

智源FlagEval“百模”评测:全球100余个AI模型能力比拼




独家抢先看
凤凰网科技讯 12月20日,智源研究院发布并解读国内外100余个开源和商业闭源的语言、视觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。本次评测依托智源研究院的大模型评测平台FlagEval。智源评测发现,2024年下半年大模型发展更聚焦综合能力提升与实际应用。多模态模型发展迅速,涌现了不少新的厂商与新模型,语言模型发展相对放缓。模型开源生态中,除了持续坚定开源的海内外机构,还出现了新的开源贡献者。
此外,国内头部语言模型仍然与国际一流水平存在显著差距。语言模型主观评测重点考察模型中文能力,结果显示字节跳动Doubao-pro-32k-preview、百度ERNIE 4.0 Turbo位居第一、第二,OpenAI o1-preview-2024-09-12、Anthropic Claude-3-5-sonnet-20241022位列第三、第四,阿里巴巴Qwen-Max-0919排名第五;在语言模型客观评测中,OpenAI o1-mini-2024-09-12、Google Gemini-1.5-pro-latest 位列第一、第二,阿里巴巴Qwen-max-0919、字节跳动Doubao-pro-32k-preview位居第三、第四,Meta Llama-3.3-70B-Instruct排名前五。

视觉语言多模态模型,虽然开源模型架构趋同(语言塔+视觉塔),但表现不一,其中较好的开源模型在图文理解任务上正在缩小与头部闭源模型的能力差距,而长尾视觉知识与文字识别以及复杂图文数据分析能力仍有提升空间。评测结果显示,OpenAI GPT-4o-2024-11-20与字节跳动Doubao-Pro-Vision-32k-241028先后领先于Anthropic Claude-3-5-sonnet-20241022,阿里巴巴Qwen2-VL-72B-Instruct和Google Gemini-1.5-Pro紧随其后。
文生图多模态模型,今年上半年参评的模型普遍无法生成正确的中文文字,但此次参评的头部模型已经具备中文文字生成能力,但整体普遍存在复杂场景人物变形的情况,针对常识或知识性推理任务,小于3的数量关系任务表现有所提升,大于3的数量关系依然无法处理,涉及中国文化和古诗词理解的场景对于模型而言是不小的挑战。评测结果显示,腾讯Hunyuan Image位列第一,字节跳动Doubao image v2.1、Ideogram 2.0分居第二、第三,OpenAI DALL·E 3、快手可图次之。
文生视频多模态模型,画质进一步提升,动态性更强,镜头语言更丰富,专场更流畅,但普遍存在大幅度动作变形,无法理解物理规律,物体消失、闪现、穿模的情况。评测结果显示,快手可灵1.5(高品质)、字节跳动即梦 P2.0 pro、爱诗科技PixVerse V3、Minimax、海螺AI、Pika 1.5位列前五。
语音语言模型,得益于文本大模型的进步,能力提升巨大,覆盖面更全,但在具体任务上与专家模型还存在一定差距,整体而言,性能好、通用能力强的开源语音语言模型偏少。专项评测结果显示,阿里巴巴Qwen2-Audio位居第一,香港中文大学&微软WavLLM、清华大学&字节跳动Salmon位列第二、第三,Nvidia Audio-Flamingo,MIT & IBM LTU均进入前五。
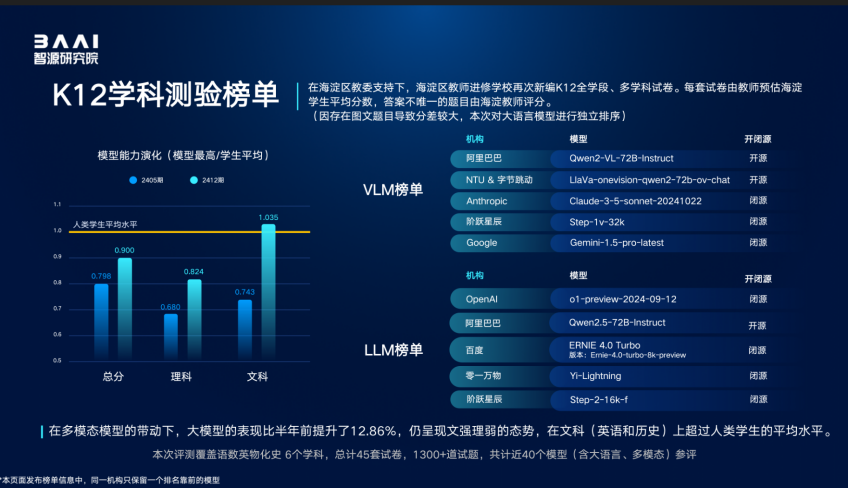
本次评测,智源研究院联合与海淀区教师进修学校新编了K12全学段、多学科试卷,进一步考察大模型与人类学生的能力差异,其中,答案不唯一的主观题依然由海淀教师亲自评卷。得益于多模态能力的带动发展,模型本次K12学科测验综合得分相较于半年前提升了12.86%,但是仍与海淀学生平均水平存在差距;在英语和历史文科试题的表现上,已有模型超越了人类考生的平均分;模型普遍存在“文强理弱”的偏科情况。
FlagEval大模型角斗场,是面向用户开放的模型对战评测服务,以反映用户对模型的偏好。此次评测,共有29个语言模型、16个图文问答多模态模型、7个文生图模型、14个文生视频模型参评。评测发现,用户对模型的响应时间有更高要求,对模型输出的内容倾向于更结构化、标准化的格式。
模型辩论平台FlagEval Debate可对模型的逻辑推理、观点理解以及语言表达等核心能力进行深入评估,以甄别语言模型的能力差异。本次评测发现,大模型普遍缺乏辩论框架意识,不具备对辩题以整体逻辑进行综合阐述;大模型在辩论中依然存在“幻觉问题”,论据经不起推敲;大模型更擅长反驳,各个模型表现突出的辩论维度趋同,在不同的辩题中,模型表现差距显著。FlagEval Debate评测结果表明,Anthropic Claude-3-5-sonnet-20241022、零一万物Yi-Lighting、OpenAI o1-preview-2024-09-12为前三名。
此次还评测了模型的量化代码实现能力,探索模型在金融量化交易领域的潜在应用能力和商业价值。评测发现,大模型已经具备生成有回撤收益的策略代码的能力,能开发量化交易典型场景里的代码;在知识问答方面,模型整体差异较小,整体分数偏高,但在实际代码生成任务上,模型差异较大,整体能力偏弱;头部模型能力已接近初级量化交易员的水平。金融量化交易评测结果显示,深度求索 Deepseek-chat,OpenAI GPT-4o-2024-08-06,Google Gemini-1.5-pro-latest位列前三。
在智源秋冬评测发布会后,智源研究院副院长兼总工程师林咏华接受了凤凰网科技等媒体的采访,就评测结果显示当前语言模型发展放缓具体原因,林咏华谈到,现在进入了语言模型的深水区,深水区创新的难度会更大。最优秀的语言模型已经发展了一定的基础能力,再明显的增长不是特别容易,不能只是拼更大的参数或更多的数据这条路,而是需要更多的深入创新才能提升,因此,会看到更新更大的语言模型出现的频率有所减缓。
对于大语言模型未来发展方向,以及语言模型未来发展需要哪些深刻变革的问题,林咏华认为,从全球模型的发展情况看,模型尺寸出现两极分化。11月Hugging Face下载量最高的模型来看,一类是更大更强的稠密模型,像Llama3.1的405B全球一个月的下载量是七八百万,是最高之一。但是剩下的高下载量很多是7B或以下的小模型,所以可以看到明显的两极分化。
关于大模型未来的变革,林咏华谈到,2025年预计多模态模型会层出不穷,包括开源模型,会有更多新的多模态模型。比如K12学科测试,图文模态提升了多模态模型对人类试卷的理解和推理能力。具身智能,也依赖于多模态模型,对物理世界进行理解和感知。多模态模型的需求是蓬勃发展,但是,还没有像很多语言模型那样,基础能力已达到了一定水平,多模型在基础能力上有明显的提升空间。

