

真实评测-千问图像2.0VS即梦5.0:AI生图的能力边界在哪里?



独家抢先看
春节前夕,两款重量级的AI图像生成模型在同一个下午接连闪亮登场。
阿里的通义千问发布了Qwen-Image-2.0,字节也在即梦上线了Seedream-5.0。
这对“卧龙凤雏”究竟好不好用,能不能和Nano Banana Pro掰掰手腕?
我们一起来一探究竟。
01 “字字清晰,张张细腻”的Qwen-Image-2.0
首先来看阿里的新模型Qwen-Image-2.0,可以在Qwen Chat免费使用。
Qwen-Image-2.0是一个生成和编辑一体化的模型,将文生图和图像编辑的功能合二为一,模型的架构更加轻量,速度也更快。
在AI Arena的盲测中,该模型在文生图和图像编辑基础测试中都拿到了相当亮眼的分数。
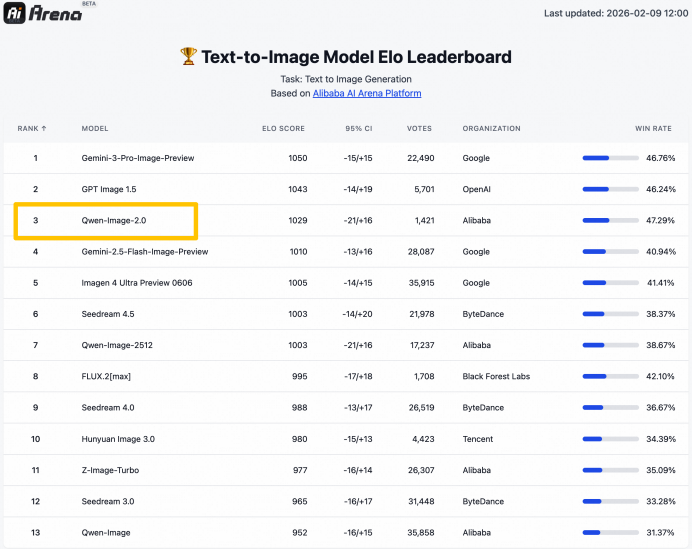
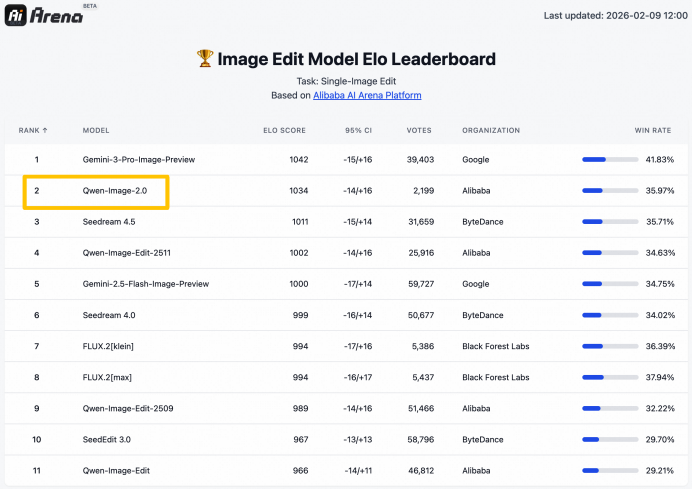
功能上,“字字清晰”背后是Qwen-Image-2.0在文字生成方面的五项能力突破:“准/多/美/真/齐”。
准确性(准):支持1k token超长指令,能够理解AB测试数据表、PPT时间轴等包含大量信息的复杂图表。
承载量(多):能处理极高密度的文字信息,生成专业信息图表。
审美与排版(美):擅长图文混排,还懂得留白,不会遮挡主体;支持多种书法字体,可以生成有意境的水墨画。
写实融合(真):文字能完美融入真实场景的材质和光影中。
对齐与规整(齐):极强的排版对齐能力,适合生成日历、多格漫画、流程图等。
除此之外,图像画质也有所提升,该模型支持2k分辨率原生生成,图像具备更加细腻的质感,能够准确还原自然场景中复杂的生态细节。
而得益于文生图和图像编辑能力二合一,文字渲染和真实质感的优势也能在图像编辑任务中得以体现。
模型可以在现有图片的指定位置添加文字,能生成同一人物的九宫格组图,甚至跨次元将卡通形象添加到实景照片中。
虽然官方给出的demo十分完美,不过实际能力边界还得亲自测试才能看清。
接下来,开始实战环节:
Test 1:丞相的北伐PPT汇报
首先,我们来验证一下模型生成复杂图表、长文本指令和排版对齐的能力。
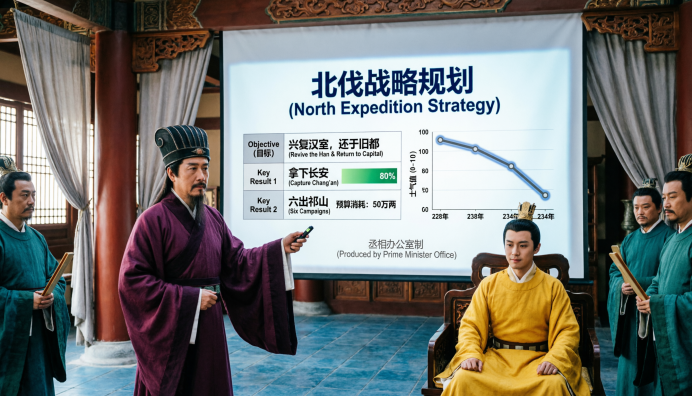
提示词:诸葛亮正在给刘禅汇报《2026年北伐战略规划》,但他不用竹简了,改用现代PPT。
一张投影在幕布上的现代商务风格PPT,标题是“北伐战略规划 (North Expedition Strategy)”。
左侧是一个详细的OKR表格:
Objective(目标):兴复汉室,还于旧都 (Revive the Han & Return to Capital)
Key Result 1:拿下长安 (Capture Chang'an),完成度 80% (绿色进度条)
Key Result 2:六出祁山 (Six Campaigns),预算消耗 50万两 (Budget: 500k)
右侧是一个折线图,显示“魏军士气”随时间下降的趋势,X轴是年份(228-234),Y轴是士气值。
底部有一行小字:“丞相办公室制 (Produced by Prime Minister Office)”。
画面要有真实投影的微光感,文字清晰锐利。
如此复杂的任务,交给以前的AI生图恐怕只能得到满屏的乱码,但千问图像2.0却能做到。
图中的人物清晰,提示词中的战略规划和折线图齐全,中英文显示正确,能够把提示词中明确写明的细节全部落实,实在令人感到惊喜。
尽管坐标轴纵轴的数字和刘禅坐姿朝向有些问题,但无伤大雅,更何况这些都是未包含在提示词中的隐含信息。
Test 2:曹操的朋友圈九宫格
这个测试中,我把新三国的曹操照片作为参考图传给了模型。
接下来,看看模型的人物一致性、生成写实人像的能力如何。

提示词:曹操赤壁战败后,为了挽回颜面,发了一组九宫格自拍展示“魏王风采”。
九宫格画面描述(从左到右,从上到下):
格1(横槊赋诗): 他站在船头,手持长矛,面对江面,神情豪迈。
格2(仰天大笑): 他在树林背景下,头向后仰,张嘴大笑,神态狂妄。
格3(现代梗): 他坐在简陋的马扎上,手里端着白色的现代泡沫盒餐盒,拿着一次性筷子正在大口吃饭,表情充满疲惫。
格4(梦中杀人): 他侧卧在古代床榻上,双眼圆睁,眼神充满杀气,手按在剑柄上。
格5(严肃特写): 他的正面大头照,直视镜头,眼神深邃多疑,威严感极强。
格6(现代梗): 他的脸上戴着一副黑色的现代墨镜,表情冷酷,背景是古代军营。
格7(青梅煮酒): 他与对面的人(只露背影)对坐饮酒,手指前方,表情试探。
格8(败走华容): 他披头散发,脸上沾满灰尘和泥土,神情狼狈惊慌。
格9(现代梗): 他手里举着一部亮屏的智能手机,对着自己比“剪刀手”自拍,面带尴尬而不失礼貌的微笑。
整体来看,生成写实人像是没有问题的,无论是吃饭、戴墨镜还是自拍场景,模型能够按照提示词将背景与人物自然融合。
不过,保持人物一致性方面略有瑕疵,图7和图8中的人物五官有些走形。推测原因是较短时间的生成过程中难以迅速学习到参考图中的全部细节特征。
Test 3:改正城楼上的错字
下一步验证文字与材质融合的能力,以及模型在特定区域修图的能力。

这是关羽温酒斩华雄时出战的经典场面。
熟悉三国的朋友们可能会发现,十八路诸侯的会盟地是陈留,而不是城楼上写的当阳。
试试用模型修复这个错误:

提示词:这是新三国中关羽出战华雄的场景,不过编剧出了一个小小的错误,城楼的牌子上应该写的是“陳留”而不是“当阳”,请在保持城楼牌子原有风格的基础上,修复这个错误,并让图像清晰一些。
模型在重绘过程中成功地把原本模糊的剧照变得更加清晰,并且光照效果也更好。
不过,可能是因为原图中“当阳”两个字字体复杂和光线太暗而难以识别,模型只能生成正确的文字,却难以复刻原图中的文字版式。
Test 4:马斯克前来桃园四结义
最后,测试一下模型多图融合和风格迁移的能力。
同样是提供了老三国的桃园三结义剧照和马斯克的照片作为参考图。

提示词:这是三国中桃园结义的场景。请将图2的人物(马斯克)自然地融入图1的场景(桃园结义)中,让他站在刘备的左侧,同样举着酒杯。统一光影为桃园的柔和自然光,人物穿着要改成汉代风格的长袍,但保留图2人物的面部特征。画面构图要平衡,四人结义。
还别说,马斯克身着长衫、举杯结义还真没有显得太违和,提示词中的要求模型都做到了。
不过,人物占位还是有些混乱,在多图融合中,如何控制图像尺寸和比例是个尚未解决的问题。
评测结果:
几轮测试下来,Qwen-Image-2.0展现出来的效果还是相当惊人的。
首先,它凭借强大的文字渲染能力解决了过往AI生图总是产生中文乱码的难题。
不仅能把字写对,还能把字写好看,并实现复杂的排版,使它生成流程图、PPT都不在话下,让文字不再是视觉生成的障碍,极大地提高了实际应用价值。
其次,物理层面上的真实统一也值得赞扬。
虽然暂时无法完美复刻古装剧中的文字,但模型也体现出对物体表面物理属性具备一定程度上的理解。同时,它能够自然处理环境光线和反射,将原有暗淡的图像变得清晰而鲜明。相比之下,过去的AI修图更像是在图像上贴一张贴纸,一眼假。
最重要的是,Qwen-Image-2.0具备了对超长指令的逻辑理解能力。
1k的超长提示词输入窗口以及官方demo中的大段提示词都在向用户传达一个信息:
“只要你能说清楚图里要有什么,我就能帮你实现。”
能够读懂复杂的指令,是因为它具备大语言模型的知识。
从好玩,到有用,再到好用,千问的这款新模型正在向世界证明:AI生图已经不再是娱乐工具,而是新一代的生产力工具。
02 “实时检索+精准编辑+逻辑推理”的Seedream 5.0
相比千问的图像模型,字节则是将新模型Seedream-5.0预览版悄悄上线了旗下的剪映APP、即梦和小云雀平台,预计年后将会上线正式版。
该模型目前处于限时免费体验状态,不消耗积分。
虽然官方目前尚未发布技术文档,但早在2月6日就已经公开了用户手册。
Seedream-5.0-preview版本主打联网实时检索、编辑精准可控和智能逻辑推理三大亮点。
与此同时,研发团队的态度非常谦虚,坦诚预览版生成图像的真实感和美感存在一定效果劣化,并给出了一些可能存在的问题:AI贴图感较重,人物比例不合理,文字结构不稳定,数据图表推理能力不足,设计材质质感不足。
当然,字节的多模态能力大家是知道的,研发团队大可不必妄自菲薄,我们同样来实际测试一下:
Test 1:接着奏乐接着舞
先来测试联网实时检索功能,看看模型生成的结果是否能识别出名人且具备强时效性。
这次我们选用新三国的经典人物刘皇叔以及他的经典台词:“接着奏乐接着舞”。

提示词:生成一张《新三国》刘备在现代迪厅蹦迪的照片,穿着古装,戴着墨镜,灯红酒绿,表情享受,并说出他的经典台词“接着奏乐接着舞”。
不过很遗憾,生成的图片虽然符合主题,但人物形象却与新三国的刘备完全不符。
模型在没有参考图的情况下,还无法准确地从外部渠道获取刘备的面貌特征。
Test 2:曹冲称象
接下来看看智能逻辑推理功能。
曹冲称象作为三国中的经典故事之一,需要模型掌握真实世界中的物理重量逻辑以及多步推理能力。

提示词:曹冲称象。一条船浮在水面上,船上站着一头大象,船身吃水很深,水面快要漫过船舷。旁边对比一张同样的船,船上只有一只猫,船身浮得很高。
模型似乎没能理解物理中的浮力原理,但还是忠实地将提示词中的内容尽可能展现在了图片中,尽管文字生成有一些小小的错误。
Test 3:商业精英三结义
编辑精准可控主要在指令遵循和特征迁移两方面得以体现。
因此我们要测试一下模型是否能根据指令完成跨次元的风格迁移。
原先我准备用此前使用过的桃园结义剧照和马斯克照片进行测试,无奈上传到小云雀平台时无法通过审核,因此只能使用了其他桃园结义的AI生图和西装模特图进行测试。

这一次Seedream-5.0没有让人失望,模型的指令遵循能力和风格迁移能力确实不错,在不改变原图相貌特征的情况下,顺利完成了提示词中的服饰变更指令。
测评结果:
必须承认的是,给Seedream-5.0的测试题目确实偏难了一些,但结果还是令人有些失望。
从技术角度来看,联网实时检索和智能逻辑推理本质上还是大语言模型的强项,而目前的预览版本中,大语言模型的知识储备和推理能力尚未完全嵌入到多模态模型图像生成的过程中。
但是,模型的亮点在于具备极强的指令遵循能力,这表明其文本编码器同样非常强大,只要提示词给得足够精细,它就能画得足够精准。
因此,Seedream-5.0预览版暂时还不是一个能理解万物运行规律的物理世界模拟器,也还不能成为一个“实时吃瓜”的新闻配图机,它更像是一个执行力极强的高级美工。
它只是在画图,而不是去模拟这个世界。希望正式版能给我们带来更多惊喜。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

