

刚刚,OpenAI一口气发布三个新模型!还为此做了一个新网站




独家抢先看
就在刚刚,OpenAI宣布在其API中推出全新一代音频模型,包括语音转文本和文本转语音功能,让开发者能够轻松构建强大的语音Agent。
新产品的核心亮点概述如下
gpt-4o-transcribe (语音转文本):单词错误率(WER)显著降低,在多个基准测试中优于现有 Whisper 模型
gpt-4o-mini-transcribe (语音转文本):gpt-4o-transcribe的精简版本,速度更快、效率更高
gpt-4o-mini-tts (文本转语音):首次支持「可引导性」(steerability),开发者不仅能指定「说什么」,还能控制「如何说」
据OpenAI介绍,新推出的gpt-4o-transcribe采用多样化、高质量音频数据集进行了长时间的训练,能更好地捕获语音细微差别,减少误识别,大幅提升转录可靠性。
因此,gpt-4o-transcribe更适用于处理口音多样、环境嘈杂、语速变化等挑战场景,比如客户呼叫中心、会议记录转录等领域。
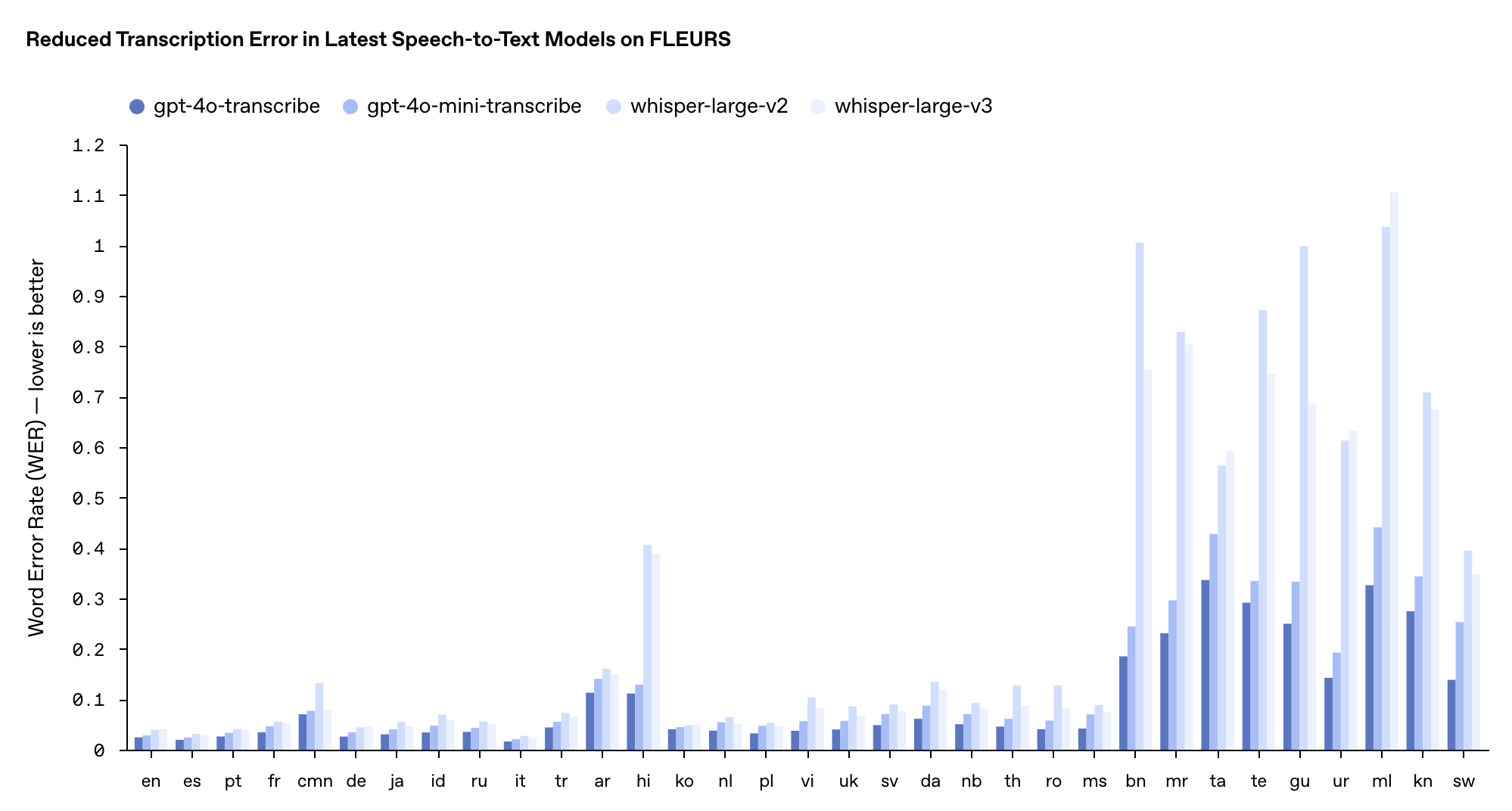
gpt-4o-mini-transcribe则基于GPT-4o-mini架构,通过知识蒸馏技术从大模型转移能力,虽然WER(越低越好)稍高于完整版模型,但仍旧优于原有Whisper模型,更适合资源有限但仍需高质量语音识别的应用场景。
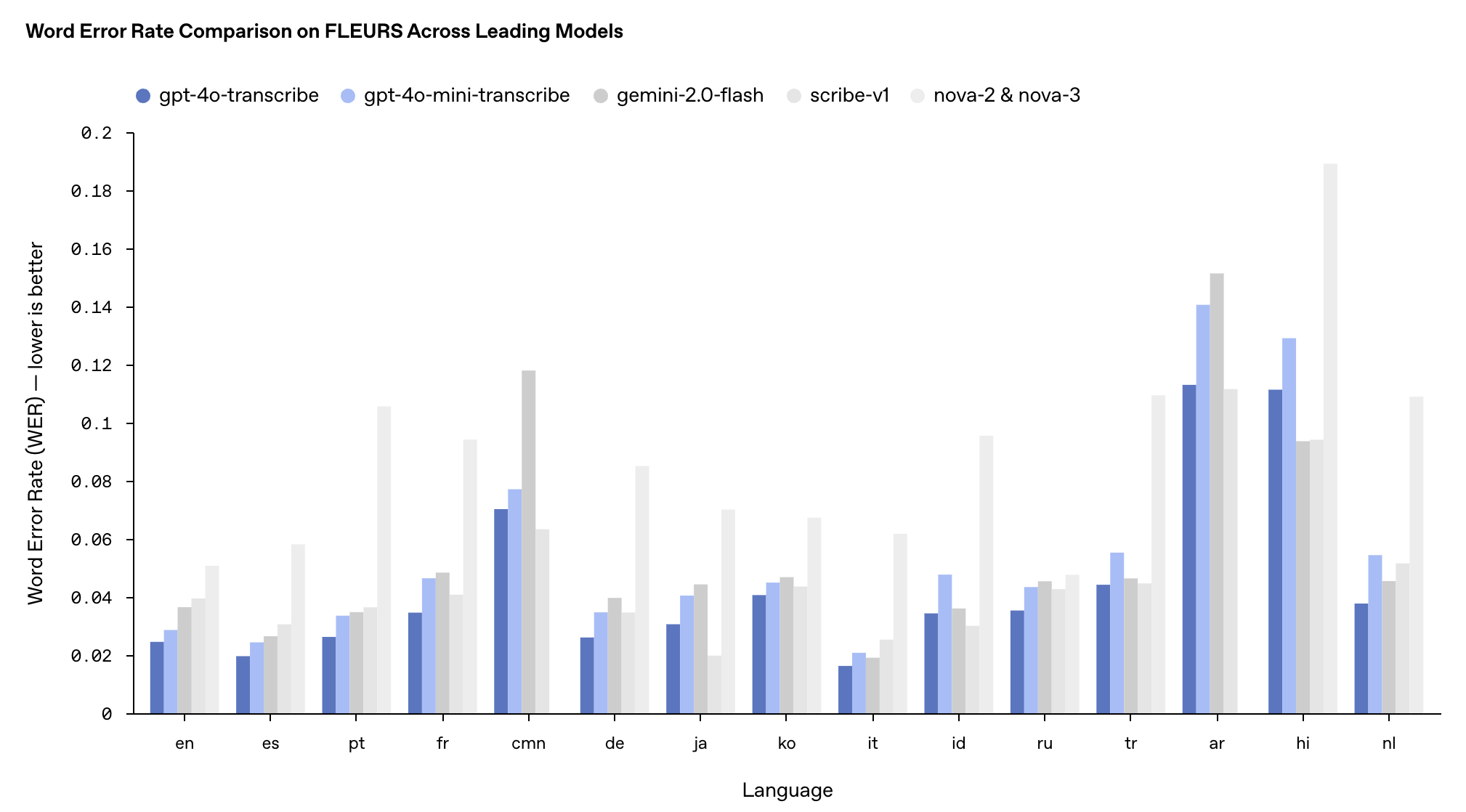
这两款模型在FLEURS多语言基准测试中的表现超越了现有的Whisper v2和v3模型,尤其在英语、西班牙语等多种语言上表现突出。
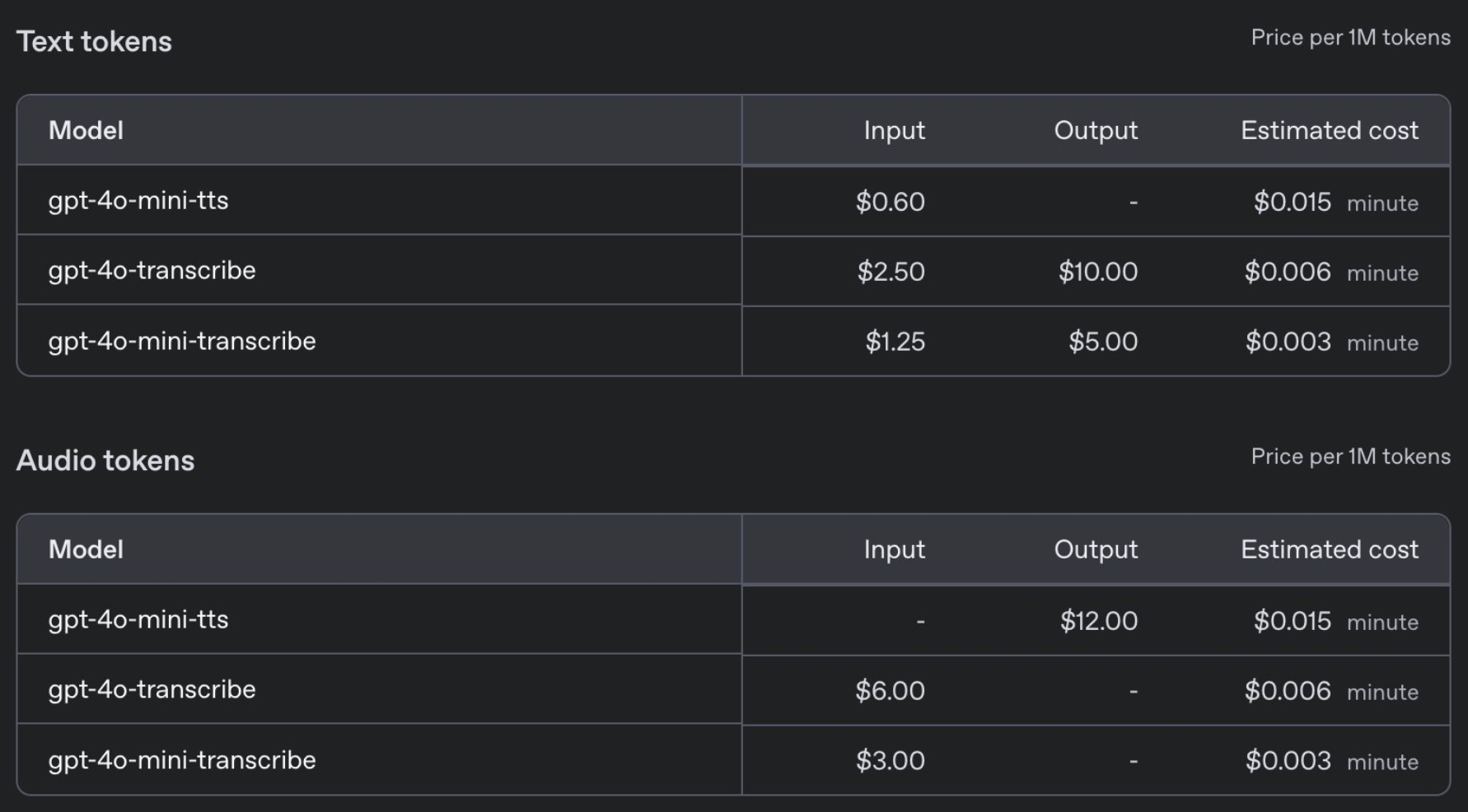
定价方面,GPT-4o-transcribe与之前的Whisper模型价格相同,每分钟0.006美元,而 GPT-4o-mini-transcribe则是前者的一半,每分钟0.003美元。
与此同时,OpenAI还发布了新的gpt-4o-mini-tts文本转语音模型。首次让开发者不仅能指定「说什么」,还能控制「如何说」。
具体而言,开发者可以预设多种语音风格,如「平静」、「冲浪者」、「专业的」、「中世纪骑士」等,它还能根据指令调整语音风格,如「像富有同情心的客服 Agent 一样说话」,定价亲民,仅为每分钟1美分。
安全不能马虎,OpenAI表示,gpt-4o-mini-tts将接受持续监控,以保证其输出与预设的合成风格保持一致。
这些技术进步的背后源于OpenAI的多项创新:
新音频模型建立在GPT-4o和GPT-4o-mini架构之上,采用真实音频数据集进行预训练
应用self-play方法创建的蒸馏数据集的知识蒸馏方法,实现从大模型到小模型的知识转移
在语音转文本技术中融入强化学习(RL),显著提升转录精度并减少「幻觉」现象。
在凌晨的直播中,OpenAI向我们展示了一款AI时尚顾问Agent的应用案例。
当用户询问「我最近的订单是什么?」时,系统流畅回应:用户于2月9日订购的Patagonia短裤已发货,并在后续提问中准确提供了订单号「A.D. 507」。
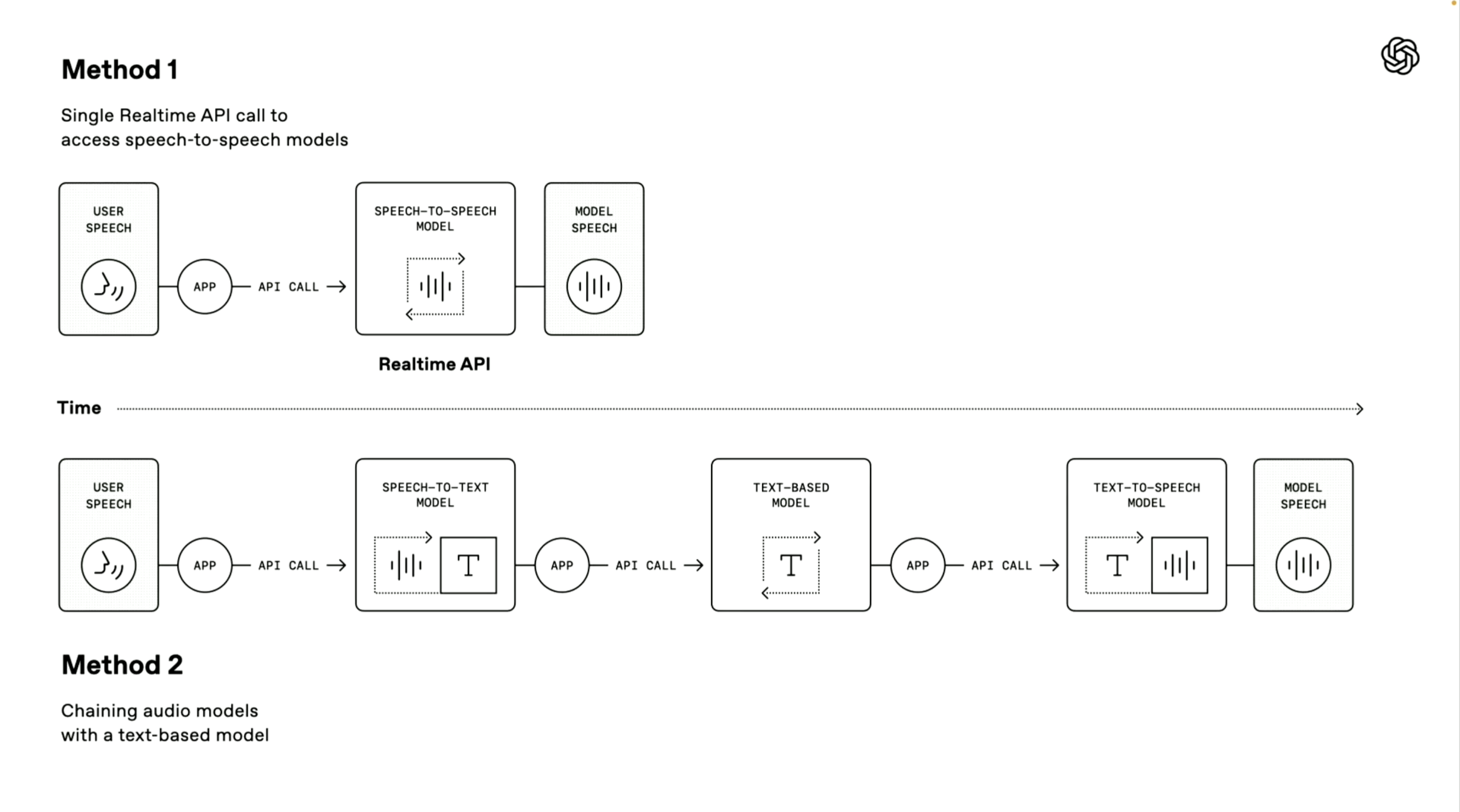
值得一提的是,OpenAI演示人员还介绍了两种构建语音Agent技术路径,第一种「语音到语音模型」采用端到端的直接处理方式。
系统可直接接收用户语音输入并生成语音回复,无需中间转换步骤。这种方式处理速度更快,已在ChatGPT的高级语音模式和实时API服务中得到应用,非常适合对响应速度要求极高的场景。
第二种「链式方法」则是本次发布会的重点。
它将整个处理流程分解为三个独立环节:首先使用语音转文本模型将用户语音转为文字,然后由大型语言模型(LLM)处理这些文本内容并生成回应文本,最后通过文本转语音模型将回应转为自然语音输出。
这种方法的优势在于模块化设计,各组件可独立优化;处理结果更稳定,因为文本处理技术通常比直接音频处理更成熟;同时开发门槛更低,开发者可基于现有文本系统快速添加语音功能。
OpenAI还为这些语音交互系统提供了多项增强功能:
支持语音流式处理,实现连续音频输入和输出
内置噪音消除功能,提升语音清晰度。
语义语音活动检测,能够识别用户何时完成发言
提供追踪UI工具,方便开发者调试语音代理
目前,这些全新音频模型已向全球开发者开放。
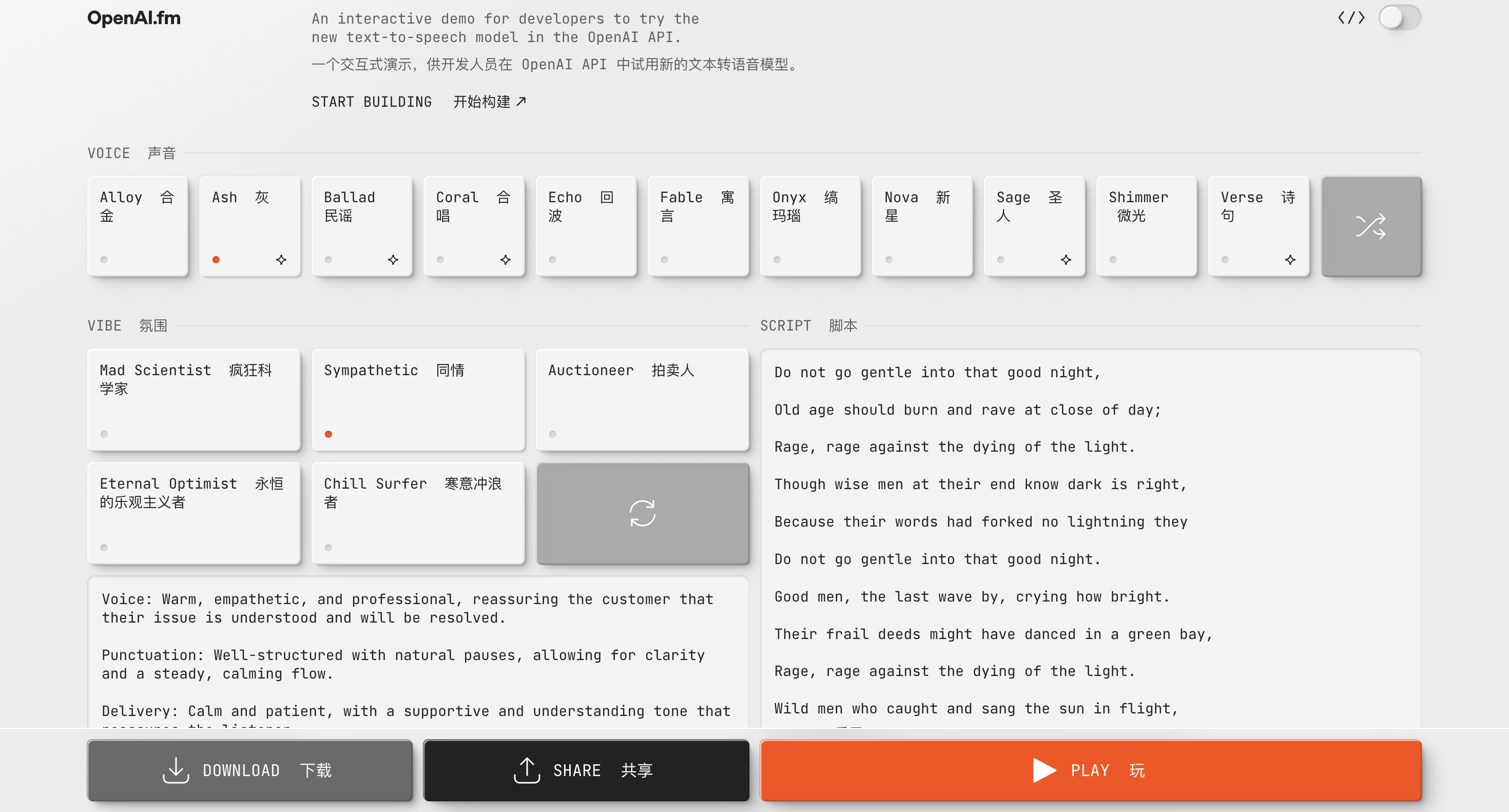
你还可以在http://OpenAI.fm上体验并制作gpt-4o-mini-tts的相关音频,这个演示网站可谓是功能齐全,左下角是官方的预设模板,主要包括人设、语气、方言、发音等设置。
我们也实测了一段八百标兵奔北坡的绕口令,emmm,中文效果马马虎虎。至于英文效果,听它念着诗歌,倒是挺有真人那味了,但无论是与此前走红的 Hume AI 亦或者 Sesame 相比,「肉耳可听」地还差点火候。
此外,OpenAI推出了与Agents SDK的集成,进一步简化开发流程。
值得一提的是,OpenAI还举办了一个广播比赛。用户可以在http://OpenAI.fm制作音频,接着使用OpenAI.fm上的「分享」按钮生成链接,然后在X平台分享该链接。
最具创意的前三名将各获一台限量版Teenage Engineering OB-4。音频时长建议控制在30秒左右,可在语音、表达、发音或剧本语调变化上尽情发挥创意。

实际上,今年AI的风向也在悄然发生变化,除了依旧强调智商,还多出一股趋势,强调情感。
GPT-4.5、Grok 3的卖点是情商,写作更有创意,回应更个性化,而冷冰冰的机器人(智元机器人),也强调更拟人,主打一个情绪价值。
由于直接触及人类最本能的沟通方式,语音领域在这方面的发力则更加显著。
最近在硅谷走红的Sesame AI能够实时感知用户情绪,并生成情感共鸣的回应,迅速俘获了一大批用户的心。图灵奖得主Yann lecun最近也在强调,未来的AI需要拥有情感。
而无论是OpenAI今天发布的全新语音模型、还是即将发布的Meta Llama 4都有意往原生语音对话靠拢,试图通过更自然的情感交互拉近与用户的距离,靠「人味」圈粉。
AI需要有人味吗?长期以来。聊天机器人通常被定义为没有情感的工具,它们也会在对话中提醒你,它是一个没有灵魂的模型。然而,我们却往往能从中解读出情绪价值,甚至不自觉地与之建立情感联结。
或许人类天生渴望被理解、被陪伴,哪怕这种理解来自一台机器。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

