差机制新设计。它并非推翻Transformer的神话,而是为这座大厦添上了一块关键的砖石。
而月之暗面借此向世界展示:在底层架构创新的“深水区”,中国AI企业同样有能力交出极具技术含量、堪称世界级水准的答卷。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

