

美团LongCat-Video-Avatar发布并开源,重点提升动作拟真度




下载客户端
独家抢先看
独家抢先看
凤凰网科技讯 12月18日,美团LongCat团队正式发布并开源虚拟人视频生成模型LongCat-Video-Avatar。该模型基于其此前开源的LongCat-Video基座构建,支持通过音频、文本或图像生成虚拟人视频,并具备视频续写功能。

据介绍,新模型重点提升了动作拟真度、长视频生成稳定性与身份一致性。其通过“解耦无条件引导”技术使虚拟人在语音间歇也能呈现眨眼、调整姿势等自然状态。针对长视频生成中常见的画面质量退化问题,团队提出了“跨片段隐空间拼接”策略,旨在避免重复编解码带来的累积误差,声称可支持生成长达5分钟的视频并保持画面稳定。
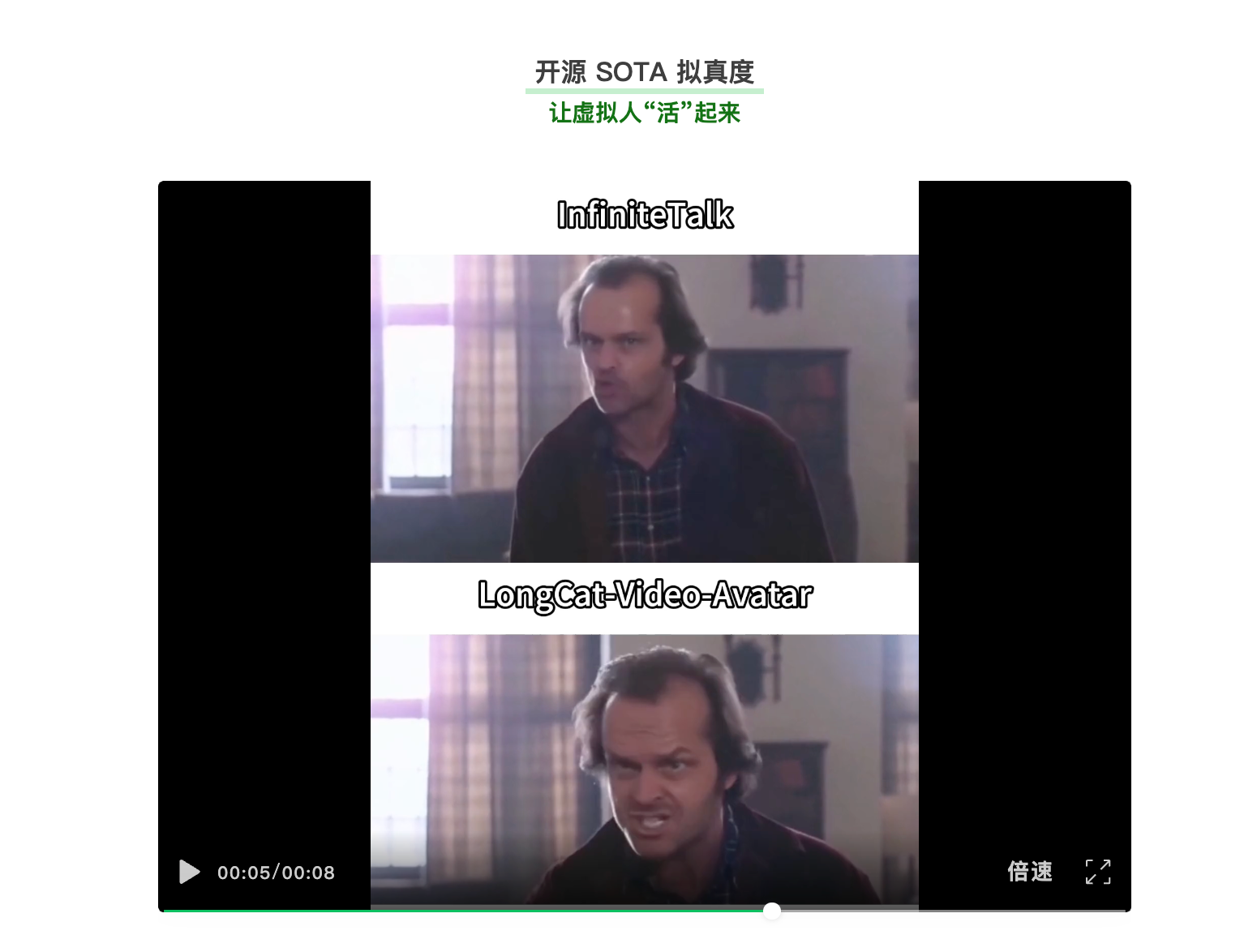
在身份一致性方面,模型采用了带位置编码的参考帧注入与“参考跳跃注意力”机制,以在保持角色特征的同时减少动作僵化。团队表示,在HDTF、CelebV-HQ等公开数据集的评测中,该模型在唇音同步精度与一致性指标上达到当前先进水平,并在涵盖商业推广、知识教育等场景的综合测试中表现领先。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

