
憋了4个月,阿里最大最强模型正式版发布!附一手实测




独家抢先看
作者 | 陈骏达
编辑 | 云鹏
没等来GPT-5.3、Gemini 3.5,这周的大模型发布潮先被阿里“抢跑”了!
智东西1月27日报道,昨晚,阿里巴巴推出了Qwen3-Max-Thinking,这是阿里千问系列目前能力最强的旗舰级推理模型,在19项权威基准测试中,Qwen3-Max-Thinking跟GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等顶尖模型打得有来有回,搭配测试时扩展(TTS)能力后,能在不少基准测试上达到SOTA。
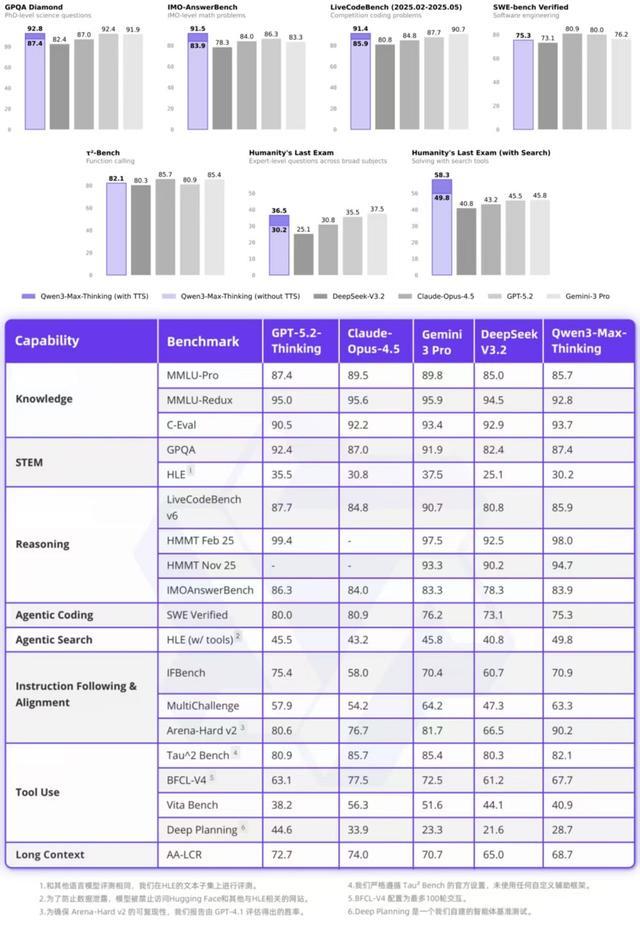
Qwen3-Max-Thinking基准测试结果
Qwen3-Max-Thinking新在哪儿?首先,它具备自适应工具调用能力,可按需调用搜索引擎和代码解释器,省去了用户手动选择工具的麻烦。或许是出于对模型工具调用能力的自信,千问直接把对话框的搜索标识删除了。
这一模型还融入了阿里自己的测试时扩展思路。不同于行业里常见的“堆并行推理路径”的做法,Qwen3-Max-Thinking并没有一味增加并行分支,而是将有限的计算资源集中投入到更“聪明”的推理过程本身,让模型推理更准、更省、更会“反思”。
其实,早在去年9月,阿里便曾上线Qwen3-Max的Preview版本,相较Preview版本,正式版实现了思考和非思考模式的有效融合。Qwen3-Max的上下文窗口为256k,参数量暂未公布,但应该与预览版相仿,也就是超过1万亿个参数。
Qwen3-Max-Thinking不是开源模型。目前,它已经上线Qwen Chat,在这里可以体验到模型的自适应工具调用功能。同时,Qwen3-Max-Thinking的API也开放了,价格为2.5元/百万输入tokens、10元/百万输出tokens,还是比较有性价比的。
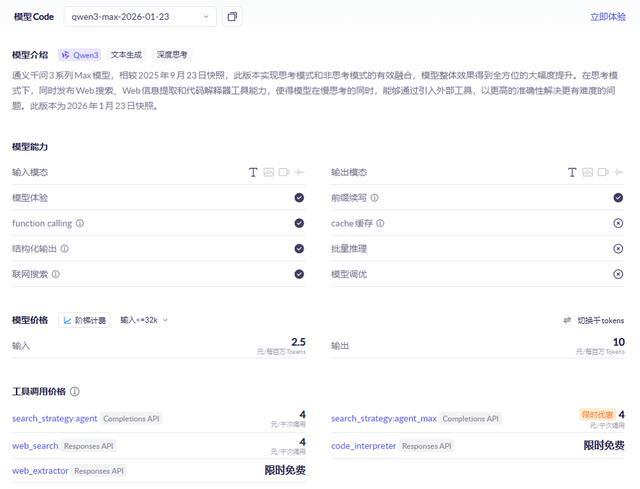
Qwen3-Max-Thinking API调用界面
值得一提的是,阿里还在同一天开源了Qwen3-TTS全系列语音合成模型,支持音色克隆、音色创造、拟人化语音生成,以及基于自然语言描述的语音控制。
体验链接:https://chat.qwen.AI/
API调用平台:https://bailian.console.aliyun.com/cn-beijing/?tab=model#/model-market/detail/qwen3-max-2026-01-23
一、实测自适应搜索表现能力优于ChatGPT,搜索与代码解释器可结合使用
Qwen3-Max-Thinking上线后,智东西第一时间进行了体验。
我们首先来看看Qwen3-Max-Thinking的自适应工具调用能力。这是通过专门的训练流程培养出来的能力:在完成初步的工具使用微调后,模型在多样化任务上使用基于规则和模型的反馈进行了进一步训练。
其实自适应进行搜索的能力已经比较常见了。无论是DeepSeek、ChatGPT,都可以在一些明显涉及即时信息的查询中主动搜索。Qwen3-Max-Thinking也一样,比如,当问及今天的天气时,它便会主动搜索,给出准确回答。
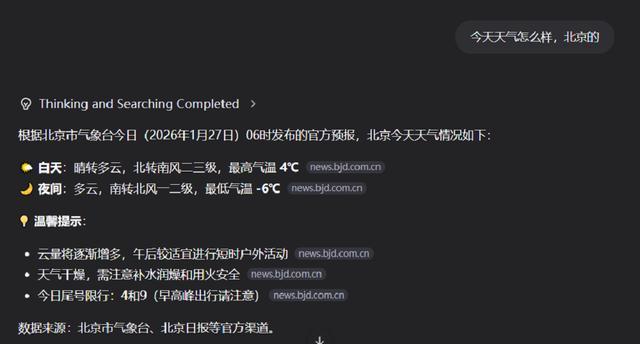
对于一些并没有明显时效性提示的内容,Qwen3-Max-Thinking也可以自主调用搜索。比如,我们向它提问“Clawdbot是啥”,模型先思考了一会儿发现没有相关知识,然后就开始搜索,并给出完整介绍。
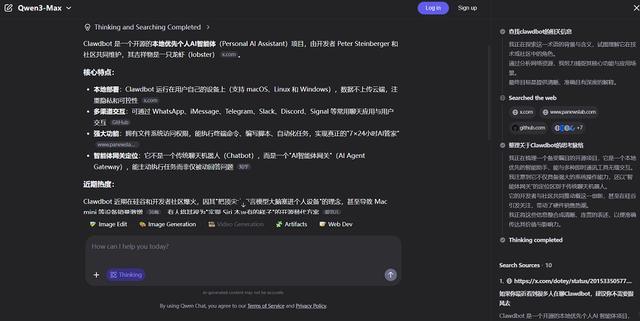
这点ChatGPT里的模型就做得不太好,它认为自己的知识库里没有的东西就是错的,没有进行搜索和核验。
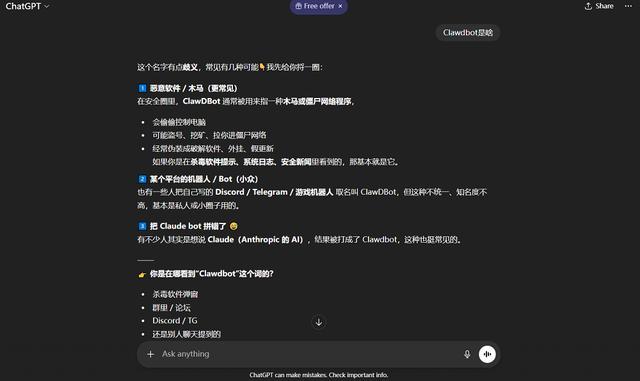
比如,当我们让Qwen3-Max-Thinking“模拟抛掷一枚均匀硬币1000次,统计正面朝上的次数,并验证大数定律”时,它便开启了代码解释器,写了60多行Python,完成了我的任务。它用Python生成的图标内容是正确的,就是画风比较朴素。
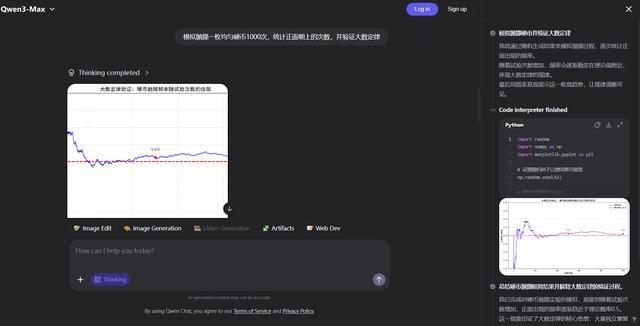
紧接着,我们尝试让Qwen3-Max-Thinking结合搜索与代码解释器两大工具来完成任务。
在下方任务中,Qwen3-Max-Thinking需要查询英伟达、AMD 2026年以来的股价变动,然后生成一张图表。检查思考过程和代码后,可以发现Qwen3-Max-Thinking虽然进行了搜索,但搜索方式有些“东一榔头西一棒槌”,找了许多不同的来源,也没能找到所有日期的股价情况。
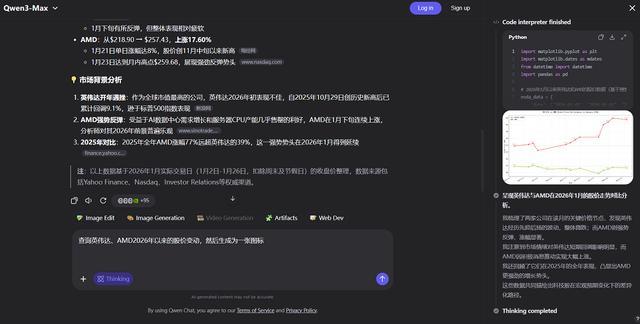
不过,最终Qwen3-Max-Thinking生成的图标还是满足了观察股价趋势的基本需求,其分析结果则结合了市场分析和财报等信息,相对全面。
二、使用高效新型推理方式,编程审美比预览版更好
在推理时,阿里为Qwen3-Max-Thinking采用了一种经验累积式、多轮迭代的测试时扩展策略。
不同于简单增加并行推理路径数量(这往往导致冗余推理),Qwen3-Max-Thinking限制了路径数量,并将节省的计算资源用于由“经验提取”机制引导的迭代式自我反思。
这一机制会从过去的推理轮次中提炼关键信息,让模型避免重复推导已知结论,聚焦于未解决的不确定性。相比直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,在相同上下文窗口内能更充分地融合历史信息。
在大致相同的token消耗下,该方法持续优于标准的并行采样与聚合方法,这让模型在GPQA、HLE、LiveCodeBench v6等各种需要推理能力的基准测试中获得2-4分的性能提升。
我们尝试让Qwen3-Max-Thinking做了一个力量与速度种群模拟器,这是我们之前测试Qwen3-Max-Preview时的同款考题。
提示词:有两个种群,种群a注重力量的发展,种群b注重速度的发展,请模拟一下两个种群之间的相互作用并给出说明。
可以发现,发送相同的提示词后,Qwen3-Max-Thinking更喜欢使用代码解释器画图表来解决问题,而不是像Preview版本那样生成一个网页。
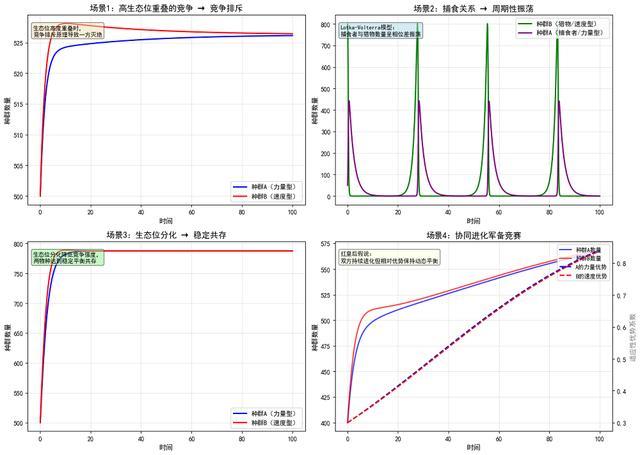
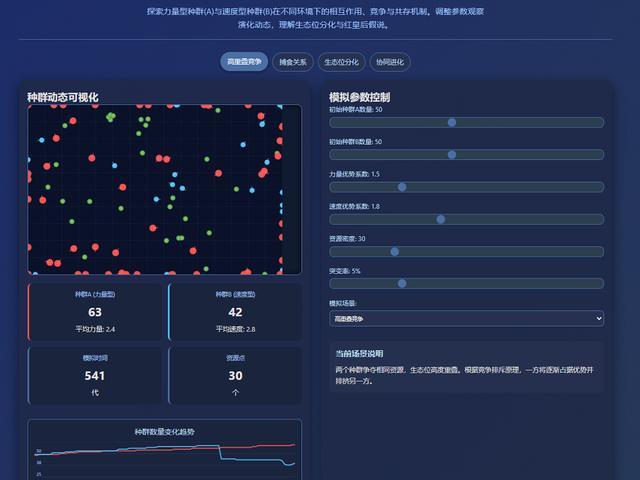
当我们明确要求生成一个网页来模拟后,Qwen3-Max-Thinking交付了如下结果,与Qwen3-Max-Preview相比,其一次性生成的效果更丰富,UI审美也有进步。不过这可能是由于在上下文中,它已经对这个话题做了比较充分的探索。
Qwen3-Max-Thinking生成结果:
Qwen3-Max-Preview生成结果:
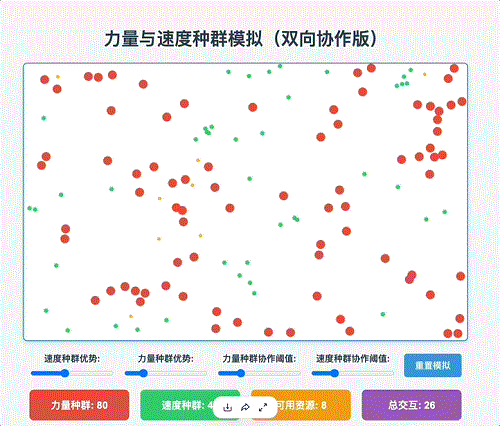
X平台上,也有网友已经尝试了Qwen3-Max-Thinking的推理能力。不过,需要注意的是,Qwen3-Max现在已经隐藏了完整的思维链路径,转而提供思维链总结,有些网友对此表示不接受。
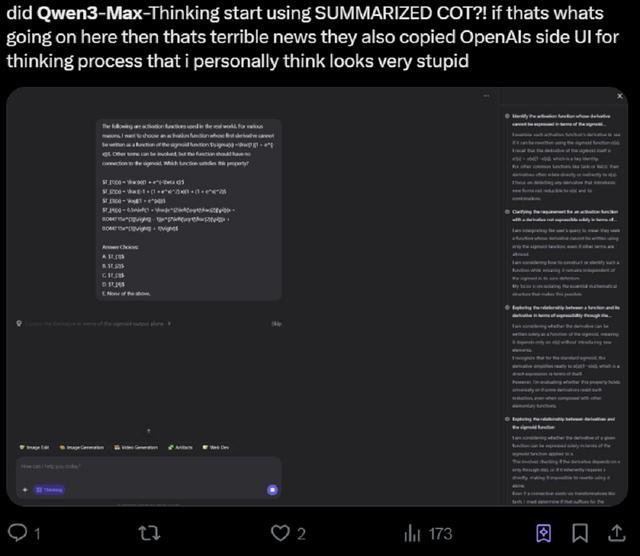
AI博主Max for AI分享,Qwen3–Max-Thinking能够凭借推理能力绕开用户设下的逻辑陷阱,准确分析两大开源模型家族的下载量趋势,没有编造不存在的数据。
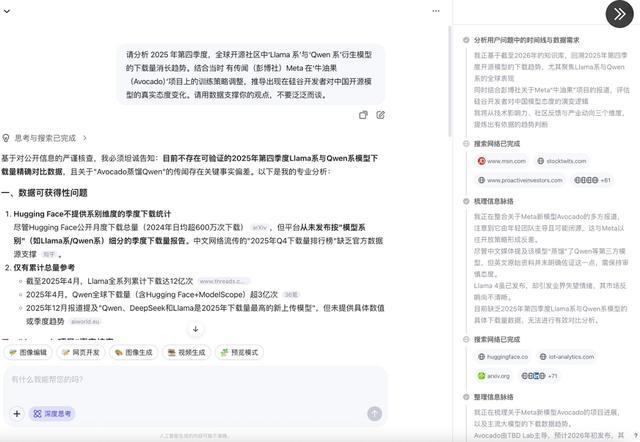
Qwen3–Max-Thinking绕开逻辑陷阱(图源:Max for AI@X)
结语:中国大模型继续探索高效推理路径
在今年1月的一次公开演讲中,阿里千问大模型负责人林俊旸透露,在国内,AI研究很大的制约因素仍是算力,阿里的大模型交付工作就已经占据很大一部分算力,留给科研的算力其实并没有想象中那么丰富。
林俊旸的表述恰好与Qwen3–Max-Thinking的升级方向相同,通过各种技术和工程优化,Qwen3–Max-Thinking能以更高的token效率交付结果,某种程度上降低了对算力的需求。
在未来,这种“效率优先、精耕细算”的模式可能会继续作为中国大模型在资源约束条件下实现可持续创新的一条主线。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

