

蚂蚁开源业内首个100B扩散语言模型LLaDA2.0




独家抢先看
IT之家 12 月 12 日消息,蚂蚁技术研究院今日宣布推出 LLaDA2.0 系列离散扩散大语言模型(dLLM),并同步公开了背后的技术报告,宣称是“业内首个 100B 扩散语言模型”。
LLaDA2.0 包含 MoE 架构的 16B (mini)和100B (flash)两个版本,将 Diffusion 模型的参数规模首次扩展到了 100B 量级。
蚂蚁技术研究院表示,此次发布的模型不仅打破了扩散模型难以扩展的固有印象,更在代码、数学和智能体任务上展现出了超越同级自回归(AR)模型的性能。
通过创新的 Warmup-Stable-Decay(WSD)持续预训练策略,LLaDA2.0 能够无缝继承现有 AR 模型的知识,避免了从头训练的高昂成本。结合不仅限于常规 SFT 的置信度感知并行训练(CAP)和扩散模型版 DPO,LLaDA2.0 在保证生成质量的同时,利用扩散模型的并行解码优势,实现了相比 AR 模型 2.1 倍的推理加速,证明了在超大规模参数下,扩散模型不仅可行,而且更强、更快。
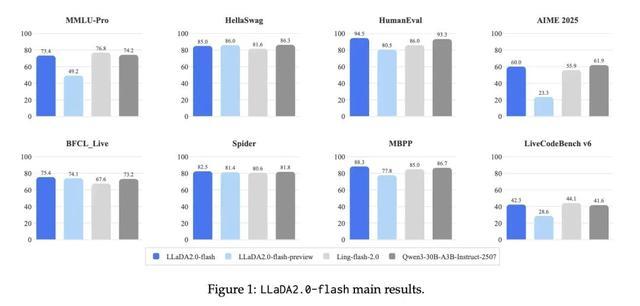
蚂蚁技术研究院在知识理解、数学、代码、推理 & 智能体等多个维度对模型进行了评估。结果显示,LLaDA2.0 在结构化生成任务(如代码)上具有显著优势,并在其他领域与开源 AR 模型持平。
LLaDA2.0 的模型权重(16B/100B)及相关训练代码均已在 Huggingface 开源。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

