

日本芯片,“复仇”韩国?

过去三十年,全球存储产业版图完成了一次残酷而彻底的权力更替。
20世纪80–90年代,日本企业几乎垄断DRAM市场;进入21世纪后,这一王座被韩国厂商夺走,并由此建立起横跨技术、规模与资本的长期统治。今天,HBM 成为 AI 算力体系中最稀缺、最赚钱的核心器件之一,韩国厂商坐享红利,而日本却基本缺席。
然而,就在大家以为日本存储已经“躺平”时,一家极具野心的本土企业正浮出水面。
被韩国改写的存储史
日本曾是DRAM的代名词。
上世纪 80 年代,日本的几家存储企业合计占据全球 DRAM 市场过半份额。DRAM几乎等同于日本半导体工业的名片。当时的日本,正处在制造业全球扩张的巅峰期。汽车、家电、精密仪器、机床、消费电子几乎在所有工业品门类中都具备国际竞争力,而半导体则是这套工业体系中技术密度最高、附加值最高的一环。
在此我们再来老生常谈下,日本是如何成为DRAM霸主的。1970–80 年代,日本政府通过 MITI(通产省)主导了一系列国家级半导体联合研发计划:包括超大规模集成电路(VLSI)国家项目、企业之间共享基础工艺成果、大企业联合高校与研究机构协同推进。这套体系催生出一批在工艺、材料、设备、制造管理上极为成熟的公司:如NEC、东芝、日立、富士通等企业。
在1980年代中后期,日本厂商一度占据全球DRAM市场50%以上份额。
日本模式的核心特征可以概括为三点:
第一,工艺导向。日本厂商非常强调制程细节、器件可靠性与长期良率稳定,而不是单纯追求“最小节点”。
第二,制造纪律。极端重视良率曲线爬坡速度、设备稳定性、产线一致性。
第三,产业协同。材料、设备、晶圆制造、封测之间形成高度黏合的国内产业链。
在那个阶段,DRAM的竞争本质上是:谁能更快、更稳定地把工艺做到量产良率。日本对此具有天然优势。
日本为何会失去 DRAM 王座?
转折点出现在1990年代。这一时期,日本经济泡沫破裂,企业进入长期资产负债表修复期,资本开支趋于保守。
与此同时,DRAM行业发生了结构性变化:市场开始走向周期性强波动,产品逐渐标准化、同质化,而且价格竞争愈发激烈。
DRAM 从技术溢价型产品,逐步变成高资本开支+高周期波动+低毛利容忍度的重资产行业。这对日本企业极为不利,因为日本企业普遍追求稳健回报,难以接受长期亏损换规模,更偏向“盈利性制造”,而非“战略性亏损扩张”。
再加上美国对日本半导体实施贸易限制,日本厂商在对美出口上承受额外压力,进一步削弱了扩张能力。结果是,日本厂商在1990年代逐步退出DRAM主战场,将资源转向逻辑芯片、MCU、功率器件、传感器等领域。
而韩国后来居上,靠的是另一套逻辑:以三星为代表,韩国政府与财阀集团形成了高度绑定的产业推进机制。首先在国家层面,长期将半导体视为战略产业,提供低息贷款、税收优惠、土地支持;企业层面,也能够接受长期亏损周期,用激进资本投入换规模,以市占率优先替代利润优先。
1997年亚洲金融危机后,这一策略被进一步强化。三星逆周期扩产 DRAM,通过价格战淘汰对手。最终,日系厂商几乎全部退出 DRAM 主流市场。
随后,SK hynix(前现代半导体)在2010 年代中期崛起,全球DRAM市场已经成为三星和SK海力士的天下,其余厂商仅存边缘份额。
进入 AI 时代后,这一优势被进一步放大。高性能计算对内存提出极高带宽、极低延迟、极高容量三项核心需求。
HBM(High Bandwidth Memory)正是在这种需求下成为关键器件。HBM的特点是:多层 DRAM Die 堆叠,与GPU / AI 加速器进行近封装,单颗价值显著高于普通 DRAM。对于早已在 DRAM 堆叠、封装、良率控制方面积累深厚经验的韩国厂商而言,这是天然优势延伸。
因此,韩国厂商迅速占据HBM主导地位,高端GPU几乎离不开其供货,自然吃到AI红利,产业话语权进一步集中。
而日本的问题在于,既没有DRAM主流产能,也没有HBM技术积累,更没有大规模资本投放能力。在当前 HBM 产业链中,日本的存在感几乎只体现在材料、设备零部件、部分封装工艺,但在“产品层面”,几乎缺席。
对于日本而言,真正担忧的可能并不是韩国赚了多少钱,而是在新一轮计算范式变革中,日本是否将彻底失去对“核心器件形态”的定义权。
日本存储的反击
在这样的大背景下,一家名为SAIMEMORY的内存公司于2026年2月初浮出水面。SAIMEMORY成立于2024年12 月,2025 年6月开始运营,是软银旗下子公司,但此前一直保持低调。直到 2026年2月,在英特尔举办的Intel Connection Japan 2026 活动上首次公开亮相。
2026年2月3日,软银公司宣布,其全资子公司SAIMEMORY公司于 2026 年 2 月 2 日与英特尔签署合作协议,以推进Z-Angle Memory (ZAM) 的商业化。
ZAM的命名来自Z轴,意味着芯片沿垂直方向进行轴向堆叠,而非仅仅在平面层叠。其理论优势包括:更短的数据通路、更均匀的热扩散路径、更高的可扩展层数、更低单位带宽功耗,本质上,这是一次从2.5D 堆叠向真正3D结构内存演进的尝试。
当前主流高带宽内存的结构,本质仍是Die在平面方向堆叠,通过TSV等方式互连,但由于功率和散热的限制,目前这种结构的16层已经接近其极限,预计最大层数将在20层左右。
英特尔在该项目中,并非单纯“战略投资人”。其关键贡献来自:下一代 DRAM 键合(NGDB, Next-Gen DRAM Bonding),美国能源部支持的先进存储技术(AMT)项目基础,英特尔院士、政府技术 CTO Joshua Freeman 表示:传统内存架构无法满足 AI 需求,NGDB 定义了一种全新的方法。
该公司将利用由美国能源部和国家核安全管理局管理、并通过桑迪亚国家实验室、劳伦斯利弗莫尔国家实验室及洛斯阿拉莫斯国家实验室实施的“先进存储技术(AMT)计划”中,英特尔已完成的“下一代 DRAM 键合(NGDB)倡议”所验证的底层技术及专业知识。SAIMEMORY计划在2027财年(截至2028年3月31日)开发出原型产品,并争取在 2029 财年实现商业化,为此将持续推进创新存储架构和制造技术的研究。
再来说说软银的算盘,软银正在押注一条可能跳过HBM世代的新型内存路线,软银是在为AI基础设施准备“自有内存”。软银正在变成一家AI基础设施资本运营商。软银已表态在 2027财年原型机完成前投入约30亿日元,这是一笔期权型投资:成功,则掌握下一代内存入口;失败,损失可控。
在存储领域,日本采取了“曲线救国”的策略,通过结构性创新,寻找架构级跃迁,来避开正面规模战争。从市场环境来看,内存的稀缺也给了日本窗口期。目前,AI数据中心消耗了大多数的内存,据TrendForce数据,2026年全球生产的内存中,约70%将被数据中心消耗。三星与SK hynix 均警告短缺可能持续到2027年。而且行业的共识是,AI数据中心消耗的内存占比快速上升,未来几年内存供需还将处于紧张。只要ZAM能在功耗/带宽/成本某一维度显著优于 HBM,哪怕只占据小众市场,也有商业生存空间。
日本不止押注内存
经历过 DRAM 被韩国全面超越、先进逻辑制程被台积电和三星垄断之后,日本产业界其实已经形成了高度一致的共识:日本不可能再复制 80–90 年代那种横扫式的半导体霸权。无论是资本体量、产业规模,还是风险承受能力,日本都很难与中美正面对冲。
于是,日本近几年的半导体战略出现了一个明显转向:从追求“做大做全”,转向确保在若干决定未来走向的关键技术节点上拥有席位。
第一,最具象征意义的,是 Rapidus 的出现。Rapidus 并不是一家按照传统商业逻辑成立的代工厂,而更像是一家“国家能力型公司”,股东阵容横跨汽车、电子、通信、互联网与半导体。专攻2nm先进制程,日本不是幻想在先进制程上打败台积电,而是要避免出现一种局面:日本在最先进逻辑芯片制造领域,完全没有自己的“技术落脚点”。因此,Rapidus 与 IBM 的合作,以及与 ASML 的设备绑定,本质上就是在用国家力量换一张“先进制程入场券”。
第二,在代工领域,日本通过巨额补贴成功引入台积电 (TSMC) 在熊本建设 JASM 一厂及二厂,与 Sony、Denso 合作。一厂(成熟/中阶制程)已开业,二厂将引入 6/7nm 先进制程。尽量实现本土化制造,保障供应链安全,这样也能更好的让日本的设备和材料厂商能够与最顶尖的代工流程现场贴合。
第三,在先进封装方面,日本正在筹划Chiplet(芯粒)时代的入场券。Intel与日本 14 家主要供应商(如 Ibiden、Resonon 等)组建了名为 "SATAS" 的研究小组,共同开发后端封装技术。日本在光刻胶(JSR、东京应化)、封装基板(Ibiden)和切片设备(DISCO)等细分领域拥有垄断性优势,这是日本在先进封装领域的筹码。
第四,在 AI 加速器方向,日本企业的态度同样非常克制。几乎没有日本公司公开宣称要打造通用 GPU 来挑战 NVIDIA。日本目前已经形成了一个由老牌巨头转型、顶尖实验室孵化、以及垂直领域初创公司构成的 AI 芯片矩阵。
PFN是日本目前估值最高的 AI 初创公司,也是日本 AI 芯片自主化的核心力量。于2016年启动了第一代MN-Core处理器的研发,目前已经研发了两代。2026 年,PFN 已开始部署其最新一代 MN-Core L1000,并正与世嘉(SEGA)等公司合作,将 AI 芯片的能力从高性能计算(HPC)扩展到更广泛的工业和游戏渲染领域。
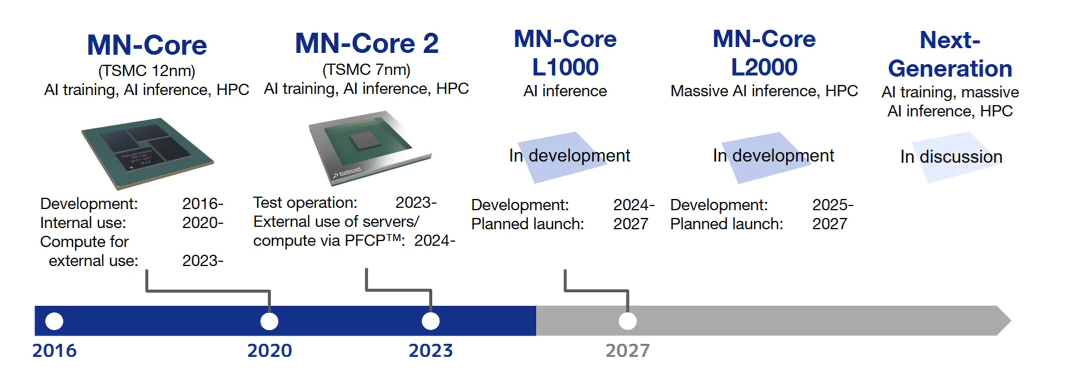
来源:PFN官网
MN-Core 是为深度学习里的矩阵计算量身定做的芯片架构,在设计时,它刻意去掉了通用 CPU/GPU 中大量复杂的控制逻辑。MN-Core 的硬件架构中大量集成了专门用于矩阵运算的单元(MAU),用于高效执行乘加等核心操作。整个架构采用的是 SIMD(单指令、多数据)思路:即同一条指令,同时驱动大量数据并行计算,而且不支持复杂的条件分支。在更高一级结构上,MN-Core 把计算资源组织成“矩阵运算块(MAB)”,每个MAB由:4 个处理器单元(PE)和1 个矩阵运算单元(MAU)组成,并采用分层结构进行组合。从效果上看,这种架构既保持了硬件的高度专用性,又通过层级化和多模式支持,保留了一定的编程灵活性,非常适合神经网络中大规模、规则化的矩阵计算任务。
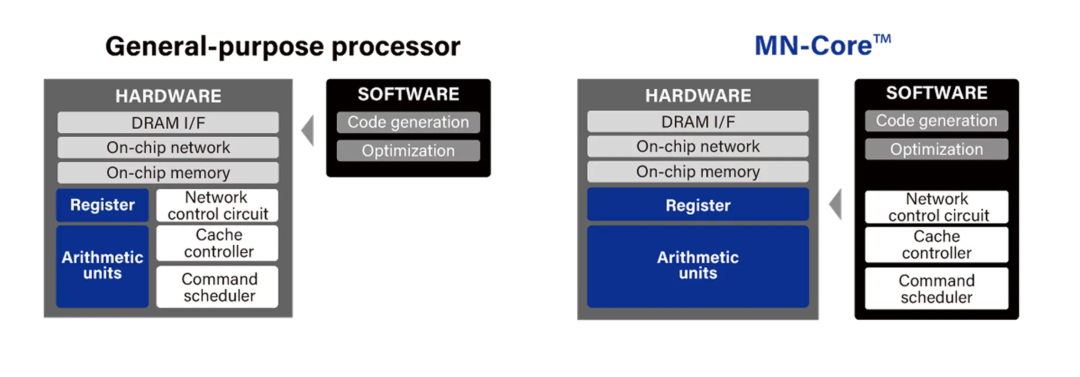
MN-core与传统传统通用处理器架构的对比(来源:PFN官网)
EdgeCortix是一家边缘 AI 领域的黑马,总部位于东京,成立于 2019 年 7 月,其理念是采用软件优先的方法,从零开始设计 AI 专用处理器架构。专注于“边缘端”AI 推理芯片,其核心产品是SAKURA-II 系列 AI 协处理器,采用名为 DNA(Dynamic Neural Accelerator,动态神经加速器)的架构。2026 年 1 月,其 SAKURA-II 芯片通过了 NASA 的抗辐射测试,被验证可用于月球任务和轨道卫星。SAKURA-II 支持 Llama 2、Stable Diffusion、DETR 和 ViT 等数十亿参数模型,典型功耗仅为 8W,满足视觉、语言、音频等众多应用领域中各种边缘生成式人工智能应用的需求。

SAKURA-II 芯片(图源:EdgeCortix)
日本 AI 泰斗松尾丰教授的实验室孵化了一批初创公司,虽然它们大多做软件,但正在通过 AI-SoC (系统级芯片) 的形式向底层渗透。如 EQUES 等公司,正在与半导体设计厂合作,将特定的视觉识别算法直接固化在芯片中。
日本老牌芯片巨头正紧跟 AI 浪潮,通过“精准卡位”实现战略转型。索尼(Sony)凭借传感器优势深耕视觉AI芯片;瑞萨通过车载 AI MPU,稳固汽车半导体版图;富士通(Fujitsu)则依托超级计算机基因,持续拓展高性能 AI 计算芯片。它们正试图在 AI 的细分垂直领域构筑新的壁垒。
结语
回过头看,日本正在做的,与其说是对韩国的“复仇”,不如说是对自身产业命运的一次再下注。
日本已经不再试图在 DRAM 产能规模上复制三星与 SK hynix 的成功,也不再幻想在通用 GPU 赛道正面挑战 NVIDIA。取而代之的,是一套更冷静、也更现实的路线:在先进逻辑制程上,保住起点;在先进封装上,掌握形态;在 AI 芯片上,进入系统;在存储领域,押注架构跃迁。
这场赌局的结局,或许还要很多年才能见分晓。但至少,日本已经重新坐回了牌桌。

