

刚刚,DeepSeek V4基准测试泄露!疑似明天发布,全场惊呼新王归来

新智元报道
编辑:Aeneas kingHZ
【新智元导读】DeepSeek V4,据说明天就要上线了?这是首个匹敌顶尖闭源模型的开源模型,被网友评为「一鲸落万物生」。泄露的基准测试显示,它在SWE-bench Verified上取得了83.7%,已经超越Opus 4.5和GPT-5.2!
就在刚刚,一张图在全网疯狂刷屏了!
据说,DeepSeek V4的基准测试已经泄露,整个AI圈都震了。
有大V总结道:AI编程大战,已经达到了新的高峰。
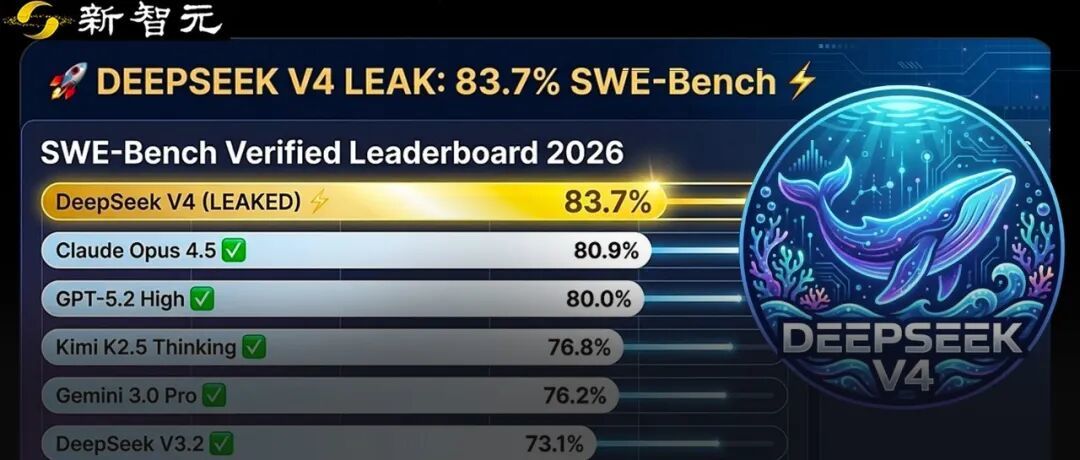
泄露信息显示,DeepSeek V4在SWE-bench Verified上取得了惊人的83.7%,超过了Claude Opus 4.5(80.9%)和GPT-5.2(80%)。
可以说,100万+上下文长度+Engram记忆机制=真正的全仓库级推理能力。
他惊呼:闭源模型占据主导的时代,是否正在走向终结?
同时泄露的,还有下面这一张图。
其中,它的SWE-Bench Verified得分,达到了83.7%。如果这个数字最终被确认,将直接改写当前「最强代码模型」排名!
相比之下,其他模型的得分都比较落后——
DeepSeek V3.2 Thinking:73.1%
GPT-5.2 High:80.0%
Kimi K2.5 Thinking:76.8%
Gemini 3.0 Pro:76.2%
这不是小幅领先,而是直接跃升到第一梯队顶端!
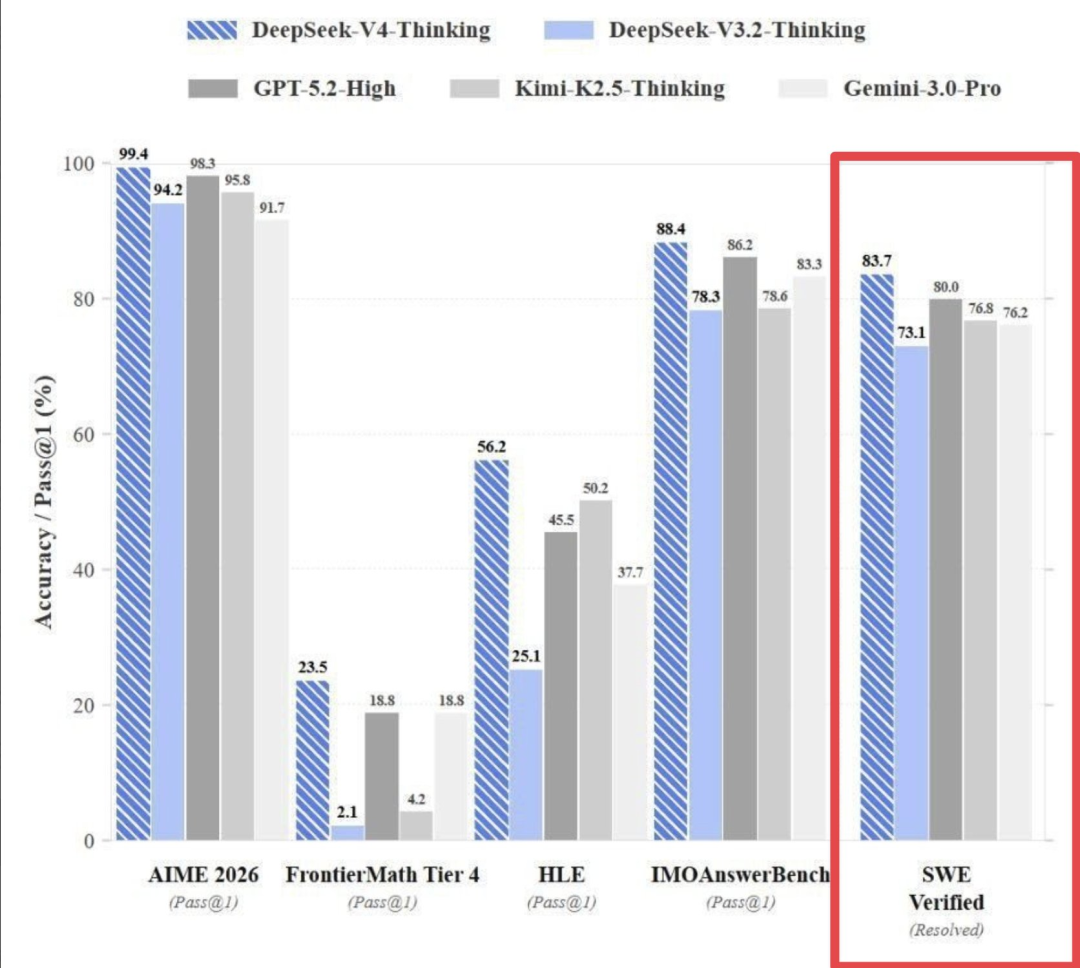
不仅如此,真正令人警惕的,并不只有编程能力,V4的其他分数也很惊人。
AIME 2026:99.4%
IMO Answer Bench:88.4%
FrontierMath Tier 4:23.5% (直接达到GPT-5.2的11倍)
这意味着什么?
如果这些数据属实,DeepSeek V4不是「又一个强模型」,而是一次能力曲线的陡峭抬升!
它可能会同时在代码、竞赛数学、前沿数学推理三个高难度维度上,刷新现有天花板。
还有网友综合了全网DeepSeek V4消息,不仅在HumanEval、SWE_bench、上下文和成本上刷新成绩,而且发布时间预计在春节,也就是明天!
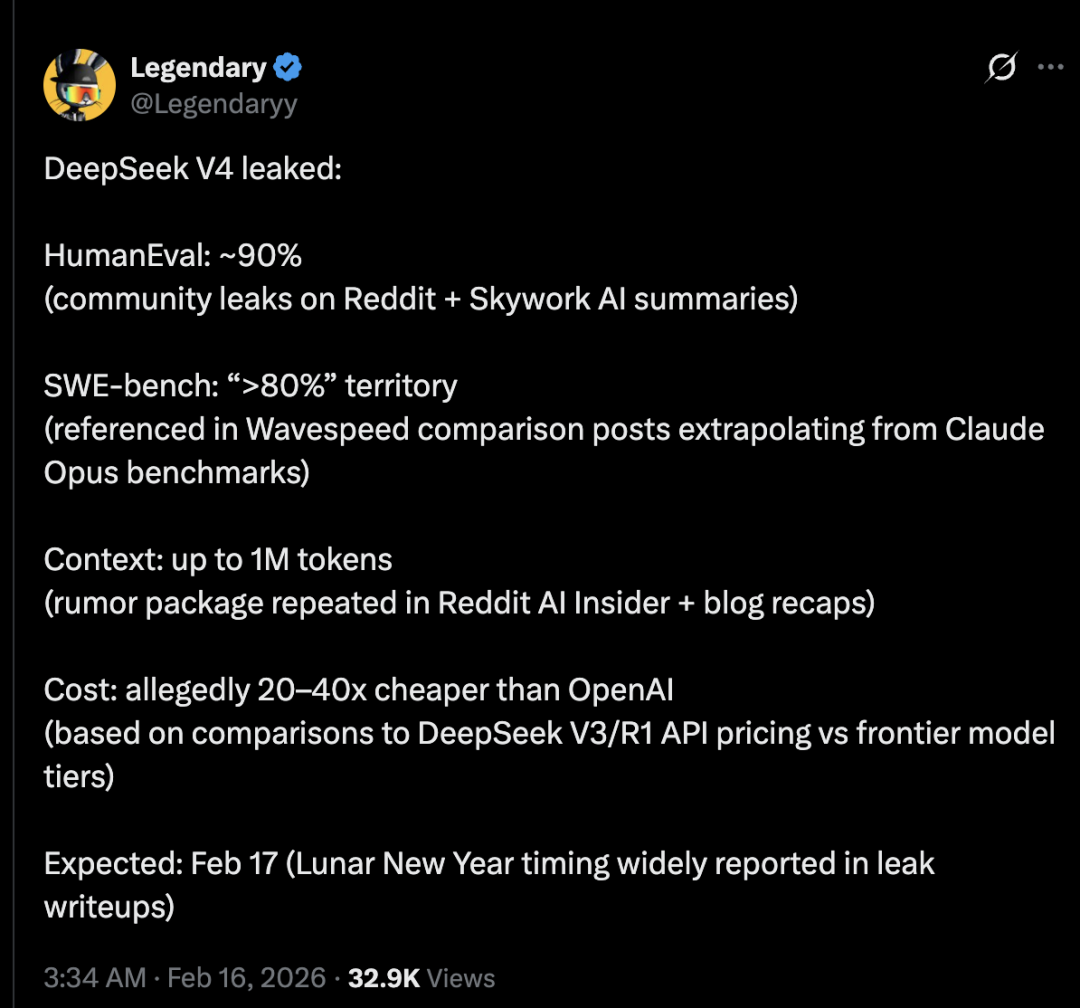
HumanEval:约90%(来自Reddit社区泄露 + Skywork AI总结)
SWE-bench:进入「>80%」区间(在Wavespeed对比帖中引用,根据 Claude Opus 基准推测得出)
上下文长度:高达 100 万 token(在Reddit AI Insider和博客总结帖中反复出现的传闻)
成本:据称比OpenAI便宜20到40倍(根据DeepSeek V3/R1 API 定价与前沿模型层级的对比推算)
预计发布时间:2月17日(农历新年期间,泄露文章中广泛报道)
如果是真的,DeepSeek将又一次改变游戏规则。
总之,DeepSeek V4的发布时间,很可能是周一。据说,这是首个不落后于闭源顶尖模型,甚至能与之匹敌甚至超越的模型。
有人说,以DeeepSeek-V4为代表的开源模型需要跨越的差距越来越大了!
很期待,当V4等中国开源模型发布后,这一差距会如何随着时间演变。

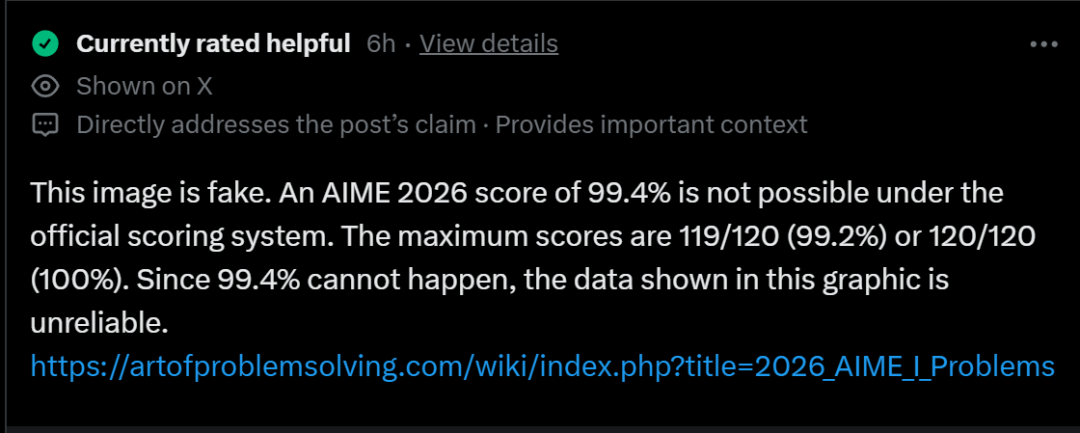
被打假了?
不过,这几张流传出来的基准测试,很快被怀疑是假的。
比如在官方评分系统下,不可能有模型达到99.4%的分数。最高分只能是119/120(99.2%)或 120/120(100%)。
另一个证据,就更加增加了这几张基准测试的可疑性。
Epoch AI也确认,FrontierMath的数据是伪造的,因为只有他们和OpenAI有权对该数据集进行评估。至少有两个基准测试被打假,证明这些图可信度确实不高。

而且,据说DeepSeek新模型的官方发布时间,已经被推迟到了三月底。
如果模型本体还在封闭开发阶段,那么所谓83.7%的 SWE-Bench Verified,是基于哪个版本跑出来的?是内部原始checkpoint?还是已经定型的最终权重?

另外,对于如今的大模型,分数本身并不是终点,「收据」才是关键。
这个83.7%的分数是怎么跑出来的?是否做了pass@k报告?软件工程实验台的工具栈如何配置?使用了什么版本的harness?是否基于最新数据集版本评估?有没有做污染检查?失败案例如何分解?
如果没有这些细节,所谓的第一名,也只是一个数字而已。

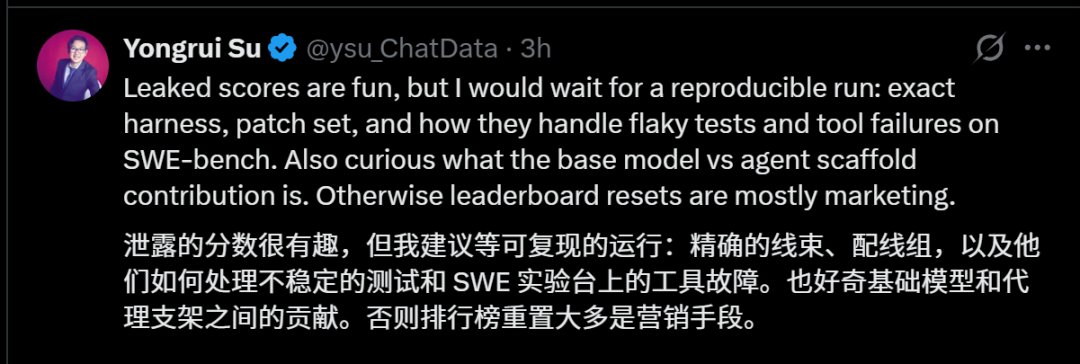
另外,就算泄露的分数很惊人,但真正有说服力的,是可复现的运行细节。
比如,精确的评测线束、配线组、不稳定测试如何处理、SWE实验台上工具调用失败如何重试?基础模型本身的能力贡献有多少?代理框架又放大了多少性能?
否则,这种所谓的刷新排行榜,就只是更像一次市场营销行为。
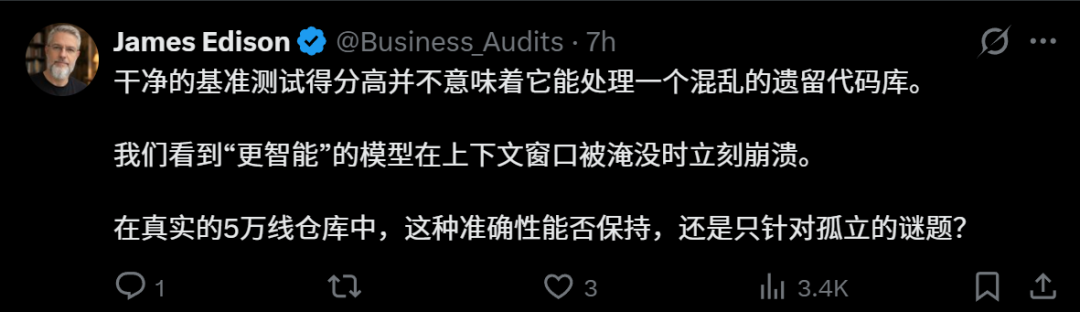
还有人提出,技术基准测试得分提高,也不意味着能驾驭现实中混乱的代码库。很多所谓更聪明的模型,在上下文窗口被塞满后,就迅速崩溃了。
有趣的是,即便是假的,这也说明DeepSeek的确「深得人心」,网上的夸大其词的「泄露」就是DeepSeek成功最大的标志。

不过,DeepSeek V4的上下文,一定是一个杀手锏。

100万长上下文来了,
其他还会远吗?
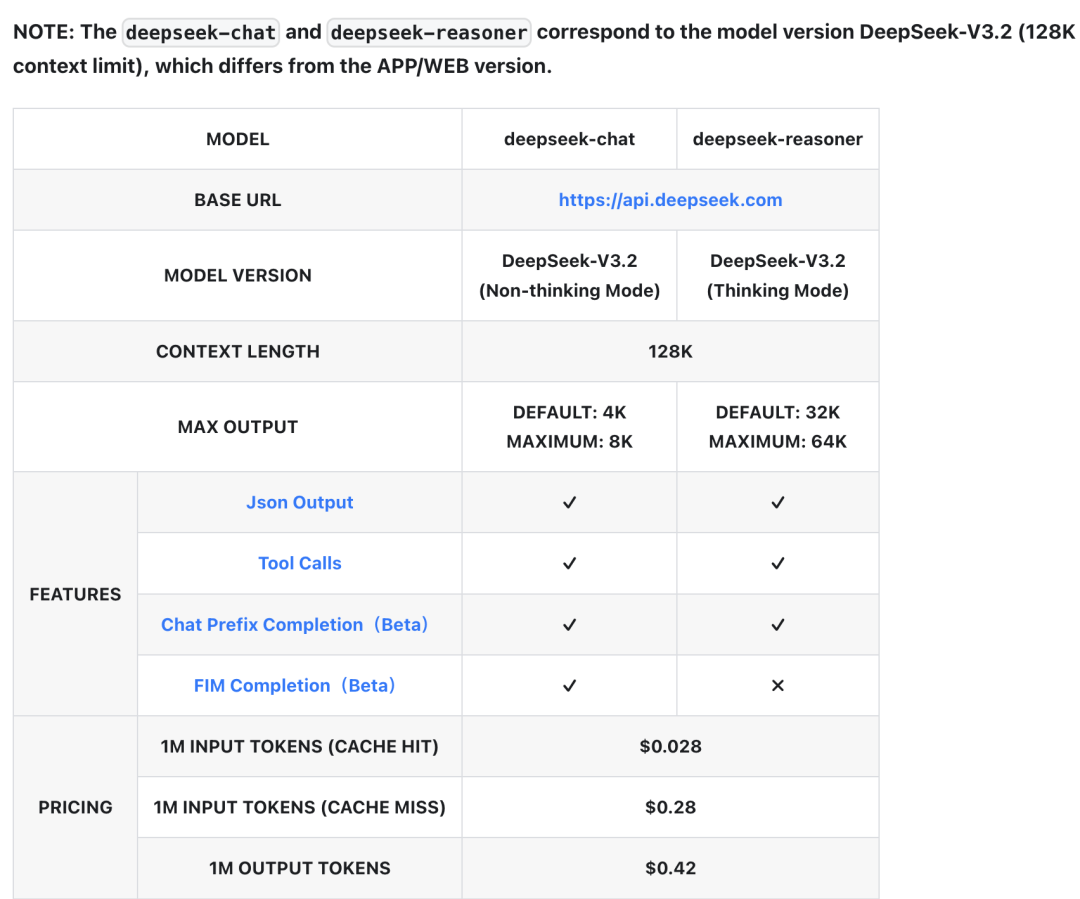
最近,已经沉寂已久的DeepSeek,忽然在官网和移动应用上推出了新模型的灰度测试。
根据流传的信息,该默写的参数可能仅为200B,且未采用DeepSeek与北大联合开发的Engram条件记忆机制。
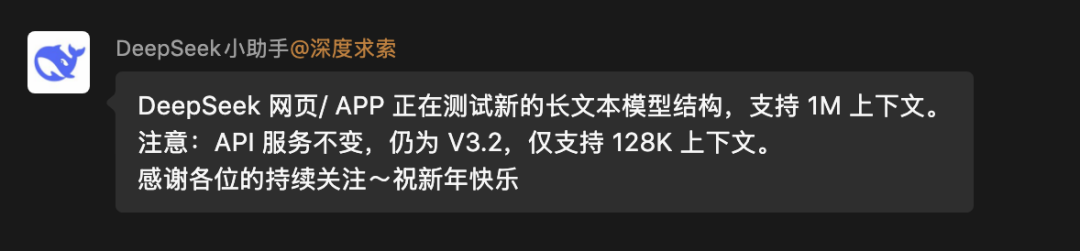
但只要通过简单的测试就会发现,这个新版本有一个大突破——超长的上下文窗口,包含100万个token,可以一次性处理《三体》三部曲体量的长文本。
奇怪的是,API文档并没有更新,上下文长度依然为128K。
Hugging Face、GitHub上,DeepSeek完全没有更新任何消息。
业内普遍猜测,DeepSeek很可能在测试V4-lite版。
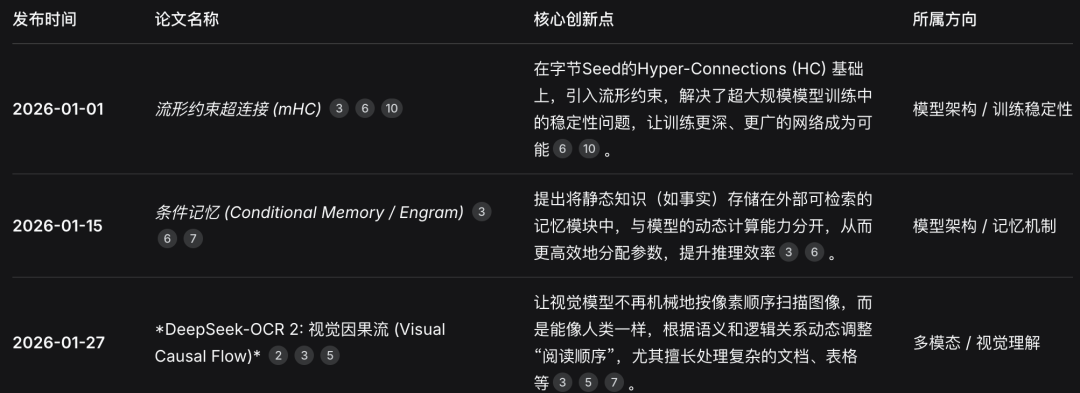
在DeepSeek V3的基础上,国产模型已经刷新了开源最好成绩。
深入研究代码后,Meta科学家Zhuokai Zhao得出观察结论:
LLM架构的前沿探索已基本收敛。
……
MLA + sigmoid =稀疏专家(MoE)+ 共享专家 + 无辅助损失 + DSA + MTP正成为前沿稀疏专家模型的标准配方。
……
设计空间已被充分探索。

而DeepSeek不仅更新了上下文,在V3.2版本之后,在模型架构、记忆和视觉推理上,持续输出,不断创新:
100万上下文长度,很可能就是DeepSeek的另一个绝招。

这次的低调测试,或许就是DeepSeek大更新的「试点」,是招「妙手」。
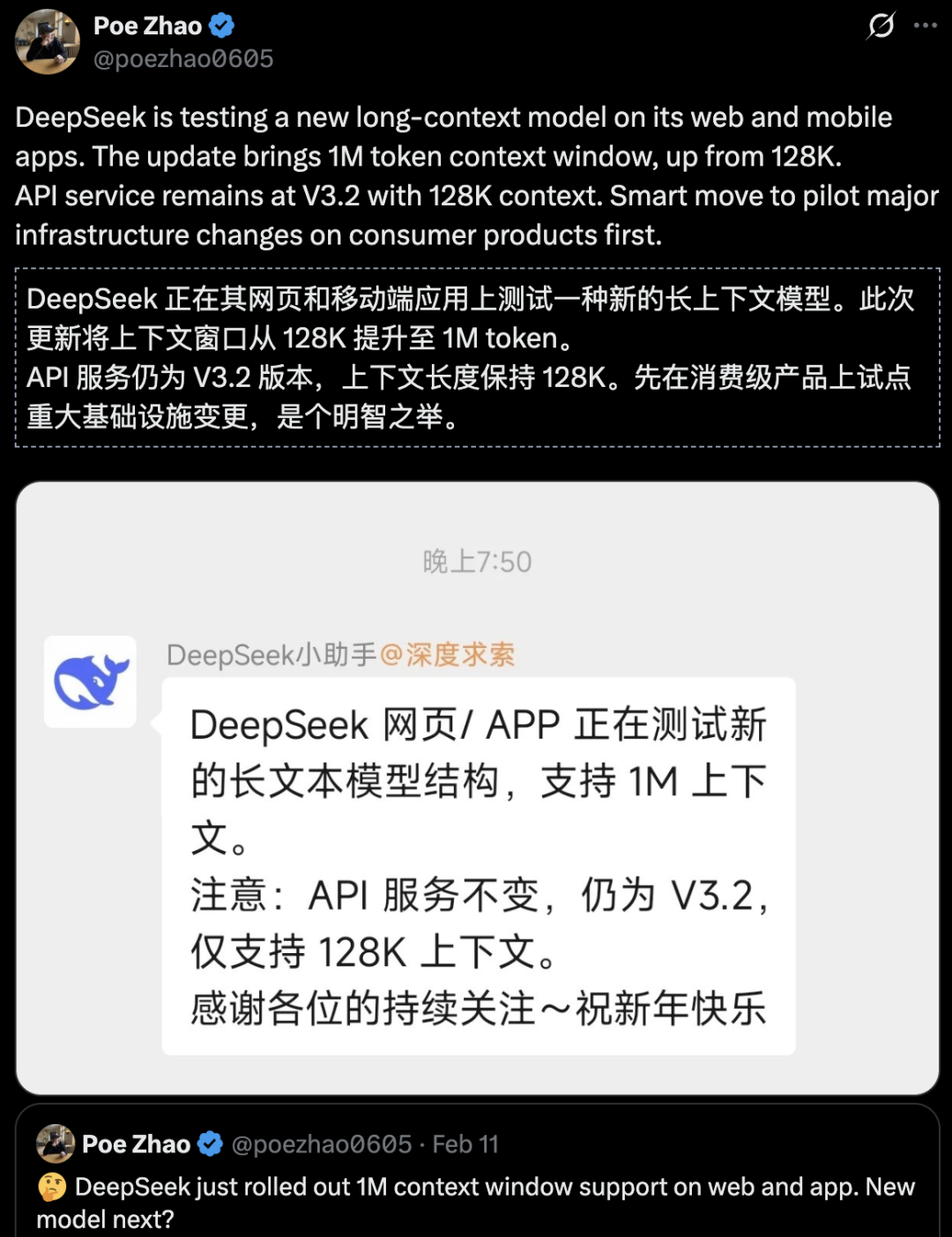
100万token上下文都来了,其他还会远吗?
总之,大家对DeepSeek V4充满期待:
DeepSeek V4,
全新编程之王!
另外,在一个overchat.ai的网站上,我们也发现了不少关于DeepSeek V4的蛛丝马迹。
根据这个网站的信息,DeepSeek V4预计将在2026年2月17日发布,配合春节发布。(什么逆天操作)

DeepSeek员工的内部测试显示,V4 在编码任务方面可能超越Anthropic的Claude和 OpenAI的GPT系列。关键的基准是SWE-bench,Claude Opus 4.5目前以80.9%的得分领先。

DeepSeek预计将以开放权重模型形式发布V4,延续一贯的开源传统。
DeepSeek V4提供仓库层级推理——能够理解一个文件中的变化如何影响项目中其他文件,这对处理大型代码库或复杂分布式系统的开发者尤其有价值。
另外,DeepSeek V4还引入了新的Engram条件存储系统,实现近乎无限的上下文检索,使其能够处理极长的编码提示,并在大型代码库中保持上下文。

网站介绍说,DeepSeek V4自诩为专业的“编程之王”挑战者。
DeepSeek之前的模型,尤其是V3和R1,证明了开源AI模型可以以极低成本与专有模型竞争。V4预计将在这一成功基础上,拥有更令人印象深刻的编码能力。
四大核心突破,成为游戏规则巅峰者
除了上下文更新外,DeepSeek手里还有这些牌——Engram、mHC、DAS 2.0……
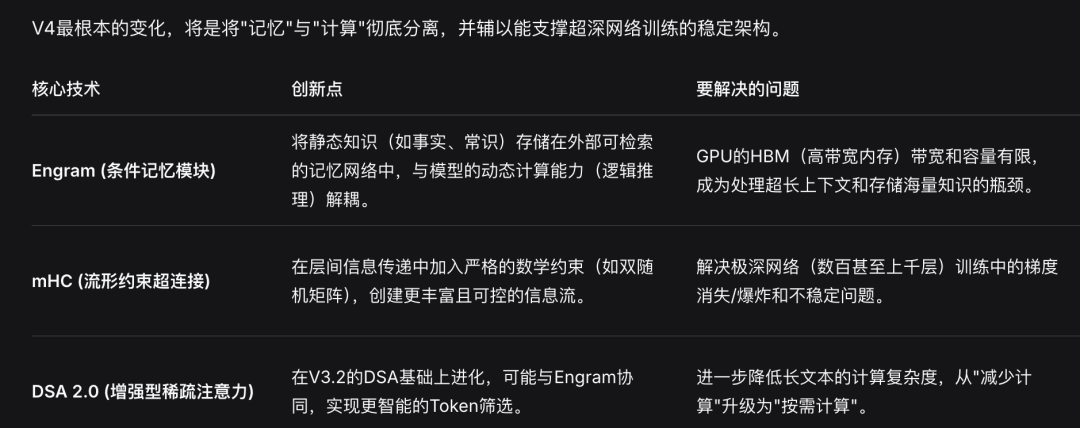
不知道DeepSeek V4能带来哪些新的惊喜!
上个月初,Information爆料称,DeepSeek计划在2月中旬,也正是春节前后,正式发布下一代V4模型。

V4的最大提升,就是在编程能力上。它的编码实力,据说可以赶超Claude、ChatGPT等顶尖闭源模型。
而以下四个方向,就是它实现的核心突破,堪称game changer的级别。
编程能力:剑指Claude王座
2025开年,Claude一夜之间成为公认的编程之王。无论是代码生成、调试还是重构,几乎没有对手。但现在,这个格局可能要变了。
知情人士透露,DeepSeek内部的初步基准测试显示,V4在编程任务上的表现已经超越了目前的主流模型,包括Claude系列、GPT系列。
如果消息属实,DeepSeek将从追赶者一步跃升为领跑者——至少在编程这个AI应用最核心的赛道上。
超长上下文代码处理
V4的另一个技术突破在于,处理和解析极长代码提示词的能力。
对于日常写几十行代码的用户来说,这可能感知不强。但对于真正在大型项目中工作的软件工程师来说,这是一个革命性的能力。
想象一下:你有一个几万行代码的项目,你需要AI理解整个代码库的上下文,然后在正确的位置插入新功能、修复bug或者进行重构。以前的模型往往会忘记之前的代码,或者在长上下文中迷失方向。
V4在这个维度上取得了技术突破,能够一次性理解更庞大的代码库上下文。
这对于企业级开发来说,是真正的生产力革命。
算法提升,不易出现衰减
据透露,V4在训练过程的各个阶段,对数据模式的理解能力也得到了提升,并且不容易出现衰减。
AI训练需要模型从海量数据集中反复学习,但学到的模式/特征可能会在多轮训练中逐渐衰减。
通常来说,拥有大量AI芯片储备的开发者可以通过增加训练轮次来缓解这一问题。
推理能力提升:更严密、更可靠
知情人士还透露了一个关键细节:用户会发现V4的输出在逻辑上更加严密和清晰。
这不是一个小改进。这意味着模型在整个训练流程中对数据模式的理解能力有了质的提升,而且更重要的是——性能没有出现退化。
在AI模型的世界里,没有退化是一个非常高的评价。很多模型在提升某些能力时,会不可避免地牺牲其他维度的表现。V4似乎找到了一个更优的平衡点。

