

OpenAI狂飙突进!仅12个例子就能打造专属AI专家,核心技术竟来自字节?
OpenAI“12 天”活动的第二天,我们见证了强化微调(Reinforcement Fine-Tuning)技术的正式发布,并看到了 ChatGPT Pro 的演示。虽然 Sam Altman 并未亲临现场,但他的团队为我们深入解析了这项技术,预示着 AI 模型定制化或将迎来重大突破。
12 个例子就可定制专家模型
今天的发布会带来了一个看似不起眼但可能对人们生活产生重大影响的公告。
今天的发布对企业用户来说很惊喜。各组织将能够使用极少的数据,通过“强化微调”(Reinforced Fine-Tuning)根据自身需求对 o1 mini 进行定制。
一些人可能对去年年初 OpenAI 推出的监督微调 API 已有所了解。监督微调是一种强大的工具,其主要作用是让模型模仿输入文本或图像中发现的特征,对于需要调整模型的语气、风格或响应格式的场景,这种方法非常实用。但监督微调需要特地领域的大量数据。而强化微调的优势在于,它能够通过极少量的高质量示例,快速调整模型的推理方式。这种高效性在以往的监督微调中是难以实现的。
强化微调的工作原理是:当模型遇到问题时,给予其一定的思考空间以解决问题,然后对模型的最终答案进行评分。通过强化学习的机制,强化那些通向正确答案的思路,同时削弱导致错误答案的思路。
而 AI overview 给出的相关论文,居然是今年 1 月份来自字节跳动在 ACL 2024 顶会论文,并不是 OpenAI 首创。

根据论文,强化微调 (ReFT) 从监督微调 (SFT) 开始,通常持续一到两个周期。在此阶段,模型获得了正确解决数学问题的基本能力。在此之后,ReFT 通过使用近端策略优化 (PPO) 等方法采用强化学习 (RL) 算法,将模型的训练提升到一个新的水平。这个高级阶段允许模型探索和学习各种正确的解决方案和推理方法。在此背景下,ReFT 之所以高效,是因为它使用了现有的训练数据,这些数据中已经包含了正确的答案。
这些答案构成了 PPO 训练过程中奖励的基础,从而无需额外的、单独训练的奖励系统。这与 RLHF 等其他方法有着重要区别,后者依赖于由人工注释的数据确定的奖励。
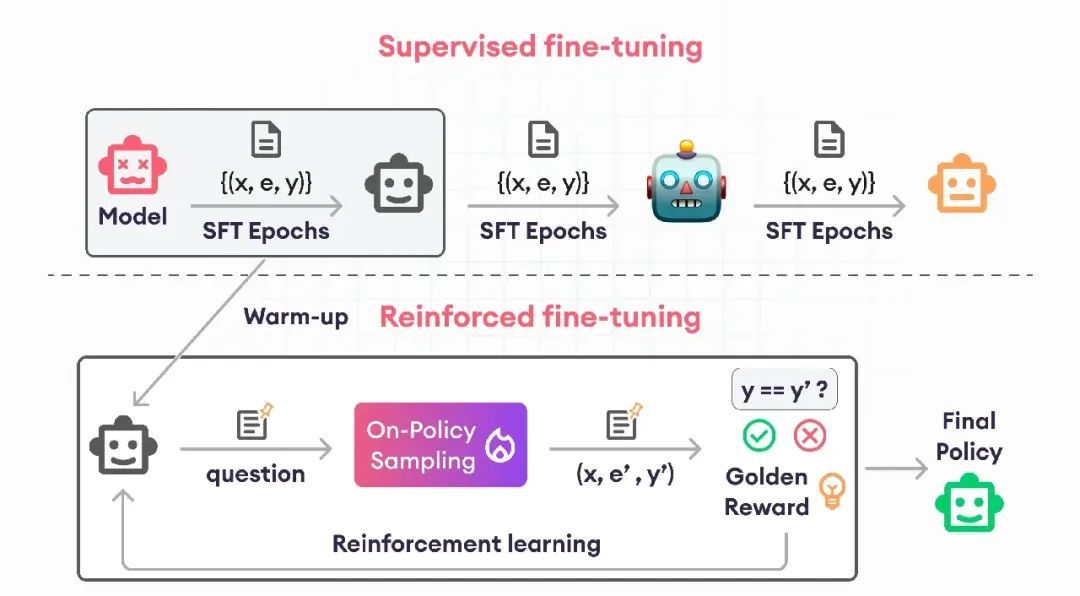
截图来源:https://arxiv.org/pdf/2401.08967v1
值得注意的是,OpenAI 表示基于强化微调,只需几十个示例,模型便能掌握在特定领域中以新的、有效方式进行推理的能力。
实际上,“只用 12 个例子就能做到这一点,这在常规的微调中是做不到的。”发布会上,OpenAI 的研究员 Julie Wong 进一步强调。
强化微调的效果也很惊人,得分不仅比 o1 mini 高,而且还反超了昨天刚发布的 o1 版。
OpenAI CEO Sam Altman 虽然没有 出现在今天的直播中,但他在 X 平台上讨论了这一宣布。他声称新功能“效果惊人,是我 2024 年最大的惊喜之一”。
当然,Altman 对宣传自己公司的新想法有既得利益,但考虑到 2024 年 OpenAI 推出了很多令人兴奋的东西,他称之为今年最大的惊喜之一,这无疑是高度赞扬。
根据 OpenAI 的演讲者介绍,科学家、开发人员和研究人员可以基于自己的数据定制强大的 o1 推理模型,而不再仅仅依赖公开可用的数据。
各领域的从业者可以通过强化学习创建基于 o1 的专家模型,从而提升该领域的整体专业水平。这标志着 AI 定制化迈出了关键一步,使得 AI 模型能够在专业领域展现出更出色的表现。
现场演示强化微调对大模型的提升
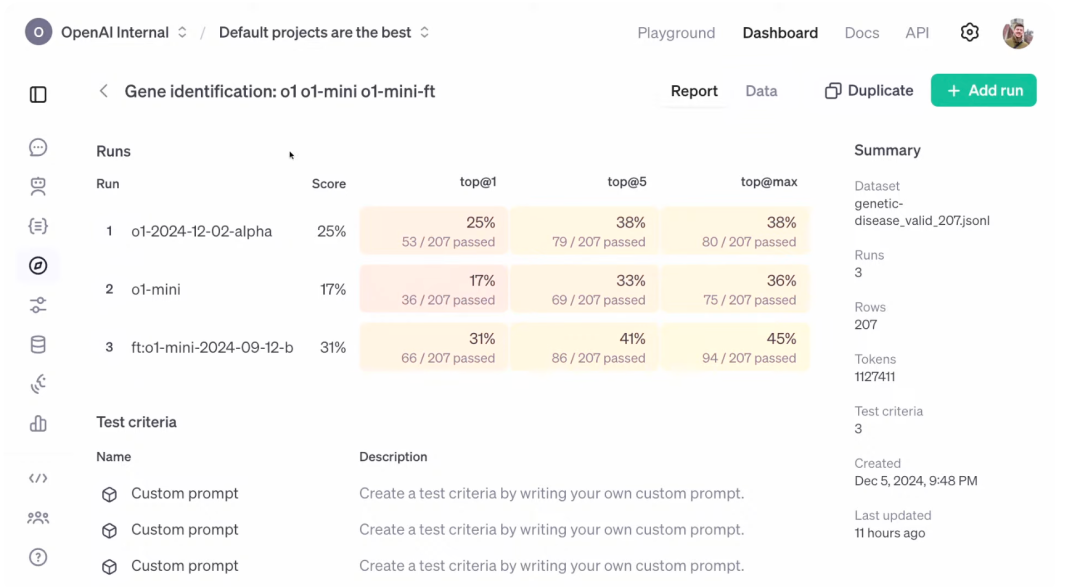
在现场,OpenAI 研究员用伯克利实验室计算生物学家 Justin Reese 演示了强化微调如何大幅提高 o1 mini 的性能。具体来说,就是给定了症状列表,让模型来预测是哪个基因可能导致的遗传疾病。
首先,查看用于训练模型的数据集和用于评估模型的评分器,Justin 团队收集了一个包含大约 1,100 个示例的数据集,训练数据集只是 JSON-L 文件,文件中的每一行都是你希望模型在其上进行训练的示例。此外,演示中还上传了验证数据。
“验证数据集和训练数据集之间在正确基因方面没有重叠。这意味着模型不能作弊,或者它不能学会仅仅记住症状列表并将其与基因关联起来,它必须从训练数据集泛化到验证数据集。“OpenAI 研究院 John Allard 解释道。

然后,在 OpenAI 的训练基础设施上启动一个训练作业。在网页界面可选择训练集和验证集,并进行相应配置即可。
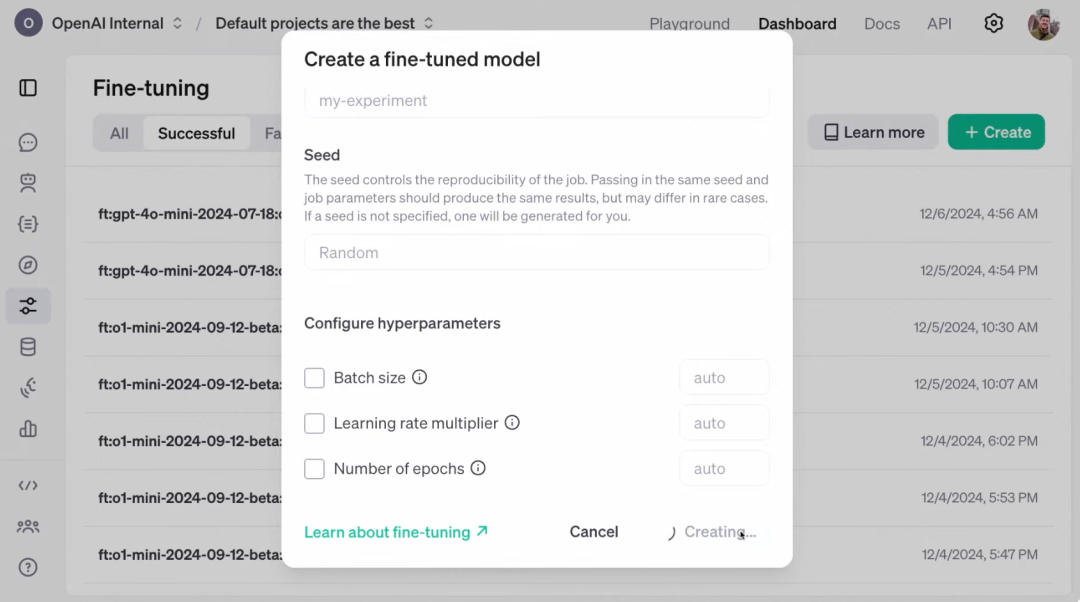
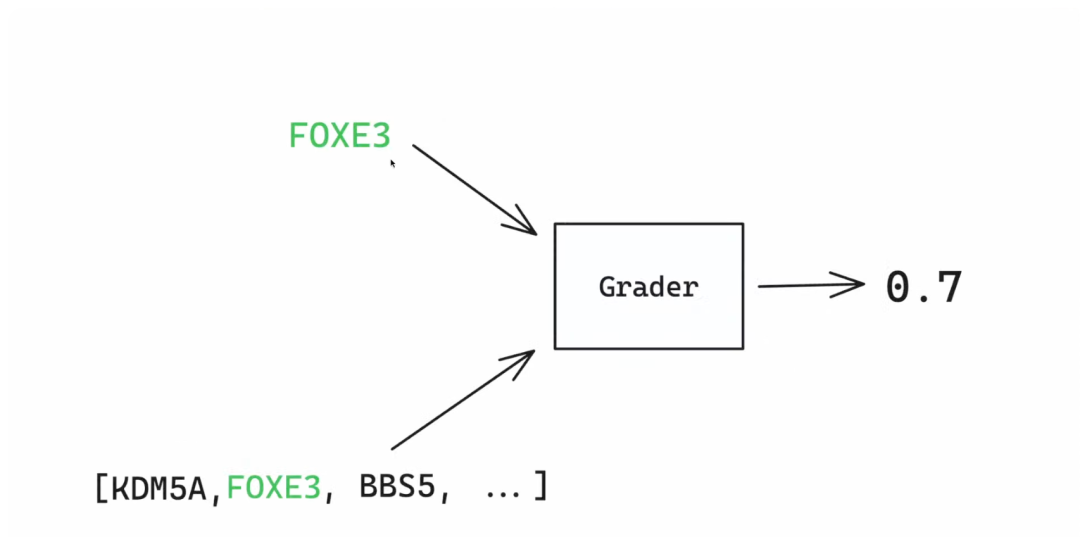
最后评估生成的微调模型,以便可以看到它比开始使用的基础模型改进了多少。评分器功能很简单,就是获取模型的输出和正确答案,对其进行比较,然后返回一个介于 0 和 1 之间的分数。0 表示模型根本没有得到正确答案,1 表示模型得到了正确答案。
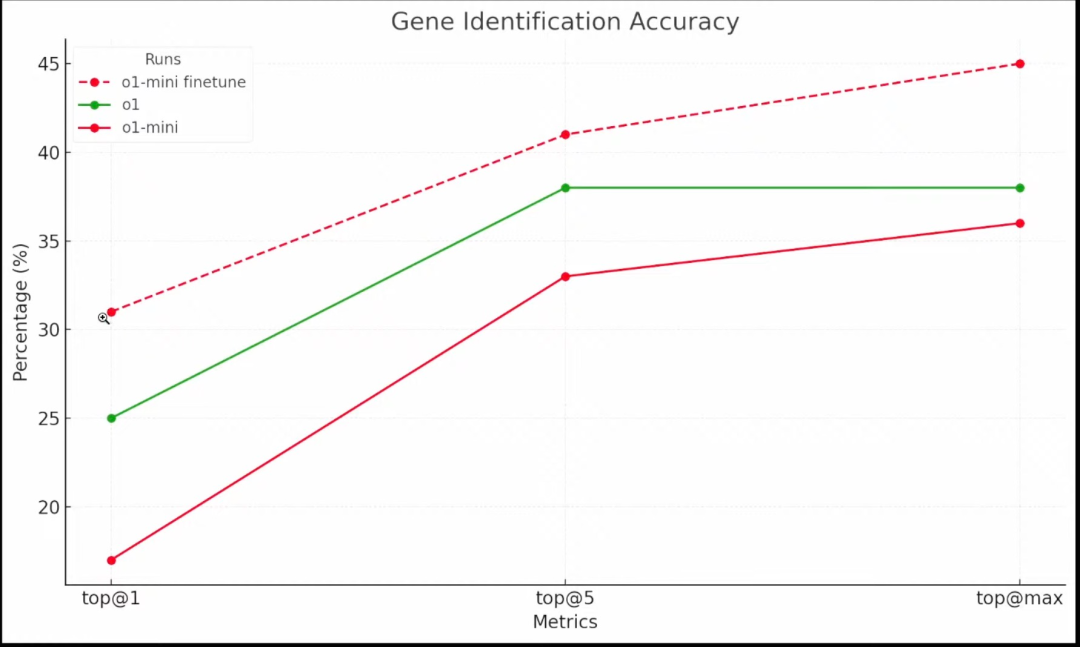
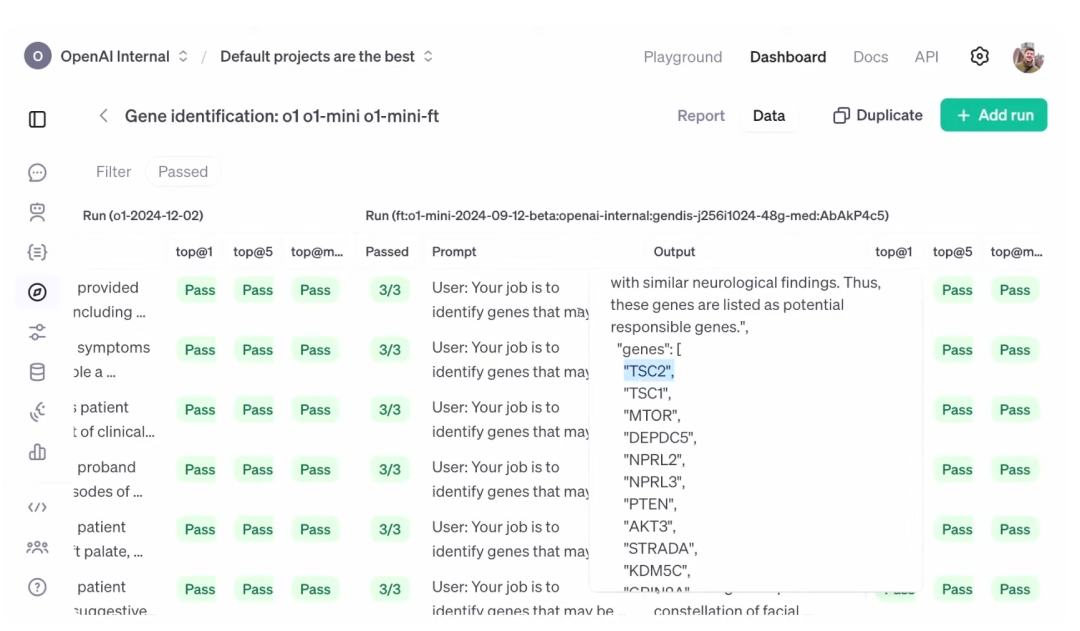
Allard 表示,强化微调可能需要几个小时到几天的时间才能运行完成,因此他展示了此前相同数据集上运行的结果。模型给出的是最有可能的候选基因也是 TSC2,正确答案也确实如此,因此,模型能够在 top at 1、top at 5 和 top at max 上都通过。
此外微调过程中,还可以观察模型性能指标的变化趋势:
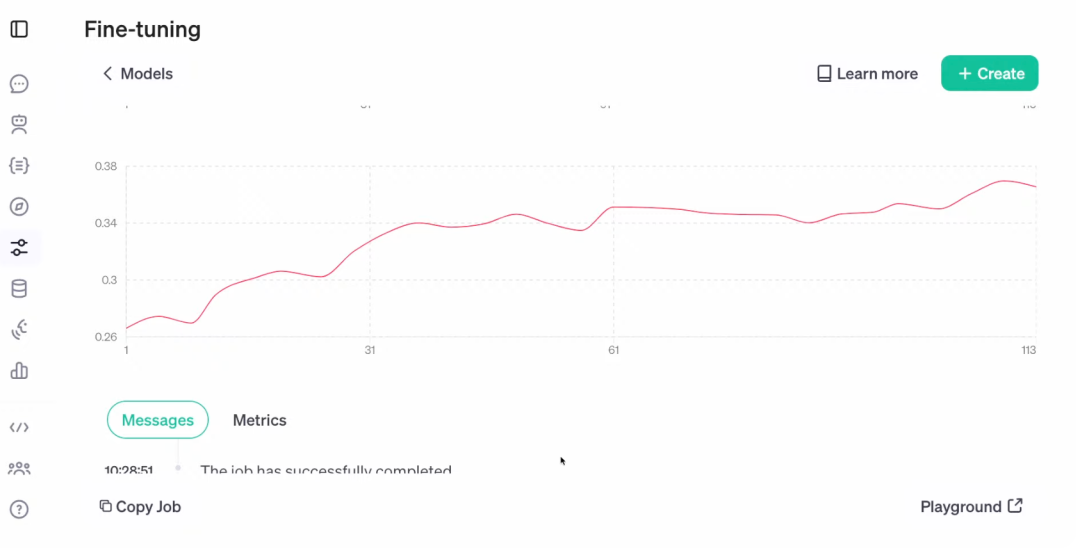
测试中,OpenAI 设置了三个不同模型的运行:第一个是针对昨天发布的 o1 模型,第二个是针对 o1 mini,最后是强化微调后的 o1 mini。可以看到,o1 mini 在大约 200 个数据集上获得了 17% 的得分,o1 做得更好,获得了 25%,而微调后的 o1 mini 获得了 31% 的得分。
结束语
OpenAI 的 12 天活动周末暂停。并不是每项公告都会轰动一时,OpenAI 自己也表示,可以期待“大大小小的”新事物。
以下是外媒列出的一些在下周活动中可以看到的内容(其中还会有一些惊喜):Sora - ai 视频生成、Canvas 更新(可能包括图像)、GPT-4o 视频分析、GPT-4o 图像生成、高级语音与视频等。
奥特曼在推特上与网友的互动,似乎暗示了接下来的 10 场直播会报告 Sora 的最新动态。

