

贴身追随OpenAI的中国公司,从智谱换成了月之暗面




独家抢先看

大洋彼岸的OpenAI系列春晚还在继续,连续发布会的第9天,OpenAI正式发布了o1模型的API。
对已发布的圣诞季特别功能们略作盘点:满血版o1模型VSChatGPT Pro订阅计划、年初引爆全球的鸽王——视频生成模型Sora全面开放、全新Canvas写作功能、ChatGPT正式接入苹果全家桶、GPT-4o的视频通话和屏幕共享功能,重构AI协作模式的复杂项目Projects……
这些发布与过往OpenAI一次次的模型更新相比,已经完全不同。这家标杆性公司正在向着一家产品公司转变。
而作为中国公司们一直以来设计技术路线和融资叙事时最重要的参照物,在OpenAI转变时,对OpenAI贴身跟随最紧的中国追随者们,也悄然发生了“更替”。
1
智谱,比OpenAI还OpenAI
此前,智谱一直是那个最高调的跟随者。在最近有媒体发布的智谱融资路演PPT里,有技术路线的地方,就有OpenAI。
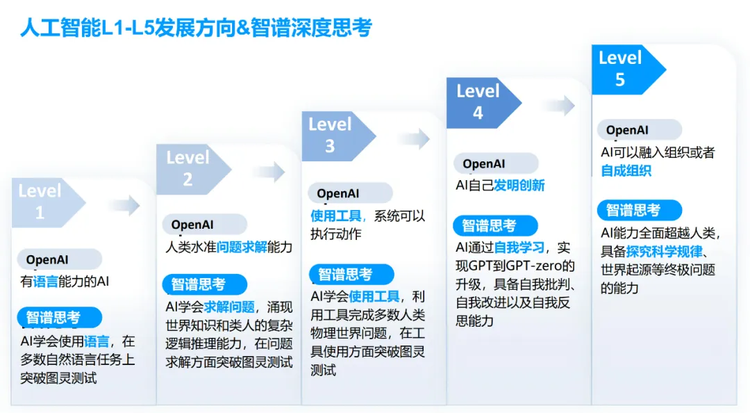
作为成立于2019年的清华系公司,智谱在涉及大模型链路的许多方面推出了丰富的产品,这里包含各种尺寸的通用GLM大模型,还有基于通用模型而来的对话产品、AI助手智谱清言,代码模型CodeGeeX,文生图模型CogView以及多模态对话模型VisualGLM,多模态理解模型CGVLM,智能体产品AutoGLM甚至还有硬件,从算法到产品,智谱实现了完全自研。
这家在OpenAI的ChatGPT一鸣惊人之前,就投身大模型研发的公司,强调自己与OpenAI的英雄所见略同。他坚持着预训练的大模型的研发,也想抓住API市场实际上同时存在B端和C端两类用户。
在2023年下半年,行业中对百模大战下一阶段是什么的回答大多聚焦于用行业数据训练垂直大模型,但智谱选择跟OpenAI一样,相信通用大模型的能力。它也继续紧跟OpenAI的发布节奏,进入2024年,智谱先后发布了对标Sora的视频生成模型CogVideoX,以及对标GPT-4o的端到端语音模型GLM-4-Voice和GLM-4-VideoCall。
这样的策略从融资结果上来看,起到了效果。
智谱最新完成的新一轮30亿元融资,与9月海淀区政府设立的市场化投资平台——中关村科学城公司领投之时,所述的投资原因主旨趋同,用于支持轮基座大模型的研发,这些融资使得智谱估值超过了200亿元,成为估值最高的大模型公司之一。国资外,智谱背后的投资方还包括高瓴、启明、君联,以及美团、阿里、腾讯、小米在内的大厂。
而这种跟随也在近期开始出现分野。当OpenAI转向产品公司,智谱其实依然不那么to C,他们对外的表态,依然要坚持花精力在预训练模型,而融资中透露的关键信息,也是toB为主的营收带来的商业化收入翻倍。相较于2023年,今年以来智谱商业化收入增长超100%。其MaaS(模型即服务)平台API年收入同比增长超过30倍,这一平台已经吸引了70万企业和开发者用户,付费客户数增长超20倍,在商业化和企业业务中的渗透率越来越高。
相比OpenAI在向一家产品公司转变中在意的能力,智谱拿到的这些客户显然还是更看重模型能力。这让智谱看起来倒是比今天的OpenAI更像以前那个OpenAI。
“OpenAI虽然也toB,但toC能力也还不错,跟智谱从产品线上已经不完全对标。”一位头部VC合伙人对比两者现状表示。
1
月之暗面成了OpenAI最新的贴身追随者
智谱发布融资消息之前一天,月之暗面发布了它的“视觉思考模型”k1,并上线最新版的网页版以及安卓和 iOS APP。
在介绍中,继不久前的数学模型k0-math对标OpenAI的o1之后,k1再次对标了OpenAI的o1和GPT-4o。
月之暗面俨然成了新的OpenAI贴身跟随者。
作为一家很少在模型侧公开发声的头部模型公司,一个月内更新了两款k系列模型。
在月之暗面年初声名鹊起之后,创始人兼CEO杨植麟为其树起了最看好大模型To C的国内AI技术理想主义大旗,“只看好To C,因为公司的目标是AGI(通用人工智能),而AGI在To C的前景远超To B。”杨植麟今年一季度多次表示。
在谈及OpenAI时,他年初在采访中提到,做模型公司应该去理解AGI与产品之间的关系,“对我们来说并不是手段和目的,两个都是目的”;“ChatGPT还没有完全建立起基于用户数据的持续进化”;“一个不足够关心用户的公司最终可能也没法实现AGI。”
这说明,当时的他想跳脱出OpenAI的叙述逻辑,通过谈论OpenAI讲述自己的故事。
而今天来看,这样的叙事也有更现实的考虑。最近仍未结束的围绕张予彤的争议里,许多细节被公布出来,其实这些信息也透露着月暗对于自己融到的资源的使用方式。
对于大模型企业来说,融资至关重要,融到与头部几家同等规模的资金则直接决定了最初阶段能否坐上台桌。这也是张予彤发挥的关键作用,连续几笔关键融资让月暗估值近217亿,成为六小虎之一。这些资金如李开复所说,足够每家做预训练。但言外之意是,是否做和如何做则不一定了。
从杨植麟此前的一系列采访和对话里看,他是个“等得起”的人。比如,他谈到做出聚焦Kimi的决定,称大概今年二三月份,三四月份,基于美国市场判断,基于自己的观察,提出聚焦Kimi。“要把一个产品做到极致很重要。砍业务等于本质上也在控制人数,现在三个业务一起做,就活生生把自己变成一个大厂,没有优势。”
比如在模型上,月之暗面从来没有整体介绍过自己的模型,而选择了其中一个能力——上下文长度来集中展示。相比于智谱的产品线,这显然在资金上也同样更加划算。
比如在此前的表述中,杨植麟很在意月暗的人数,“我们是这一拨公司里人数最少的”。
在OpenAI代表着卷预训练的阶段,不是每个人都跟得起OpenAI。某一线投资人告诉硅星人,月之暗面的逻辑是Kimi好用就行,就不是卖模型的逻辑,所以他们也不频繁推出模型,当然这其中模型的工作很重要。它不需要贴身紧跟OpenAI,吃力不讨好,但在所有人必须靠对标OpenAI来积累更好的资源的时期,这不仅让月暗此前和另外几个对标OpenAI更深的大模型公司显得不同,也让它的融资需要走另一条路。
直到OpenAI GPT-5的彻底难产和o1的推出,以及背后关于Scaling law撞墙的讨论甚嚣尘上,因张予彤的事件而注定会在融资上受到影响的月暗,对标OpenAI的策略也变了。
最近在NeurIPS 2024的舞台上,Ilya Sutskever以其标志性的简洁,用15分钟揭示了人工智能的最新洞见,最震撼的无过于以预训练为代表的Scaling law“终结”的讨论:“Pre - training as we know it will end.(我们所熟知的预训练即将终结。)” 。紧随其后,OpenAI大神级人物、o1核心成员Noam Brown也发表一番言论,称o1代表着一种全新的以推理计算为核心的Scaling 模式,这些将Scaling law的终结讨论推至高点。
杨植麟敏锐地捕捉到了这一点,他在9月o1刚推出后的一次公开分享里,花了很多篇幅解读刚刚出世的o1,他说今天AI的效率提升很惊人,推理成本的下降很迅速,还说在做Kimi的时候,希望能把产品和模型更紧密地结合在一起去思考,“而且这个Scaling现在也发生了一些变化,原来大部分Scaling发生在训练阶段,但是现在大部分的计算,或者说越来越多的计算会转移到推理阶段。”
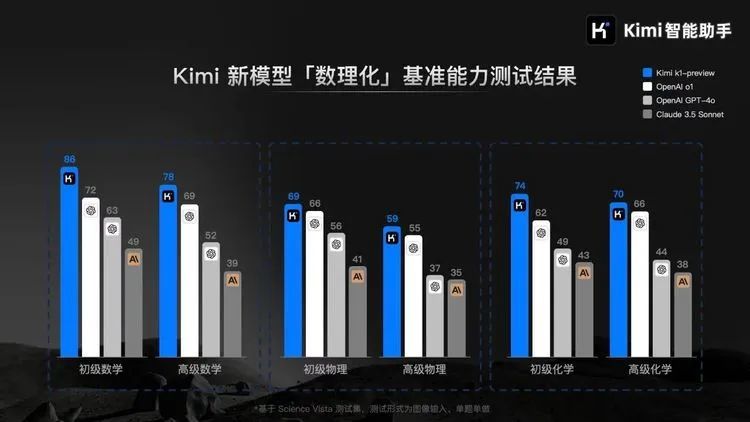
之后月之暗面开始发布他们自己的o1系列,并用起了此前在智谱等公司发布模型时常用的“击败GPT”的策略。在最近视觉思考模型K1发布后,月暗表示,它的数理化能力表现超越OpenAI o1,在K0-mathe身上,月暗称,在业界最常使用的数学能力基准测试MATH 中,k0-math初代模型成绩超过了OpenAI旗下o1-mini和o1-preview。
当OpenAI们都默认了预训练已经变得不那么重要,不去重金投入预训练自然变得合理,当OpenAI变成了一家产品公司,早早就喊出要死磕产品的中国公司自然要贴身跟随上去。
据硅星人了解,与智谱同频,头部大模型公司中的至少两家都在推进自己的新一轮融资计划,但是是否发布融资消息,可能各有考量,大厂方面,字节、阿里在年末对大模型公司也都有投资计划。结合各家技术线、产品线动作看,虽然有些困难声音出现,但总体来讲大家都还在焦灼竞争,并没有分出真正的胜负。
而在今天中国的大模型公司竞争里,OpenAI依然是各家绕不开的那个标的,尤其是融资的过程里,你和世界一流公司的那个隐秘联系决定着很多事情。
追随OpenAI的策略还会继续下去,大家会继续各取所需。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

