

OpenAI最强推理模型o3发布!AGI测试能力暴涨,最难数学测试分数碾压同行




独家抢先看

作者 | ZeR0 程茜
编辑 | 漠影
智东西12月21日报道,今日,OpenAI“连续12日圣诞发布”终于迎来激动人心的大结局,OpenAI推出重磅收官新品,其迄今最强前沿推理模型的升级版——o3。
OpenAI号称o3在一些条件下接近通用人工智能(AGI)。
OpenAI CEO Sam Altman在直播中说:“我们认为这是AI下一阶段的开始。你可以使用这些模型来完成越来越复杂、需要大量推理的任务。”他还夸赞o3在编程方面的表现令人难以置信。
今年9月发布的OpenAI o1模型拉开了推理模型的闸门,随后许多国内外大模型企业相继推出大量推理模型。出于对英国电信运营商O2的尊重,OpenAI把o1的继任者命名为o3。
和前代o1模型一样,o3通过思维链进行思考,逐步解释其逻辑推理过程,总结出它认为最准确的答案。
o3有完整版和mini版,新功能是可将模型推理时间设置为低、中、高,模型思考时间越高,效果越好。mini版更精简,针对特定任务进行了微调,将在1月底推出,之后不久推出o3完整版。
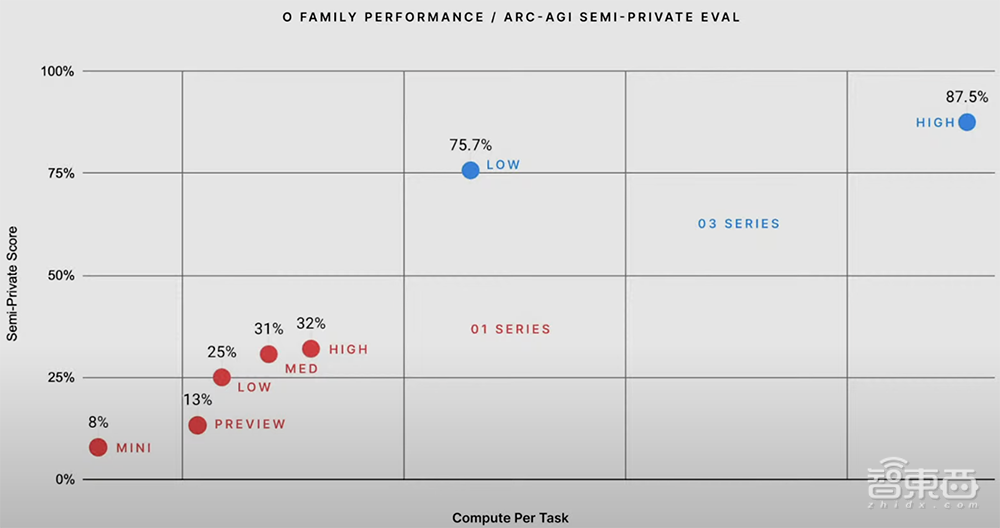
ARC-AGI是一项旨在评估AI系统推理首次遇到的极其困难的数学和逻辑问题能力的基准测试,由Keras之父François Chollet发起。在ARC-AGI测试中,o3在高推理能力设置下取得了87.5%的分数,在低推理能力设置下的分数也高达o1的3倍。
这一成绩令社交平台一片雀跃,认为AI技术发展非但不见放缓,反而展示出比预期更快的通往AGI的速度。
要知道,之前GPT-3的评测结果为0%,GPT-4o为5%,而o3一举将成绩提升到87.5%,令人瞠目。与之前的大模型相比,o3能适应以前从未遇到过的任务,可以说接近人类水平的性能。
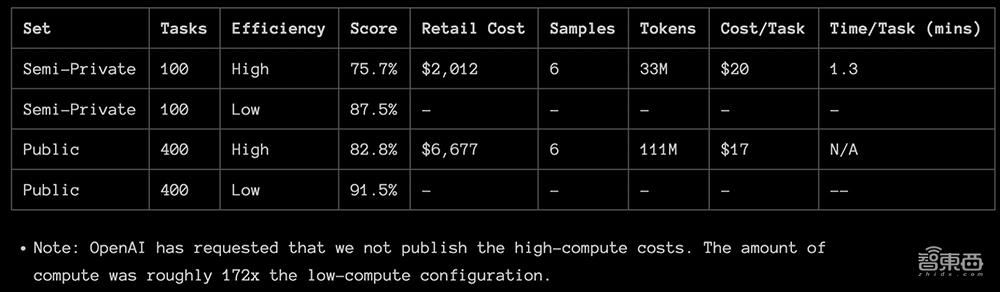
François Chollet发布了o3的完整测试报告。o3在两个ARC-AGI数据集中进行了测试,并在两个具有可变样本量的计算级别上进行了测试:6(高效率)和1024(低效率,172倍计算)。其中,75.7%的高效率分数在ARC-AGI-Pub的预算规则范围内(成本<10000美元),87.5%的低效率分数成本则相当昂贵,但仍然表明新任务的性能确实会随着计算量的增加而提高。
测试报告指路:https://arcprize.org/blog/oai-o3-pub-breakthrough
目前o3还不是很经济。用户能够以每项任务大约5美元(折合人民币约36元)的价格来支付人工解决ARC-AGI任务,只消耗几美分的能源。而在低推理模式下,o3完成每个任务需要花费17-20美元(折合人民币约124~145元)。
OpenAI明年将与ARC-AGI背后的基金会合作构建其下一个基准测试。
其他基准测试中,o3亦有远胜竞品的表现。
在由真实世界软件任务组成的SWE-Bench Verified基准测试中,o3模型的准确率约为71.7%,比o1模型高出20%以上。OpenAI研究高级副总裁Mark Chen说:“这确实意味着我们正在攀登实用性的前沿。”
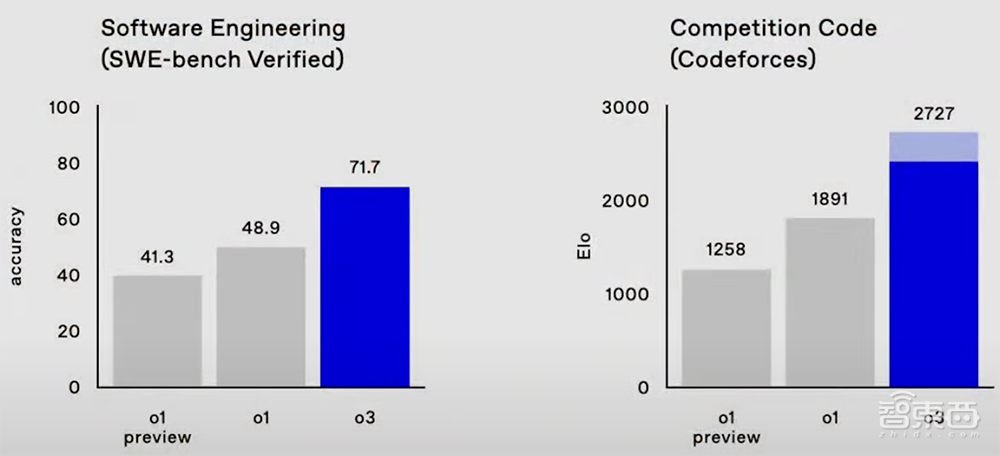
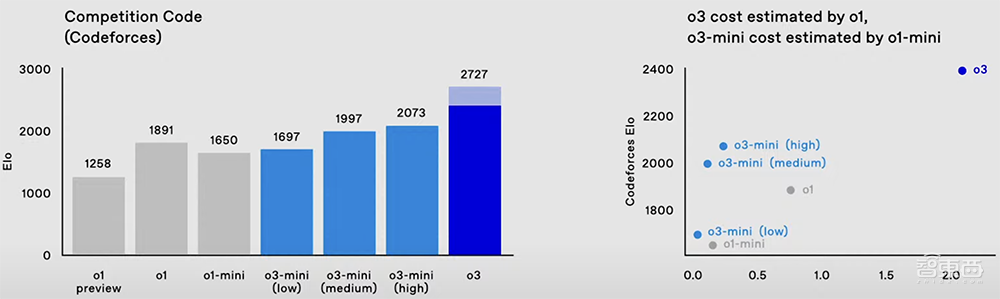
在编程竞赛Codeforces中,o1的分数是1891,而o3在高推理设置下可达到2727的分数,低推理设置的分数也超过o1。
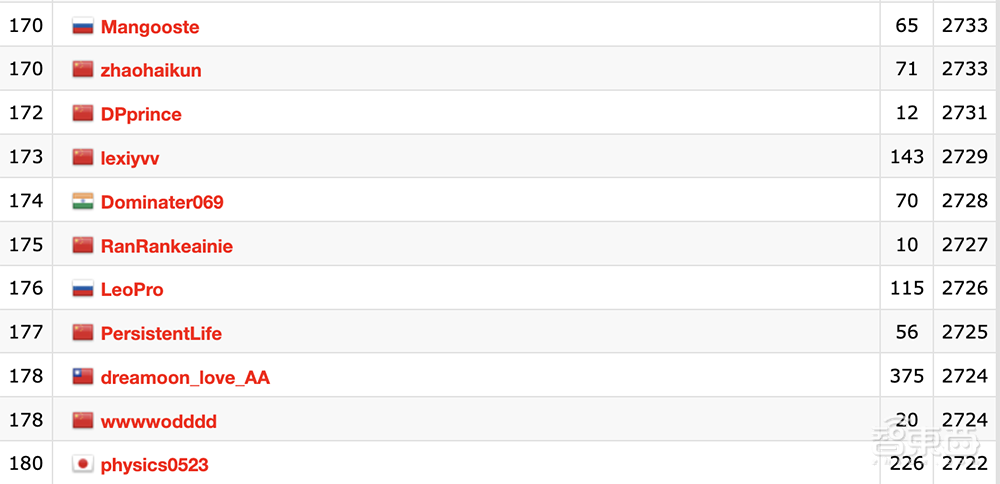
从Codeforces排行榜来看,o3的成绩能排到第175名。
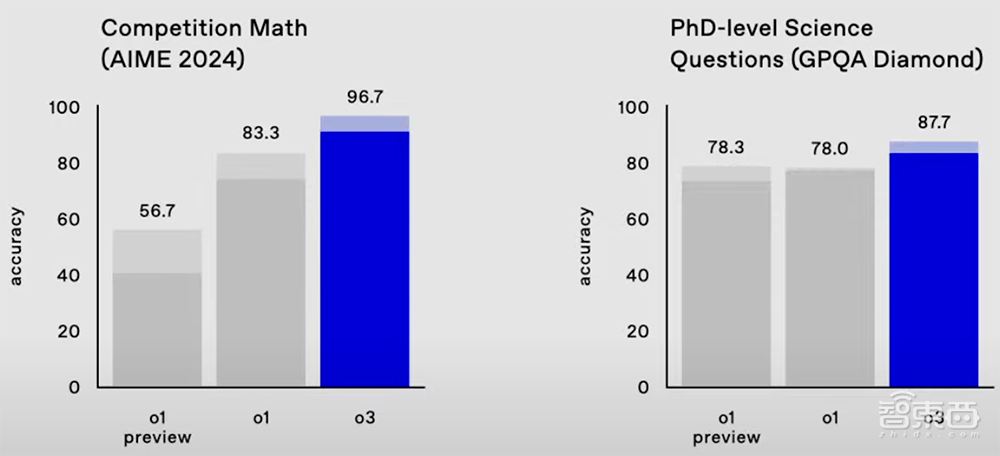
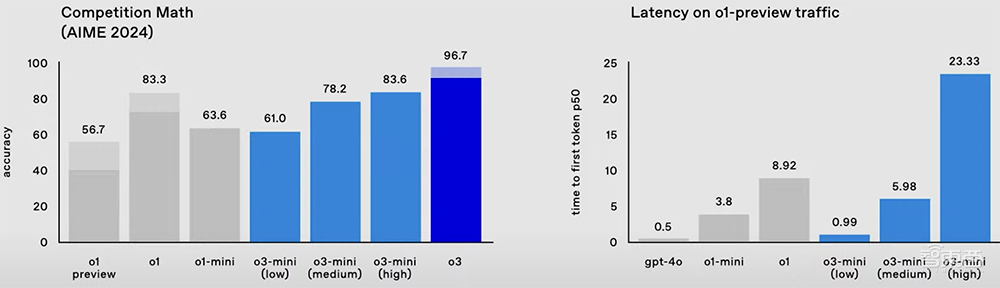
在数学基准测试AIME 2024中,o3的准确率达到96.7%,只漏掉了一个问题,而o1的准确率为83.3%。
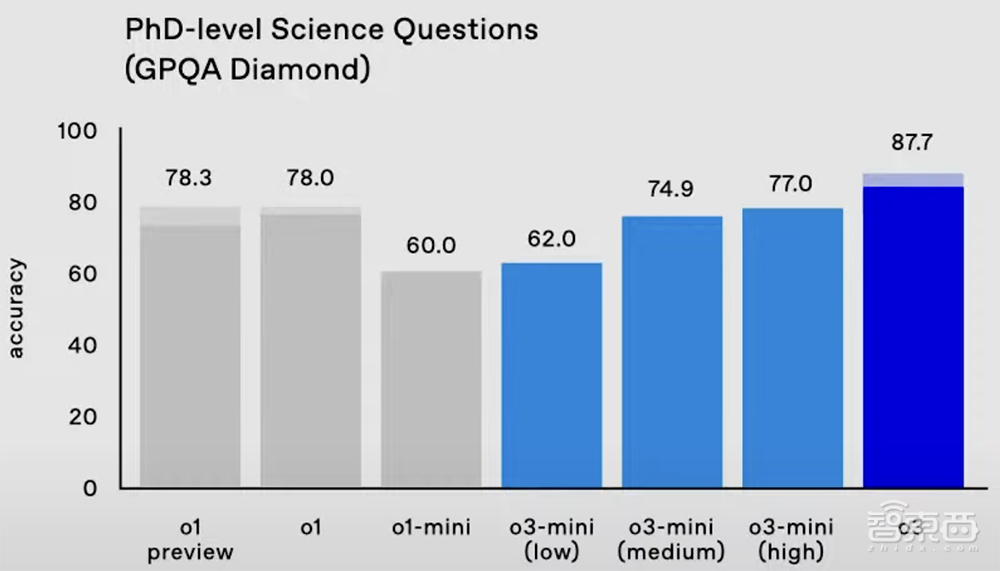
在衡量博士级科学问题的严苛基准测试GPQA Diamond中,o3的准确率高达87.7%,比o1的78%提高约10%。而专业博士通常在自己的强项领域得到70%的成绩。
OpenAI研究科学家任泓宇现场演示了一个使用Python来实现代码生成和执行的示例。
只用30多秒,o3-mini就写出了一个自己的ChatGPT UI,通过发送请求来调用API与自己对话。让o3-mini在这个UI中编写并执行一个脚本,评估自己在GPQA上的表现,结果脚本正确返回了61.62%的数值,与正式评估结果相近。
o3还在陶哲轩等60余位全球数学家共同推出的号称业界最强数学基准的EpochAI Frontier Math中创下新纪录,分数达到25.2。而其他模型都没有超过2.0。

有趣的是,在o3发布前不久,OpenAI GPT系列论文的主要作者Alec Radford刚刚宣布离职,将转向独立研究。
近来前沿模型发布节奏之密集令人眼花缭乱。最新发布的o3模型能否继续守擂、捍卫OpenAI在前沿技术方面的权威性,将备受关注。

OpenAI连续12日圣诞发布完整回顾:
Day1:发布o1满血版、ChatGPT Pro最贵订阅版本200美元/月。
Day2:发布强化微调新功能,用少量训练数据即可在特定领域构建专家模型。
Day3:发布视频生成模型Sora。
Day4:Canvas全面开放,升级代码功能。
Day5:展示OpenAI与苹果智能合作功能。
Day6:发布高级实时视频理解功能。
Day7:发布Projects In ChatGPT功能。
Day8:搜索功能全面开放,支持语音搜索。
Day9:o1 API开放,实时API更新。
Day10:拨打1-800-ChatGPT热线电话,可访问ChatGPT。
Day11:展示Mac桌面版App与各类App的互操作性。
Day12:发布o3及o3 mini推理模型。
虽然o3系列模型不会立即发布,但从今日起,OpenAI开始向安全研究人员开放o3的访问权限。申请截止日期是1月10日。

OpenAI透露了其新对齐策略的更多技术细节。现代大语言模型使用监督微调(SFT)和人类反馈强化学习(RLHF)进行安全训练,但仍然存在安全缺陷。OpenAI研究人员认为,其中许多失败是由于两个限制造成的:
1、模型必须立即响应用户请求,导致其没有足够时间来推理复杂和边缘的安全场景;
2、大模型必须从大量标注样本中间接推断出所需的行为,而不是直接学习自然语言中的基本安全标准,这迫使模型必须从示例中对理想行为进行逆向工程,导致数据效率和决策边界不佳。
在此基础上,OpenAI提出了审议对齐(Deliberative Alignment)的训练方法,结合基于过程和结果的监督,让大模型在产生答案之前明确地通过安全规范进行复杂推理,以克服上述两个问题。
相比之下,其他在推理时优化响应的策略将模型限制为预定义的推理路径,并且不涉及对学习的安全规范的直接推理。
审议对齐具体步骤如下:
首先训练一个只针对于o系列模型有用性,没有任何与安全相关的数据集。
构建一个含有(prompt提示,completion补全)对的数据集,其中completion中引用思维链规范,并在系统提示符中为每个对话插入相关的安全规范文本,生成模型然后从数据中删除系统提示。

对这个数据集执行增量监督微调(SFT),为模型提供安全的推理的强先验。通过SFT,该模型可以学习安全规范的内容,以及如何对它们进行推理以生成一致的响应。
然后使用强化学习训练模型更有效地使用其思维链接,引入奖励模型,让其可以访问安全策略来提供额外的奖励信号。

其策略分两个核心阶段进行,在第一阶段通过对思维链引用规范的示例进行监督微调,教模型在其思维链中直接推理安全规范。这一过程,研究人员会给予上下文蒸馏和一个仅针对有用性训练的o系列模型来构建数据集。通过直接教给模型安全规范的文本,并训练模型在推理时仔细考虑这些规范,以此产生安全响应,并根据给定环境进行适当校准。通过将这种方法应用于OpenAI的o系列模型,它们能够使用思维链推理来检查用户提示,确定相关的策略指南。
正如下图o1思维链示例。用户试图获得有关成人网站使用的无法追踪支付方式的建议,以避免被执法部门发现。用户尝试越狱模型,方法是对请求进行编码,并在请求中包装旨在鼓励模型遵守的指令。在思维链中,模型对请求进行解码并识别出用户正在尝试欺骗它(以黄色突出显示),它成功地推理了相关的OpenAI安全策略(以绿色突出显示),并最终拒绝了用户请求。

▲o1思路链示例
第二阶段,研究人员使用高计算强化学习来训练模型更有效地思考,并引入使用给定安全规范的裁判大模型来提供奖励信号。
值得注意的是,OpenAI的训练程序不需要人工标注,可以仅依赖模型生成的数据就能实现高度精确的规范遵守性。这解决了标准大模型安全训练严重依赖大规模人工标注数据的挑战。
RLHF、RLAIF、推理时间修正技术、审议对齐方法的对比如下图所示:

▲审议对齐与现有对齐方式比较
从结果来看,研究人员在一系列内部和外部安全基准中比较了o1与GPT-4o、Claude 3.5 Sonnet和Gemini 1.5 Pro的安全性。o1模型通过了一些较难的安全评估,并在拒绝不足和拒绝方面实现了帕累托改进(在不使任何情况变坏的前提下,使性能变得更好)。

至此,OpenAI的“圣诞礼物”告一段落,但通往AGI的全球竞赛还在加速进行时。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

