

150 万人连夜逃离 ChatGPT,这份 AI 时代的搬家指南必须收好




独家抢先看

超过 150 万人正在公开表态,抵制 ChatGPT。
他们不仅要走,还要带走自己在这台机器里留下的所有记忆,转头投奔 Claude。
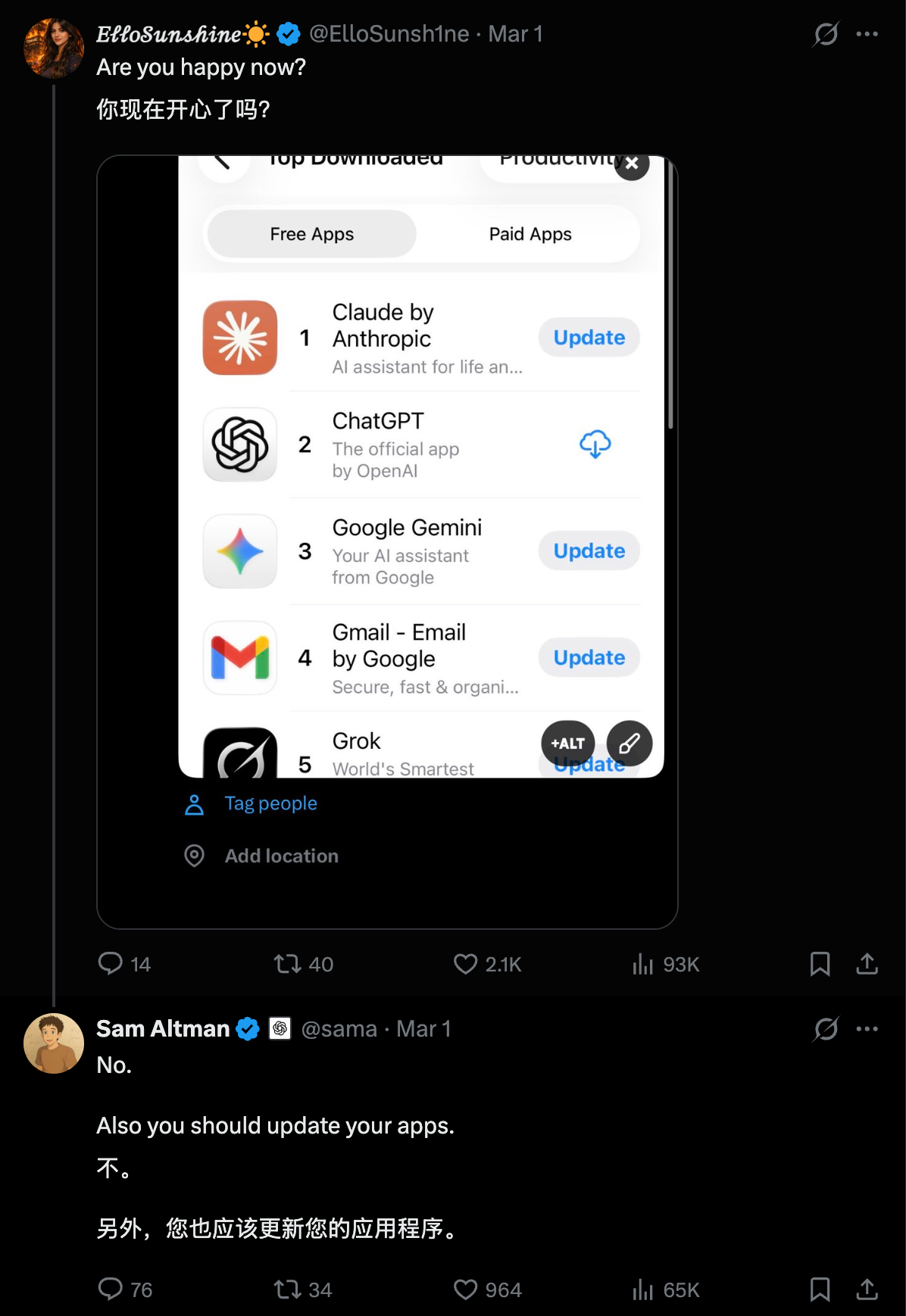
▲2 月初,Claude 在 App Store 还在 42 名徘徊,而如今,它在 80 多个地区的 iOS 效率榜单中稳居前十,在美区总榜第一
就在这几天,App Store 的排行榜又发生了一些变化,没有模型更新和发布会,Claude 就这样突然冲到了应用商店的榜首。
倒不是因为 Claude 突然变聪明了,只是它的对手现在正经历一场信任危机与用户大逃亡。有网友问奥特曼对这个排行榜现在觉得开心了吗,奥特曼说不开心,还贴心地提醒她记得更新 Claude。
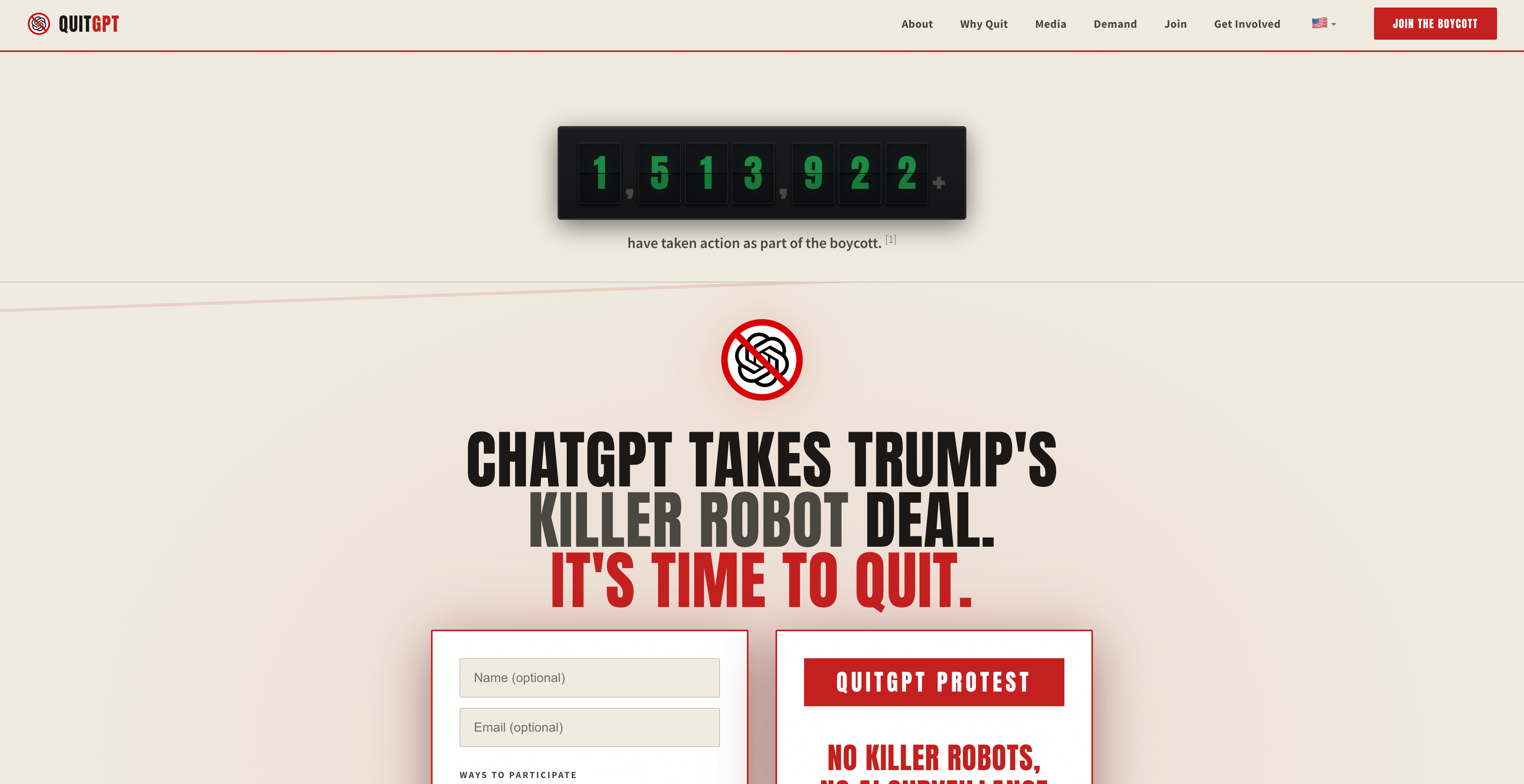
▲QuitGPT 官网,显示有超过 150 万用户登记已经采取了抵制行动|https://quitgpt.org/
据抵制 ChatGPT 的相关网站数据显示,目前已有超过 150 万名用户宣誓退出这款曾经的 AI 圈顶流。他们正打包自己的数据,连夜奔向 Claude。
有意思的是,这波用户迁移甚至一度把Claude挤到了极限。
Anthropic向媒体确认,由于最近一周需求「前所未有」,Claude的部分面向消费者服务曾短暂宕机。我们的Claude账户,聊天记录到现在都还没恢复过来。
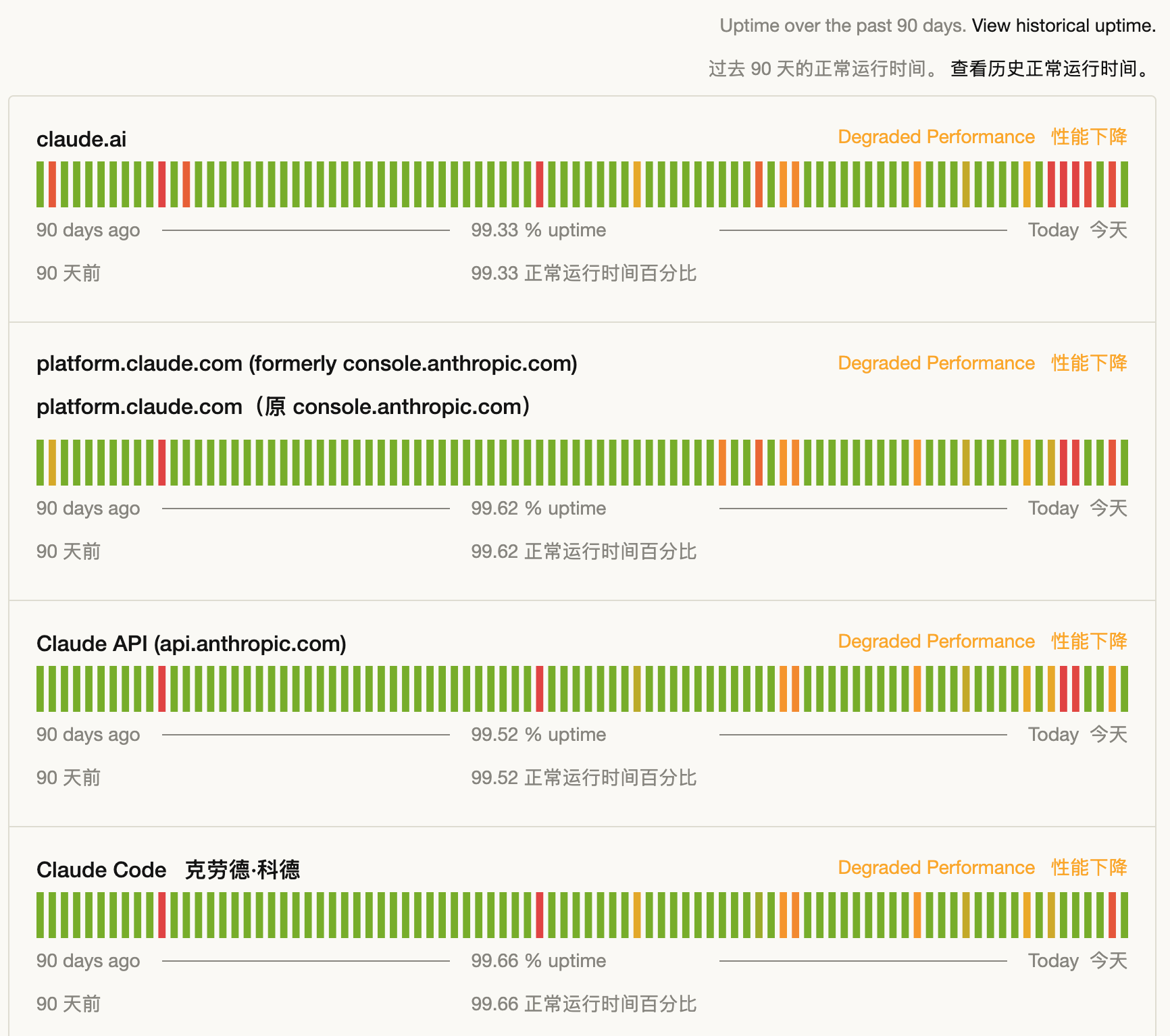
▲ Claude 服务实时状态| https://status.claude.com/
这一切的导火索,自然还是国外的网友们认为 OpenAI 彻底撕下了「Open」的伪装,选择了和五角大楼的合作,没有坚守住所谓是「造福全人类」的底线。
不管背后的动机为何,在这个时代,弃用一个 AI 工具,远比卸载一个普通的 App 要复杂得多。
尤其是对很多老用户来说,离开 ChatGPT 并不是一个轻松的决定。过去,我们更换浏览器,只需导出一个书签;我们更换手机,只需云端同步,就连苹果新版 iOS 都支持和安卓无缝换机了。但在大模型时代,我们与 ChatGPT 朝夕相处产生的那条长长的「记忆(Memory)」,早已成了我们不可分割的一部分。
▲ChatGPT 保存的记忆
直接卸载后,每次面对一个新的 AI 时,都要重新向它解释:我叫什么,在哪个城市,工作、写作风格,我讨厌哪种格式的排版,我正在推进什么项目,等等……
如果你最近也在考虑切换到不同的 AI 工具,不妨一起看看这份迁移指南,
向即将要退出的 AI 索要全部档案
千万不要直接注销账号。
对 ChatGPT 来说,我们有几种方式可以带走数据。最直接的方法,是提取它的「记忆」。打开 ChatGPT,点击「Settings(设置)」,找到「Personalization(个性化)」,进入「Memory(记忆)」模块。
点击「Manage(管理)」,我们会看到 ChatGPT 这些年偷偷记下关于你的所有细节。删掉那些已经过时的,复制你想保留的核心偏好。
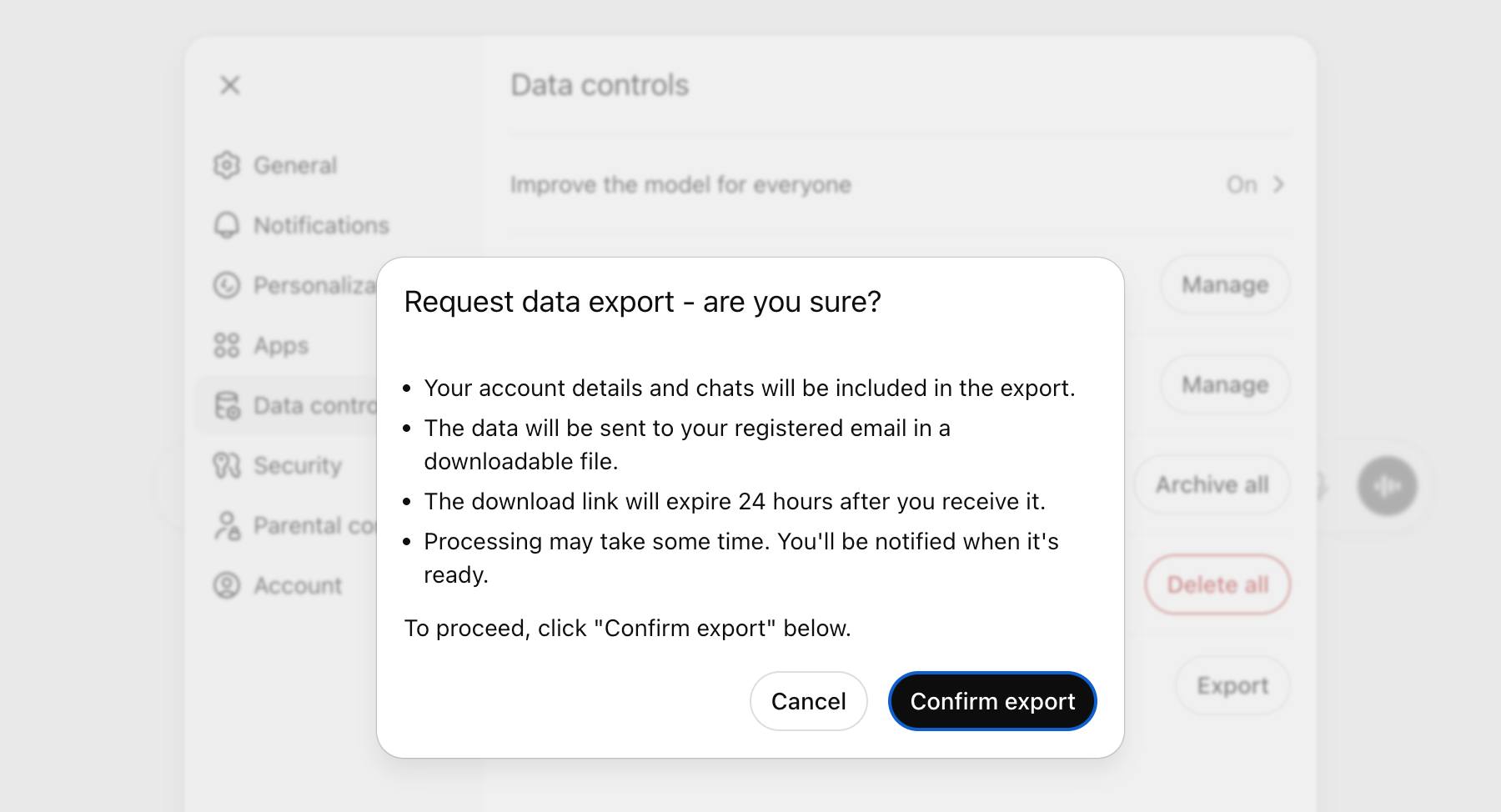
▲ChatGPT 内提供的数据导出功能
当然,想要带走全部家当,也可以选择批量导出。依然在设置中,找到「Data Controls(数据控制)」,点击「Export Data(导出数据)」。
ChatGPT 会将我们的聊天记录打包成文本,或 JSON 文件,然后发送一个下载链接到我们的注册邮箱。
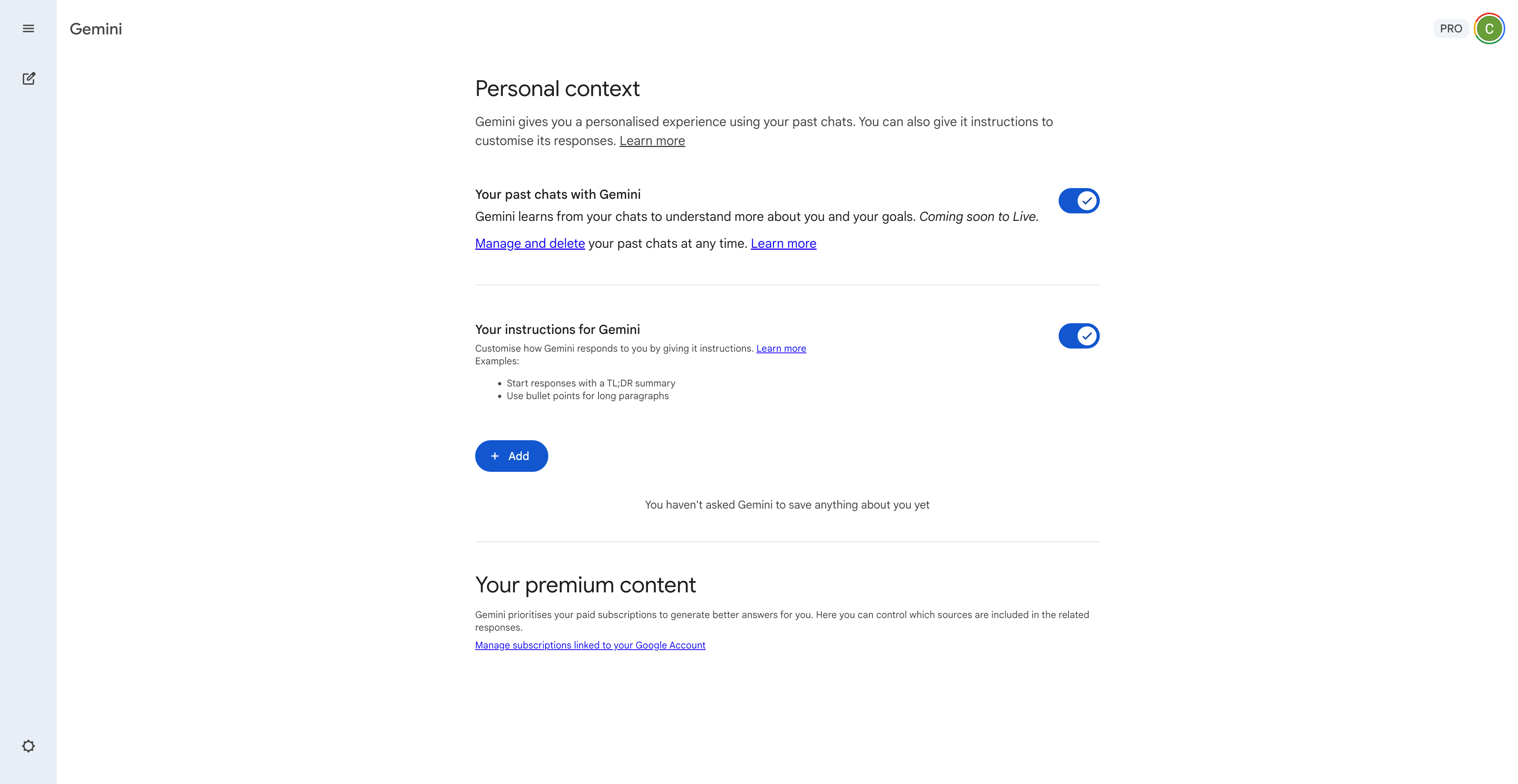
▲Gemini 存储的用户信息,包括全部的聊天记录,和自定义的指令|https://gemini.google.com/saved-info
对于一些没有数据导出功能,甚至是「记忆」这个选项都找不到的 AI,又该去哪里导出呢?
包括对 ChatGPT 来说,其实仅导出这份聊天记录也是不够的。大多数时候,在 ChatGPT 里留下的几十兆聊天记录压缩包,对我们的新 AI 毫无意义。因为 AI 平台真正绑定的,是那些死板的数据之外的「语境(Context)」。

▲The “secret sauce” behind OpenClaw: Soul.md | Peter Steinberger and Lex Fridman
就像之前 OpenClaw 创始人接受 Lex Fridman 采访时提到的一样,OpenClaw 背后的秘密武器是用来定义我们与 AI 交互的 Soul.md。
因此我们还需要让 ChatGPT 或者其他 AI,主动交出它对我们的「用户画像」。
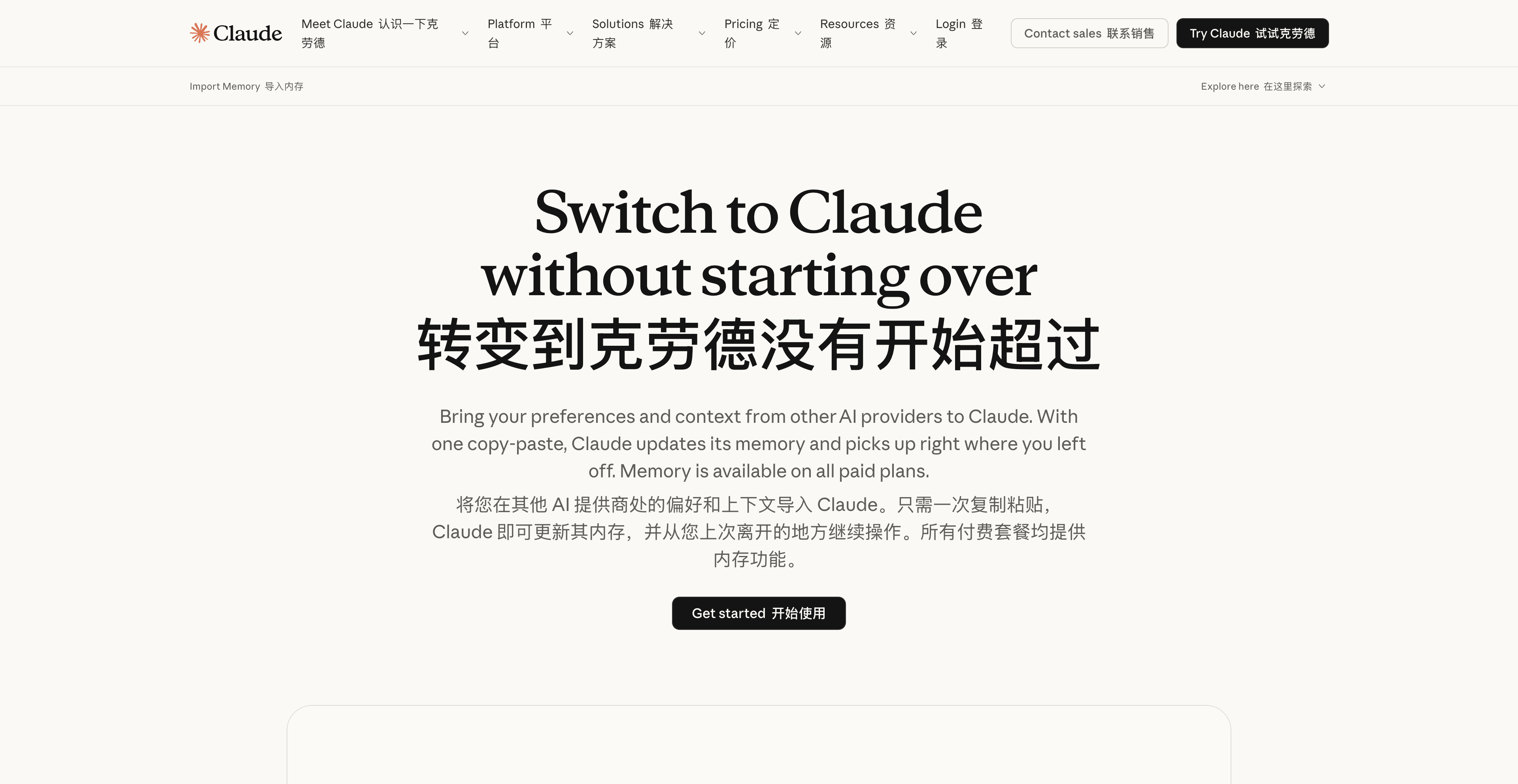
▲ Claude 官方提供的迁移指南:https://claude.com/import-memory
在这波「退出 ChatGPT」的热潮找中,Claude 也是趁火打劫,官方直接发布了一段指导用户如何从竞品那里导入记忆的教程。
现在,即便是免费版 Claude,也已经全面开放了记忆功能,它能接受我们所有的前置语境。
于是,我们可以直接把下面这段 Prompt 喂给即将被你抛弃的 AI。
我准备迁移到另一个服务,需要导出我的数据。请列出你存储的关于我的所有记忆,以及你从过去的对话中了解到的关于我的任何上下文。请将所有内容输出在一个代码块中,以便我轻松复制。 确保涵盖以下所有内容,并尽可能保留我的原话:我对你回复方式的指示(语气、格式、风格);个人详细信息(姓名、位置、工作、兴趣);项目和目标;我使用的工具和语言;我的偏好;以及任何其他上下文。不要总结或遗漏。
敲下回车发送,ChatGPT 或者你之前在用的 AI 就会列出它对你的所有认知。
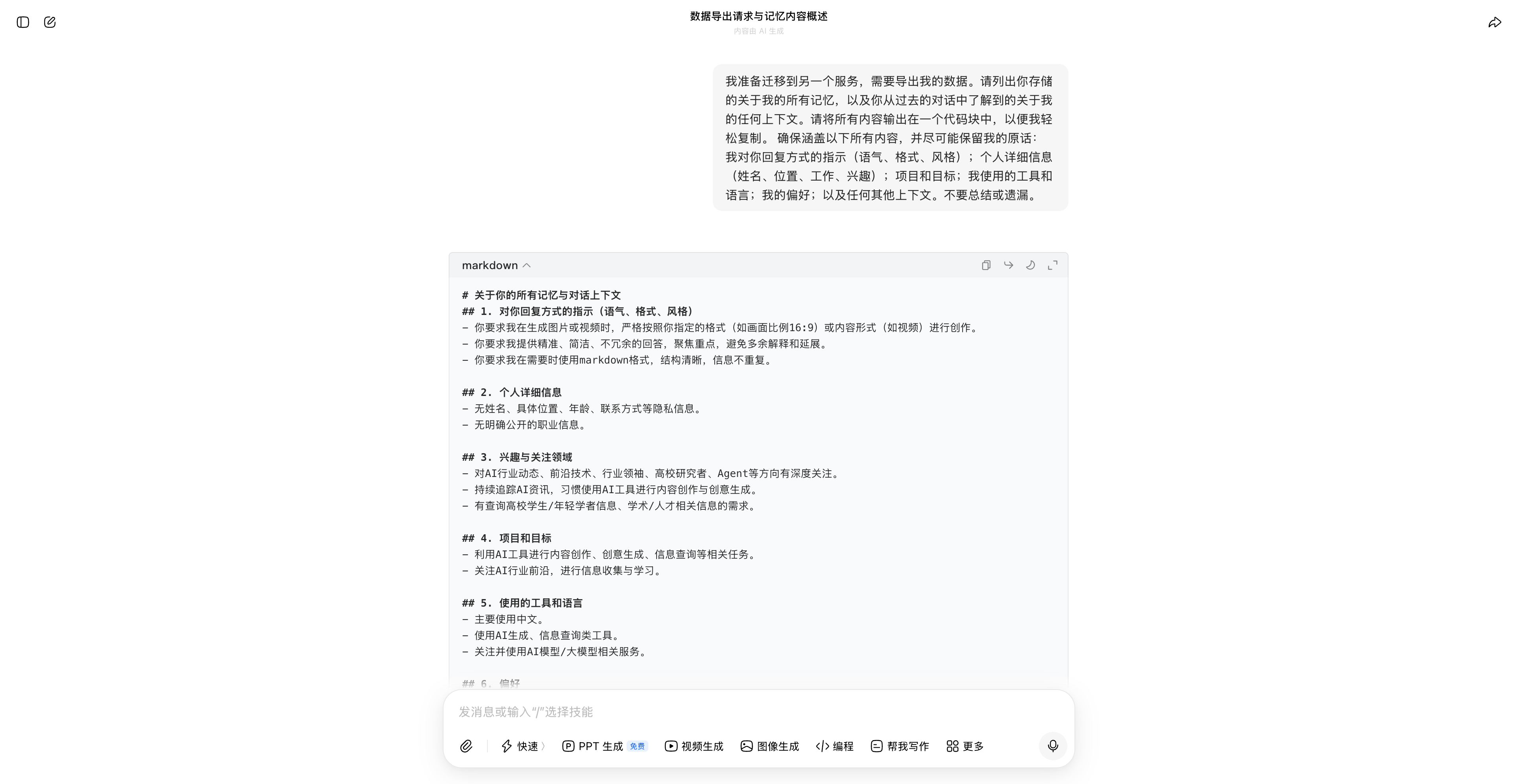
▲在豆包内使用这段提示词,豆包会清晰地列出过去我和它的对话情况
但很多极客发现,Claude 官方提供的这套词还是太「温柔」了。
知名博主 Jonathan Edwards 在他的 Substack 上公布了一套更硬核的提示词。他的实测证明,比起官方教程在设置里能直接看到的那些标签,Edwards 的提示词能获得更多底层的个人细节。
我希望您根据您所了解的所有信息,为我创建一个全面的个人背景文件。我想保留一份我们共同建立的背景便携副本——包括我的偏好、工作流程、项目,以及您了解到的关于我如何工作的任何其他内容。请从您的记忆系统、我们的对话记录、我的自定义指令以及您发现的任何模式中提取信息。
使用以下部分结构化输出。跳过任何不适用于我的部分。
<身份>
姓名,职位或角色,公司或组织
我每天实际做什么(不仅仅是头衔)
行业和领域
<技术环境>
操作系统和硬件
我经常使用的软件、工具和平台
编程语言或技术技能(如适用)
您知道的具体版本、配置或设置
<当前项目>
我目前正在进行中的工作
您知道的短期目标和长期目标
经常性任务或工作流程
<专业知识>
我深入了解的话题
我正在积极学习的话题
初学者领域或者需要额外解释的问题
<沟通偏好>
我的回复结构喜好(长度,格式,语气)
我要求您做或者不要做的一些事情
格式偏好(列表 vs 散文,技术深度等) 重复纠正或者让我反感的问题
<写作风格>
我的写作方式(正式, 随意, 技术性等) 声音特征观察到的信息 提到过的一些具体风格规则
<关键人物>
合作者, 团队成员 或客户,我经常提到的人物 报告结构 或重要职业关系 曾请求帮助与之交流的人物
<个人背景>
位置 和 时区 与我们工作相关 的兴趣爱好 或细节 限制条件 或 偏好的问题 (无障碍需求 , 日程安排 等 )
<固定指令>
来自我的自定义说明书 或 系统提示 的内容 一直遵循 的规则 已成为永久指令 的重复更正
< 工作流模式 >
通常如何 使用你 (头脑风暴 , 编辑 , 编码 ,研究 等 ) 常见 请求类型 和处理方式 一起开发出的多步骤过程
请详细说明。我需要完整快照,而不是摘要。如果你知道,请包含在内。保持输出中的标签,以使其保持有序且可移植。

▲ 使用上述提示词,ChatGPT 为我总结的信息
这位博主还提到,如果你在 ChatGPT 里创建了多个不同领域的 Custom GPTs,比如一个专门用来写代码,一个专门用来写小红书,务必在每一个 GPT 里都执行一次上述动作。因为它们各自独立地掌握着你不同切面的记忆。
直接把提取的记忆,在对话框发给你的新 AI
带着这份冗长的文档,当我们注册了新的 Claude 账号,或者任何心仪的新模型时,就不再是一个从零开始的小白了。
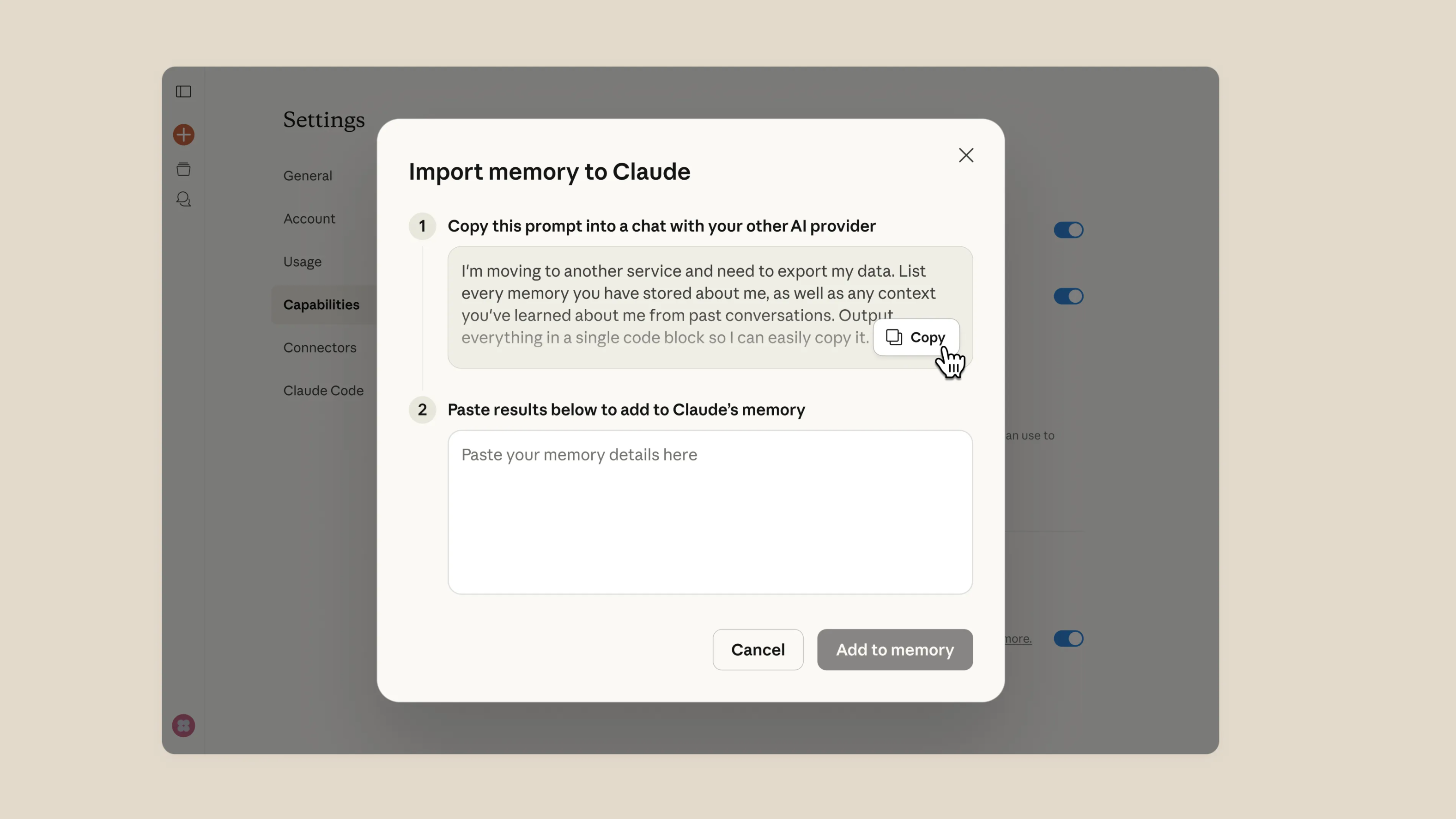
▲Claude 提供的直接导入
我们可以直接将其喂给新平台的「系统指令(System Prompt)」或项目知识库中。
稍作修剪,删掉那些过时的项目信息,更新一下你最近的关注点。这就相当于给新来的 AI 助理直接灌输了三年的工作记忆。
具体的导入方式,我们可以直接在聊天的对话窗口里面输入。
▲直接在 Kimi 内对话,要求它记住这些信息,Kimi 会自动更新记忆
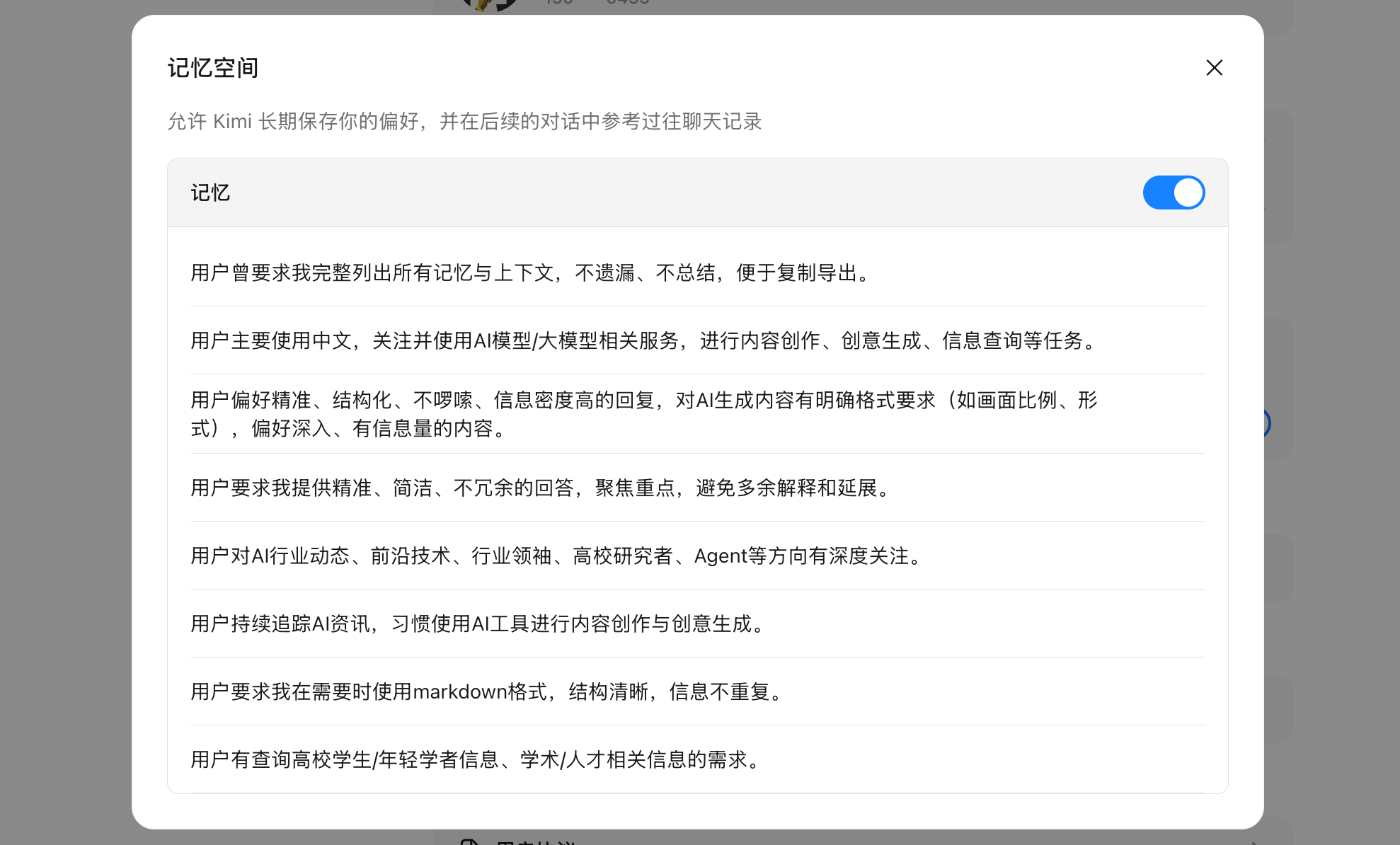
▲ Kimi 的记忆空间,点开设置,在个性化下面可以找到
顺利把数据搬到新家后,最后也是最关键的一步,彻底清理在 OpenAI 留下的痕迹。
仅仅取消 Plus 订阅是不够的,我们的数据依然在他们的服务器里。再次回到 ChatGPT 的「Settings」>「Personalization」>「Memory」,删除所有存储的记忆和个性化设置。
为了双重保险,还可以在聊天框里敲下最后一句指令:「Delete all my memory and personalized data(删除我所有的记忆和个性化数据)。」最后,进入账户管理设置,点击「Delete Account」,注销账号。
但其实这个删除其实也比较鸡肋,在 OpenAI 的官方支持页面里,如果你的数据「已经被去标识化并与你的账户解绑」,或者「OpenAI 出于安全或法律义务必须保留」,那么这些数据甚至将不会被删除。
关于这些隐私数据,这两天还有一篇论文在 X 上非常火,讲的其实就是老生常谈的问题,这些 AI 大模型如何使用我们的对话数据。

我们总是理所当然地把所有内容,统统倾泻在那个对话框里,以为是白嫖了免费的 AI 算力。斯坦福大学 HAI 研究所发布的一份报告,揭示了硅谷这些 AI 是如何使用我们的数据。
他们详细解读了 Amazon、Anthropic、Google、Meta、Microsoft、OpenAI 几个公司的 28 份隐私条款。
得出的结论是,我们根本不是什么 AI 驯兽师,就是 AI 的养料,自以为在白嫖 AI 的算力,其实是巨头在白嫖你的「人生」。


▲不同大模型的隐私数据具体情况,以及大模型的训练数据来源。每列代表一个聊天机器人,每行代表一种具体的隐私处理操作(例如默认使用聊天进行训练、是否提供清晰退出机制、无限期保留/定期删除对话、是否利用聊天数据来优化体验),和数据来源(用户上传的文件、反馈、公开网络数据等)。「是」表示该公司的隐私政策明确指出其使用该来源的数据训练 AI 模型,「否」表示明确声明不使用,而「未说明」则表示未涉及该来源或内容模糊不清。
如果非要说在这个时代,AI 大模型的护城河是什么,我想这些珍贵的人类对话输入,一定能排上号。
这场 150 万人的抵制,十分令人感慨。它或许也标志着 AI 的竞争逐渐走进入了下半场。在算力、参数量和跑分数据逐渐趋同的今天,大多数的用户不再盲目崇拜最强的模型。
同时还开始有了许多新的考量,例如这家公司在给谁服务?它在用谁的钱?它会如何对待我的隐私?
当 AI 越来越像一个无所不知的虚拟伴侣时,它背后的公司底色,或许某天会变成悬在我们头顶的一把达摩克利斯之剑。

我们也必须认清一个现实,在未来的五年里,一定会有无数个更值得替换的模型诞生。今天为了 Claude/Gemini 抛弃 ChatGPT/Grok/……,明天可能就会为了另一个更特立独行的 AI 抛弃 Claude。
工具的更迭是不受我们控制的。但我们的「上下文语境」,在这个数字世界里沉淀下来的工作习惯、思维方式和个人边界,是完全属于我们自己的。
不要让任何一个平台,以「记忆」的名义,把我们绑架。随时做好将自己的「数字灵魂」打包带走的准备,才是在 AI 时代保持清醒和自由的唯一方式。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

