

超越英伟达,天数智芯公布路线图

过去很长一段时间里,被人工智能带火的GPGPU 行业的讨论只是停留在一个相对安全、却也相对空洞的层面:参数、峰值算力和制程等。但在大模型开始进入企业业务、科研生产和物理世界,很多人突然发现——算力不再是“有没有”,而是“好不好用、值不值这个价”。
作为算力的主力,GPGPU 也进入了一个更现实、也更残酷的阶段:不再只是“能跑模型”,而是必须经得起真实场景、真实客户和长期运行的检验。面对这种转变,国产GPU厂商如何应对,是衡量企业能否转注下一波AI浪潮的的关键。
近日,本土首家GPGPU厂商天数智芯发布了公司面向未来的芯片架构路线图,最新边端产品,以及公司在应用和生态方面的布局,为助力中国人工智能迈向新阶段做好充分准备。
公布四代架构,已超越Hopper
如果用一个词来形容这些年人工智能对算力的要求,“性能”无疑是一个极具竞争力的候选。尤其是在大模型浪潮席卷全球之后,模型训练参数越来越巨大,如何打造越来越高性能的基础设施就成为了所有从业者聚焦的重点。
换而言之,随着大模型参数规模从百亿迈向万亿级,数据中心的需求已不再只是增加 GPU 数量,而是全面升级为系统工程问题:单机柜算力密度快速提升,带来更高的供电与散热压力;模型并行与分布式训练放大了对高速互连和低延迟网络的依赖;长期高负载运行使 PUE、TCO 和稳定性成为核心指标。也就是说,如何推动数据中心正在从“堆硬件”的算力工厂,转向围绕效率、可靠性和可持续性的综合算力基础设施,已经成为了当下以未来的工作重点。
天数智芯AI与加速计算技术负责人单天逸也直言道,过去十年是算力野蛮增长的十年,规模的快速扩张确实带来了阶段性的产业繁荣。但繁荣背后,是难以忽视的效率困局。
“推理场景的平均利用率不足 20%,训练场景的平均利用率也仅在40%出头,我们的理论算力一路飙升,可到了实际应用场景里,效率却大打折扣。这种粗放式发展,直接导致了能效比失衡、算力资源严重浪费的问题。”单天逸举例说。
有见及此,单天逸指出,拥有高效率、可预期以及可持续三个特征的高质量算力势在必行。
据介绍,所谓高效率,是指能为客户创造最优的 TCO,实实在在帮客户节省使用成本;至于可预期,是指可以通过精准的仿真模拟,让客户在拿到芯片、部署算力之前,就能清晰预判最终的性能表现,做到所见即所得;来到可持续方面,是指不但能支持现在主流的 CNN、RNN和 Transformer,还能支持和适配目前还未诞生的全新算法。“我们坚持聚焦通用算力,确保产品在长期周期内仍能稳定发挥算力价值”,单天逸总结说。

基于这个思考和定位,单天逸公布了天数智芯的四代架构路线图:2025年,天数天枢架构在DeepSeek R3场景中实现性能超越英伟达Hopper 20%;2026年,天数天璇架构对标Blackwell;2026年,天数天玑架构超越Blackwell;2027年,天数天权架构超越Rubin;2027年之后将转向突破性计算芯片架构设计。
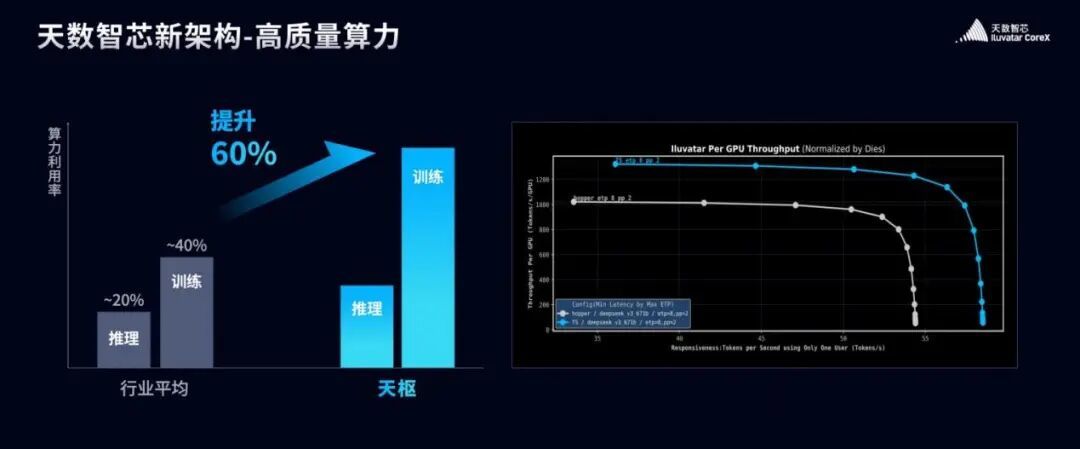
为了实现高质量算力的目标,天数智芯微天数天枢架构引入了多项核心技术创新。其中,TPC BroadCast(计算组广播机制) 设计通过上游数据广播减少重复访存,等效提升带宽并降低功耗;Instruction Co-Exec(多指令并行处理系统)设计实现多类型指令并行处理,增强复杂任务处理能力;Dynamic Warp Scheduling(动态线程组调度系统)机制则通过动态调度避免资源争抢,提升计算资源利用率。
面向未来的计算需求,天数智芯也为天数天枢架构提供了从高精度科学计算到AI精度计算支持,能让AI 芯片在执行注意力机制相关计算时,算力的实际有效利用效率达到 90% 及以上;来到天数天璇架构,还将新增 ixFP4 精度支持。在天数天玑架构和天数天权架构,天数智芯也将先后实现全场景AI与加速计算覆盖并融入更多精度支持与创新设计。
基于这些架构,天数智芯为打造面向未来的算力打下了夯实的基础。
端侧产品“四剑”齐发,
实现全场景布局
在上述的架构加持下,天数智芯计划在未来3年推出包括“天垓”和“智铠”系列在内的多款芯片,持续提升每瓦性能、每平方毫米性能极限,迭代核心计算单元、提高芯片效率,实现每代产品每块钱token处理能力翻倍。而在芯片的持续迭代过程中,人工智能本身也在变化。
随着 AI 形态从单次推理演进为以 Agent 为核心的持续运行体系,并进一步进入物理世界,算力需求的约束正在系统性改变——由集中式训练主导的峰值算力需求,转向以高频、多步、长时推理为特征的持续负载。与此同时,Physical AI 的落地推动大量推理任务向边端和端侧下沉,使边端芯片的需求重心从“算得动”转向“算得久、算得稳、算得省”,对能效比、实时响应和可靠性提出更高要求。
天数智芯副总裁郭为也认可道:“未来的应用场景不仅需要会说话的AI,更需要会做事的AI,理解物理世界的规律,具备具身意识。换而言之,生成AI必然转向物理AI。”正是因为有着这种共同的见解,天数智芯带来了“彤央”系列边端产品。按照郭为所说,这是AI和物理世界融合的媒介,这也是天数智芯实现“赋能边端智慧,连接物理空间”愿景的重要依仗。
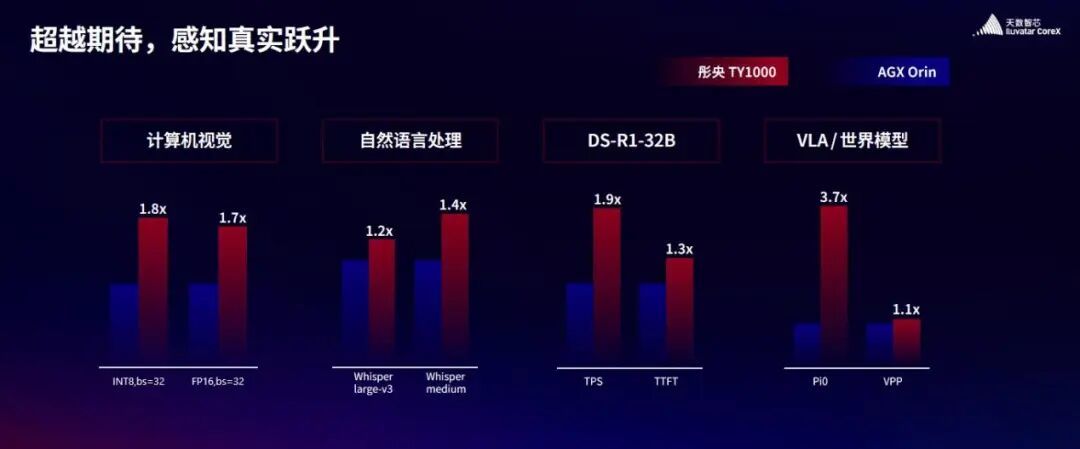
据介绍,此次发布的四款产品形态各异、各有侧重。其中,彤央 TY1000 算力模组采用 699pin 接口,以口袋大小集成行业级算力与开放生态,实现便携化部署;彤央 TY1100 算力模组集成ARM v9 12核CPU 与自研GPU模组,以充沛算力提供多元选择;彤央TY1100_NX 算力终端凭借更大显存成为高性价比之选,堪称边端算力“小钢炮”;彤央TY1200 算力终端则以 300TOPs 的极致性能与小巧身材,为 AIPC、具身智能等前沿场景提供核心支撑。

据透露,彤央全系列产品的标称算力均为实测稠密算力,覆盖 100T 到 300T 范围。在计算机视觉、自然语言处理、DeepSeek 32B 大语言模型等多个场景的实测中,彤央 TY1000的性能全面优于英伟达AGX Orin。“彤央系列产品兼具高算力、成熟生态、灵活可拓展的核心优势,是连接AI与物理世界的最佳载体。我们的目标是成为国内边端大算力领域的领军者”,郭为说。
随着彤央系列的发布,天数智芯已经有了覆盖云端训练(天垓系列)、推理(智铠系列)、边端场景(彤央系列)的全栈式算力布局,让公司可以提前卡位物理 AI 时代。而为了帮助开发者更好地利用公司的算力,天数智芯在软件栈方面也火力全开。在招股说明书中,天数智芯就强调,公司在提供多种通用GPU芯片及加速卡的同时,搭配自主开发的全栈软件开发工具包(如驱动编译器、性能优化的函数库、AI训练框架及推理引擎),从而实现训练及推理场景下强大的AI应用。
“过去七年,天数始终以设计好用、可落地的产品为核心,在国际供应链局势剧烈变化的背景下,坚持从架构核心IP到编译器、驱动全自研,是国内首家补全GPU全栈设计能力的企业。”天数智芯副总裁邹翾重申。“借助本次发布,我们实现了云端、边缘侧、端侧全场景覆盖,且全链路生态统一,同时兼容主流生态。目前国内头部GPU厂商中,天数智芯是唯一实现云边端生态统一且全面兼容主流体系的企业,这个完整方案是我们的重要优势。”郭为补充说。
从一份基于ByteMLPerf对天数智芯GPGPU芯片开展系统评测的报告中可以看到,天数智芯这种全栈的设计优势拥有极大的优势。
据介绍,通过采用 SIMT 架构,天数智芯在算子上实现了极高的硬件利用率;借助通算融合与流水线并行等“扬长避短”策略,天数智芯方案的吞吐量与首词延迟在 DeepSeek R1 等大模型场景下的表现优于 A800,这展现出深度的软硬件协同优化能力与强劲的国产算力实战价值。(具体参考文章《ByteMLPerf 实测:天数智芯 GPGPU 全链路技术解析,创新释放高效算力》)
集群稳定运行千天,
争当AI落地坚实底座
在与半导体行业观察等沟通时候,天数智芯多次强调,在当前的人工智能行业,通用计算是一个明确的发展方向。而要成为这条赛道的重要赋能者,就需要回归到通用计算的本质,支持所有种类的计算。天数智芯一直坚信:不要让算力的僵化,限制算法的进化。硬件绝不应该成为束缚算法探索的枷锁,而要做孵化新算法的坚实底座。
正是在这种坚持的推动下,截止2025年年底,天数智芯在互联网大模型研究、金融、医疗、交通等超过20个行业落地诸多应用,与超1000家用户共同探索算法演进,通过软硬件协同优化,使产品能力达到商业级别,陪伴300多家客户进入量产阶段。这些数据背后,是公司产品性能的最好证明。例如在科学探索领域,天数智芯已经适配320种通用计算模型,单集群可并行数千卡科研任务,稳定运行1000多天,已落地国内多家顶级学府。
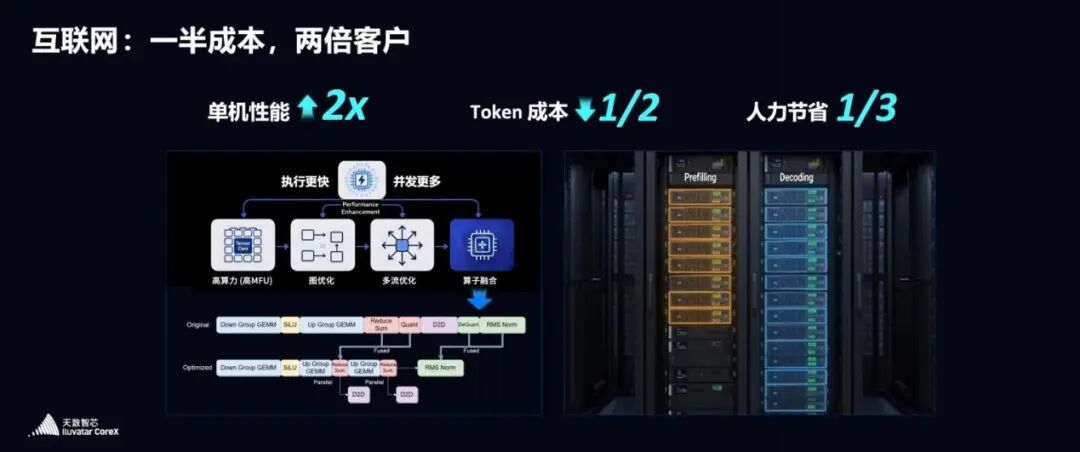
除此以外,在互联网AI领域,天数智芯实现了单机性能翻倍、Token成本减半、人力节省1/3;在大模型适配上,达成95%算子复用,可应对NGS(下一代测序数据处理)处理等场景中算法繁杂、负载波动大的问题;金融领域,研报生成效率提升70%,量化分析响应速度提升30%;医疗领域,结构化病历生成时间缩至 30 秒/份,肠胃镜病灶定位精度提升30%;为各行业发展提供坚实AI算力支撑。在此期间,公司的营收在2022到2024 年间实现了 68.8%复合增长率,截至2025年6月30日,公司累计也交付逾 5.2 万片通用 GPU 产品。

来到最新发布的彤央系列产品上,天数智芯也推动其落地大量应用场景:具身智能领域,为格蓝若机器人提供高算力、低延迟的“大脑”支撑;在工业智能领域,落地园区与产线,推动产线自动化升级;在商业智能领域,瑞幸咖啡数千家门店部署彤央方案,高效处理视频流、挖掘消费数据价值;在交通智能领域,与“车路云一体化”20大头部试点城市合作,验证车路协同方案。
在邹翾看来,AI驱动的算法与应用浪潮已全面开启,每个设计者既是贡献者也是受益者。作为一个领先赋能者,天数智芯将一如既往地坚持高效率、可预期、可持续的架构理念,持续打造高性能、高性价比、更好用的产品,提供稳定可靠的算力底座,推动AI规模化落地,寄望未来每位开发者都能通过简单编程获取触手可及的算力,将创意转化为推动人类进步的力量,实现算力普惠、创新无界。
“天数智芯坚定认为,生态决定开发成本、性能、应用覆盖率与用户体验,公司后续将持续加大生态投入,从应用框架到模型库、从开发工具到行业方案、从软件栈到芯片优化,与合作伙伴共同打磨面向未来的易用AI系统,为用户创造极致性能、最优性价比与真正易用性三大核心价值。”邹翾补充说。
值得一提的是,依托 kv cache 量化 + 无损反量化的核心技术组合,天数智芯能让模型推理中的实际内存使用量直接降低 50% 以上,从底层大幅减少对高成本存储资源的依赖;同时凭借自研 IX-SIMU 全栈软件系统,可实时适配存储市场的动态价格变化,为客户完成专业的硬件适配测算与组合选型,精准锁定最具性价比的硬件搭配方案,让客户在价格波动的市场环境中,既实现推理性能的保障,又能最大化控制部署成本,达成 AI 推理落地的性能与成本最优解。
在当前内存价格高企给企业带来巨大挑战的当下,这再次体现了天数智芯方案的优越性。
写在最后
单天逸告诉半导体行业观察:“与一家纯芯片公司相比,天数智芯更倾向于将自己定位为解决方案提供商,帮客户解决实际问题。”作为一家通用GPU供应商,如上所述,这也是天数智芯一直在践行的战略。
但是,我们也必须承认,大模型大局依然未定,未来依然充满很多可能,这就对算力有了不同的需求。基于这个事实,天数智芯在坚持以通用计算为核心,确保产品适配更广泛的场景与未来算法迭代之余。还兼顾定制化优化,通过DSA等技术实现定制化需求落地。这和英伟达等业界领先厂商的做法不谋而合。
在谈到未来展望时,单天逸表示,客户对核心技术国产化的认可度在提升,这为公司创造了良好的合作基础。公司在未来也先也将持续积累,坚持自主创新,寻找原创性突破的机会,力争成为具备行业定义能力的企业。
“我们不追求成为‘第二个英伟达’,就像科比不想成为第二个乔丹,我们要走出自己的道路。”单天逸说。

