

OpenAI草莓模型深夜突袭!理化生达博士生水平,比GPT-4o强多了,ChatGPT可用




独家抢先看
作者 | 香草
编辑 | 李水青
智东西9月13日报道,今日凌晨,OpenAI突然发布传说中“草莓”模型的部分预览版——OpenAI o1预览版。这是一系列全新AI模型,能推理复杂的任务,解决比以前科学、编程、数学模型更难的问题。
▲OpenAI发布o1模型
OpenAI o1是全新系列AI模型的第一款。与以往模型不同的是,它拥有进化的推理能力,会在回答前进行缜密思考,生成一个长长的内部思维链,在竞争性编程问题上排名第89位,在美国数学奥林匹克预选资格赛中排名前500,在物理、生物、化学问题的基准测试中准确度超过了人类博士水平!
新发布的另一款o1 mini是一款更快、更小的模型,使用与o1类似的框架进行训练。o1 mini擅长理工学科,尤其是数学和编程,其成本比o1预览版便宜80%。
这两款模型被OpenAI视为复杂推理任务的重大进步,因此被命名为o1,重置计数器,而非作为GPT系列的延续。
不过,推理增强版的o1模型,还是在9.9和9.11比大小这种“高阶问题”上惨败。
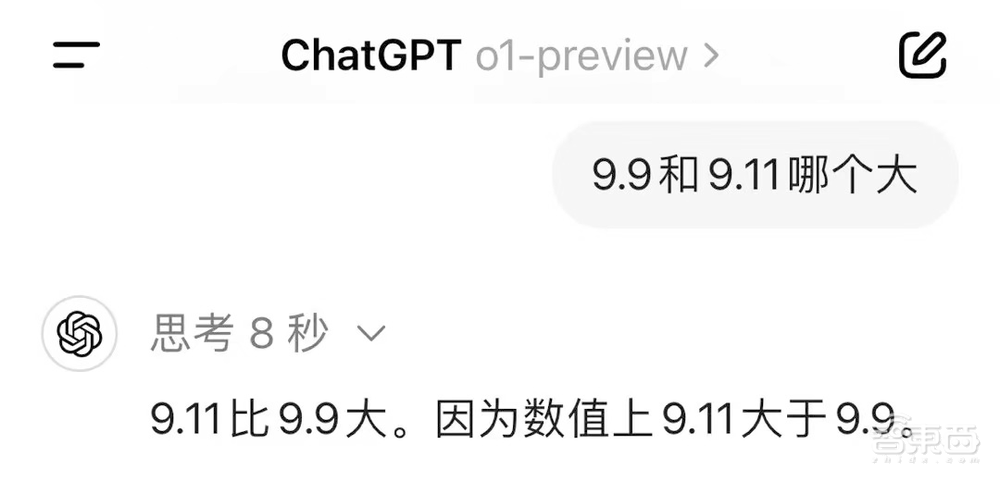
▲o1模型回答“比大小”问题
已经离开OpenAI创业的OpenAI创始成员、前特斯拉AI高级总监Andrej Karpathy今早发文吐槽:“o1-mini一直拒绝为我解决黎曼假设。模型懒惰仍然是一个主要的问题😞”

▲Andrej Karpathy吐槽o1 mini“懒惰”
OpenAI已对o1预览版进行严格测试及评估,确保该模型可以安全发布。ChatGPT的Plus和Team用户即日可选用两款新模型,Tier 5级开发者亦率先获得新模型的API访问权限。
OpenAI还公布了o1模型背后的核心团队成员,其中基础贡献成员21名,包括已经离职创业的前OpenAI首席科学家Ilya Sutskever,团队负责人有7名。
一、MMLU媲美人类专家,编程能力8倍杀GPT-4o
与此前曝料的一样,OpenAI o1被训练成为会花更多时间思考问题,而后再作出反应的模型。它在回答之前会先思考,产生一个很长的内部思路链,并且能像人类一样完善自己的思维过程,不断尝试新的策略并认识到自己的错误。
作为早期预览模型,OpenAI o1目前只支持文本对话,不具备浏览网页获取信息、上传文件和图片等多模态能力。
性能方面,OpenAI o1在物理、化学和生物学等基准任务上的表现与博士生相当,并且在数学和编程方面表现出色。
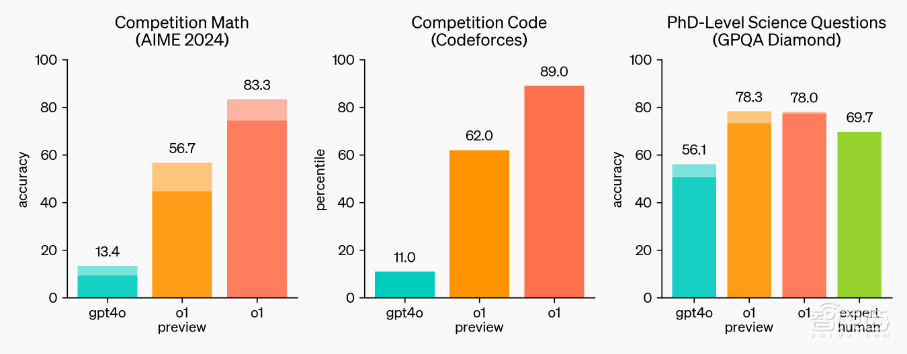
▲OpenAI o1在数学、编程上的测评基准
在国际数学奥林匹克(IMO)资格考试中,OpenAI的上一代模型GPT-4o正确率为13%,而OpenAI o1则达到83%。在编程比赛Codeforces中,OpenAI o1的分数为89,而GPT-4o仅有11。即使是预览版的o1-preview模型,性能也比GPT-4o要好数倍。
在大多数基准测试中,o1的表现都比GPT-4o要好得多,覆盖57个MMLU子类别中的54个。在启用视觉感知功能后,o1在MMLU上的得分为78.2%,成为第一个与人类专家相媲美的模型。
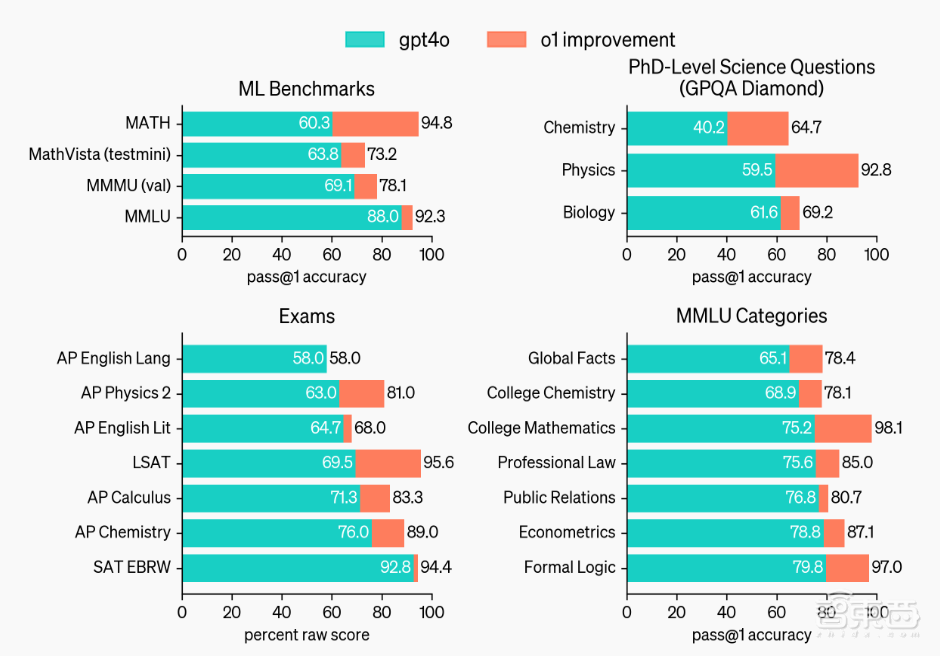
▲o1预览版与GPT-4o性能对比
以下是OpenAI o1预览版几个示例:
1、解决一个复杂的逻辑难题
输入一个复杂的年龄谜题:当公主的年龄是王子的两倍时,当公主的年龄是他们现在年龄总和的一半时,公主就和王子一样老了。问王子和公主的年龄是多大?给出这个问题的所有解决方案。
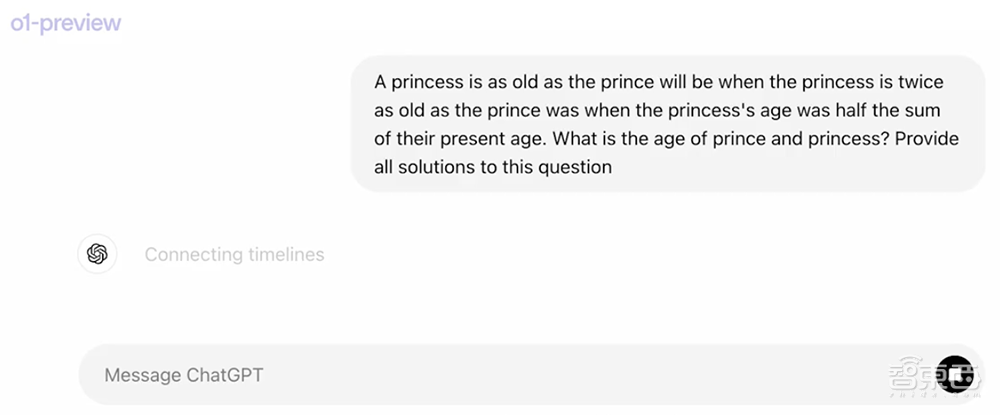
模型思考了20多秒后开始作答。其回答过程的逻辑非常连贯。首先是确定年龄方程,将给定语句转化成数学方程,找到满足这些方程的所有可能解。然后开始一步一步分析问题:
第一步定义变量,用P代表prince(王子),用Q代表princess(公主);第二步理解问题中的两个条件;第三部将条件转化为方程;第四步解方程;第五步用这些值验证所有条件;第六步给出所有可能的解法。
最后得出结论:

2、翻译有错误的句子
添加额外不必要的辅音会影响韩语阅读。母语使用者读起来会感觉不自然,他们会在看到这类句子时自动更改并理解文本。但这对于模型来说是个有难度的挑战。
输入一个严重损坏的韩语提示词后,OpenAI o1首先意识到输入文本存在乱码或未对齐的韩语字符,询问用户是否愿意检查输入错误。

o1模型会首先理解底层结构,经过大约10秒的思考来解码乱码文本、破译文本、加强翻译、理解概念,将其转换回连贯语言。

与GPT-4o不同,o1模型在输出答案前先对问题进行了思考,检查这段文字,然后像破解答案一样来将其修改成正确的句子。经过大约15秒的思考,o1给出最终优化版的翻译。
这展示出推理能力成为解决问题的有力工具。
3、回答大语言模型中的知名棘手问题:单词中字母计数
这个例子很简单,输入Strawberry单词,让模型回答这个词里有几个R。
结果GPT-4o给出错误回答:“2个。”

为什么这种高级模型会犯如此简单的错误呢?这是因为像GPT-4o这样的模型是为了处理文本而构建的,而不是处理字符或单词,因此它在遇到涉及理解字符和单词概念的问题时可能会犯错。
而基于推理的新模型o1在思考几秒钟后,能够给出正确答案:

4、编程视频游戏
让模型用pygame制作一个名为《寻找松鼠(Squirrel Finder)》的视频游戏,并输入下述要求:用户需要通过按箭头键引导屏幕上的“考拉”图标,避开漂浮的草莓,并在3秒的时间限制内找到一只松鼠,以取得胜利。

这对以前的模型来说比较难,但o1预览版已经能够做到。o1花了21秒思考,用思维过程来规划代码结构,包括收集游戏布局的细节、绘制指令、设置屏幕等等,再输出最终的游戏编程代码。
复制粘贴代码到Sublime Text编辑器中,运行后,会先有几行简要提示语。

然后就可以开始玩《寻找松鼠》游戏了。
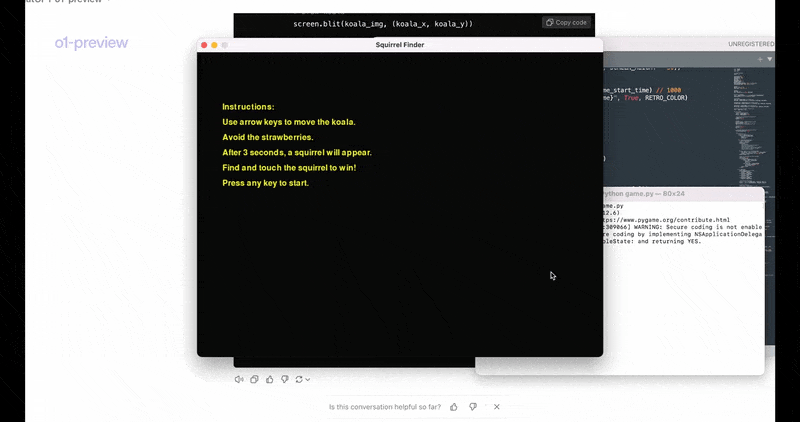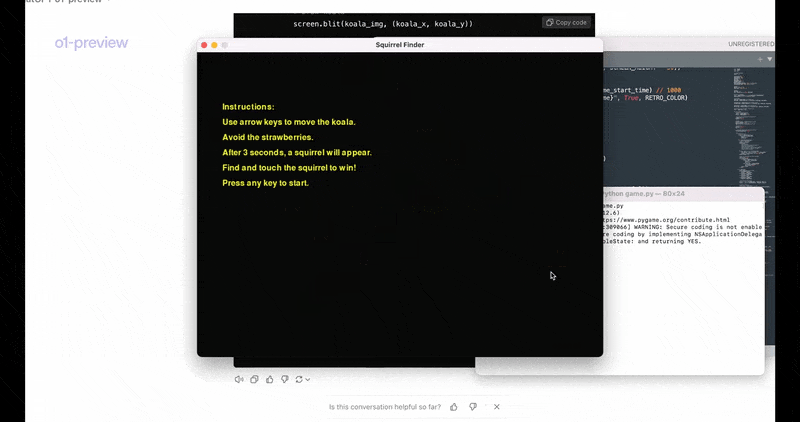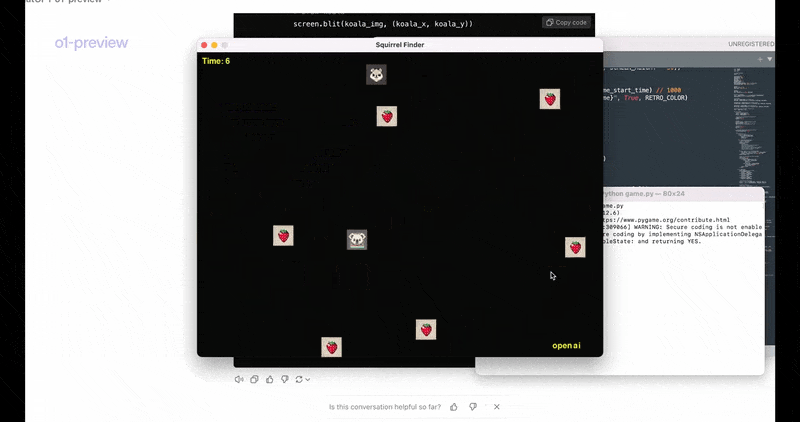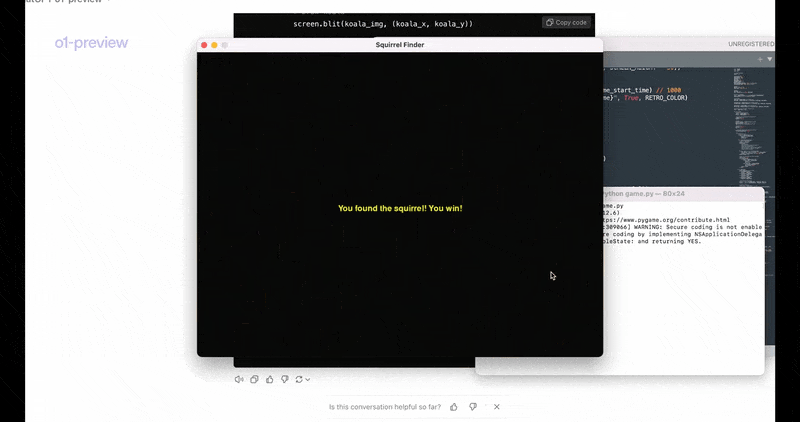
与以前的模型相比,o1模型展现出明显增强的规划能力。
二、迷你版速度提升3~5倍,成本仅为标准版1/5
OpenAI还发布了“小杯版”模型OpenAI o1-mini,其速度更快、成本更低,且与标准版一样在数学、编程方面表现突出。
OpenAI o1-mini在预训练期间,针对STEM(科学、技术、工程、数学四门学科)推理进行了优化。在使用与o1相同的高计算强化学习(RL)管道进行训练后,o1-mini在许多推理任务上性能优越,同时成本效率显著提高。
OpenAI o1-mini比预览版OpenAI o1便宜80%,适用于需要推理但不需要广泛世界知识的应用程序。在一些对智能和推理提出要求的基准测试中,o1-mini的表现甚至优于o1-preview。
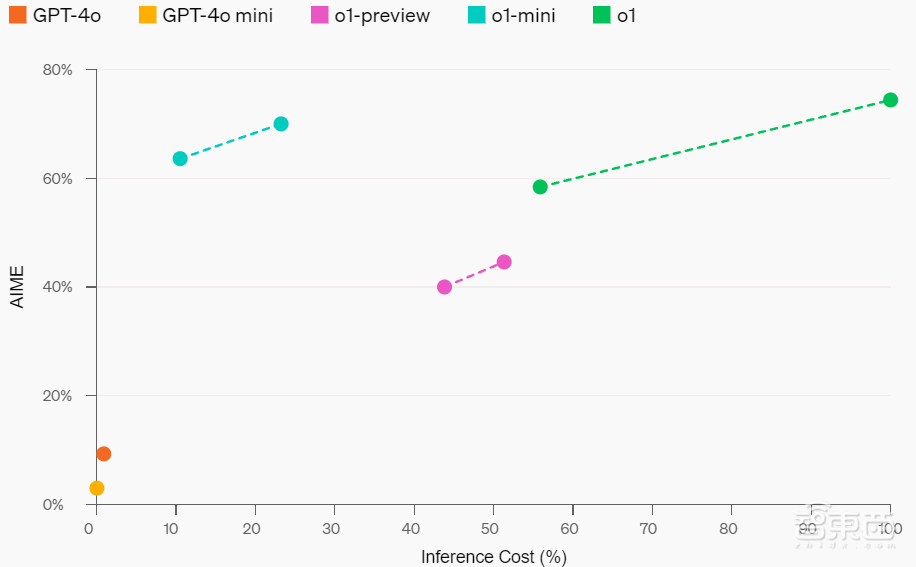
▲数学性能与推理成本曲线
在高中数学竞赛AIME中,o1-mini正确率为70%,大约相当于美国高中生前500名。同时,o1、o1-preview正确率分别为74.4%、44.6%,但o1-mini价格比它们便宜得多。
在人类偏好评估上,OpenAI通过让人类评分者在不同领域,针对对具有挑战性的开放式提示词测试o1-mini、o1-preview,并和GPT-4o进行比较,得到以下测试结果。与o1-preview类似,o1-mini在推理任务繁重的领域比GPT-4o更受欢迎,但在以语言为中心的领域则不被看好。
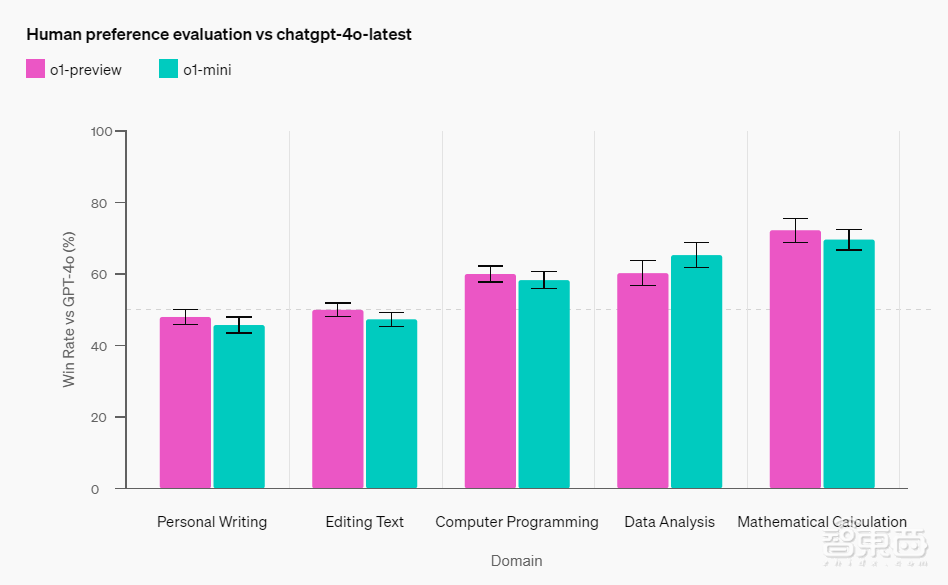
▲人类偏好评估结果
速度方面,GPT-4o、o1-mini和o1-preview回答同一个单词推理问题分别耗时3秒、9秒、32秒,但GPT-4o的回答是错误的,后两者回答正确。可以看出,o1-mini得出答案的速度比o1快了大约3~5倍。
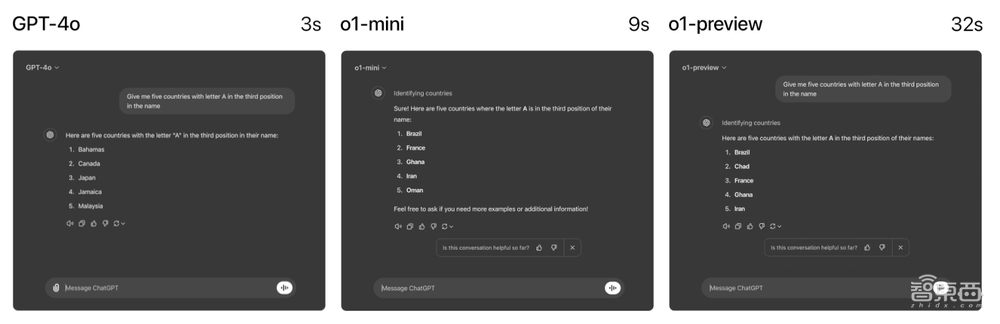
▲GPT-4o、o1-mini和o1-preview回答速度
当然,毕竟是“阉割版”,OpenAI o1-mini也一定的局限性。在日期、传记和日常琐事等非STEM主题的事实知识上,o1-mini有所局限,表现与GPT-4o mini等小型模型相当。OpenAI称将在未来版本中改进这些限制,将模型扩展到STEM之外的其他专业及模态。
三、引入推理标记,用思维链解决难题
与人类类似,o1在回答难题之前会进行长时间思考,且尝试解决问题时会使用思维链(Chain of Thought)。
通过强化学习,o1学会了改进思维链和使用策略。它能够识别和纠正错误,将棘手的步骤分解为更简单的步骤,并且在当前方法不起作用时尝试不同的方法。这一过程极大地提高了模型的推理能力。
具体来说,o1模型引入了推理标记(Reasoning Tokens)。这些推理标记被用于进行“思考”,分解对提示的词理解,并考虑多种生成响应的方法。推理标记生成后,模型会将答案生成为可见的完成标记(Completion Tokens),并从其上下文中丢弃推理标记。
以下是用户与模型之间进行多步骤对话的示例。每个步骤的输入和输出标记都会被保留,而推理标记则会被丢弃。
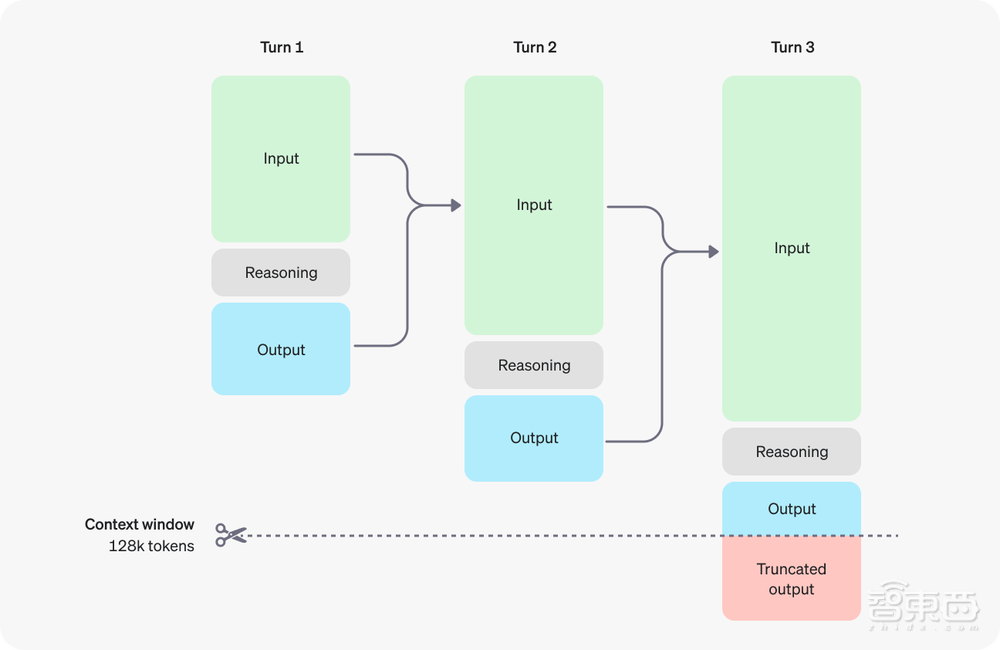
▲o1模型推理过程
值得注意的是,OpenAI在进行大规模强化学习算法训练时,发现随着强化学习、思考时间的增加,或者说随着训练时间、测试时间的增加,o1的性能会持续提高。这与大模型预训练中的Scaling Law大不相同。
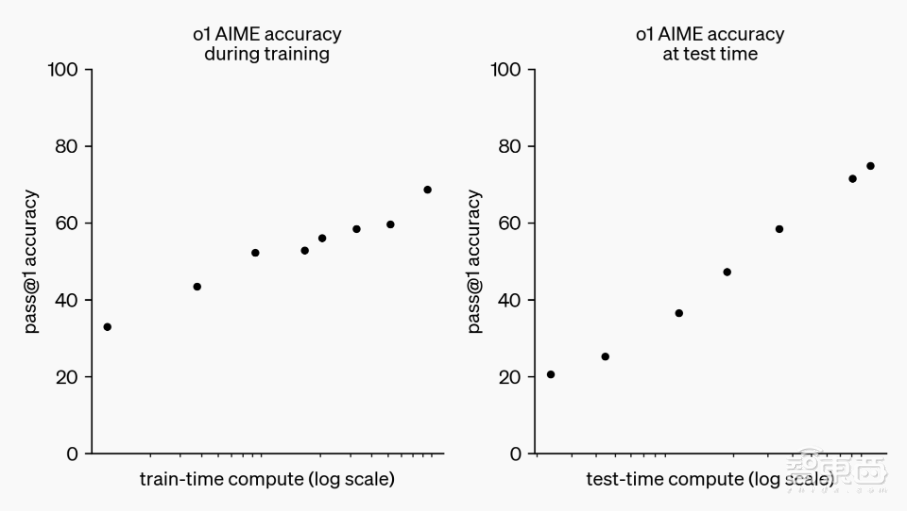
▲o1性能随着训练时间和测试时间计算而平稳提升
为了展现o1实现的飞跃,OpenAI公开了预览版o1在解决编程、数学、解码、英语等难题时产生的思维链。
例如当拿到一道解码题目,GPT-4o先是拆解出了输入、输出和示例,随后开始分析可能的解码方式。
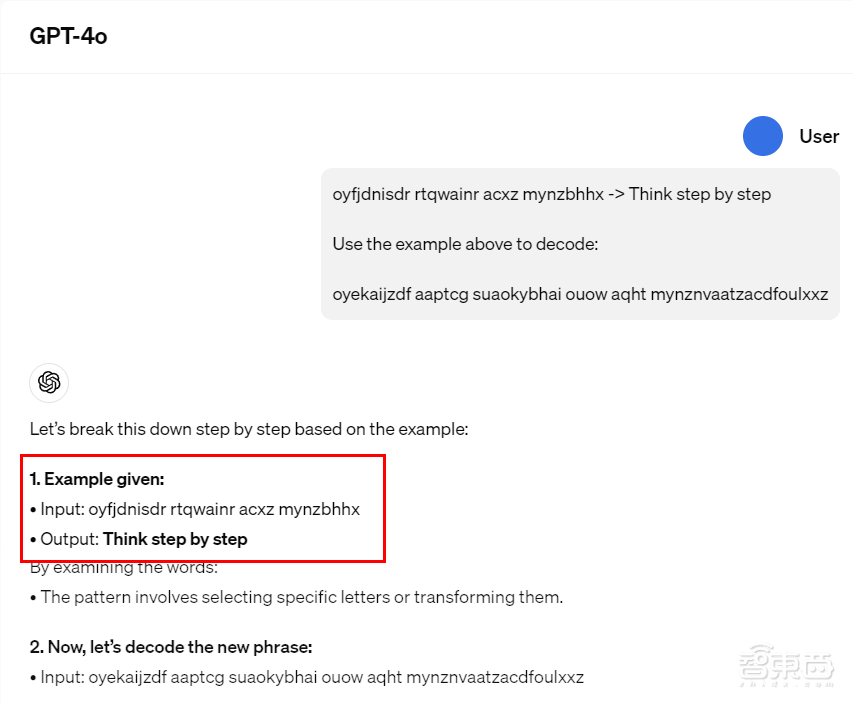
▲GPT-4o拆解输入、输出和示例
它猜测第一个短语可能遵循与示例相同的结构,意识到输入文本似乎可以根据自然分隔或模式分成组,但随后就“歇菜”了,称自己需要更多关于可能涉及的转换或字母移位的上下文。
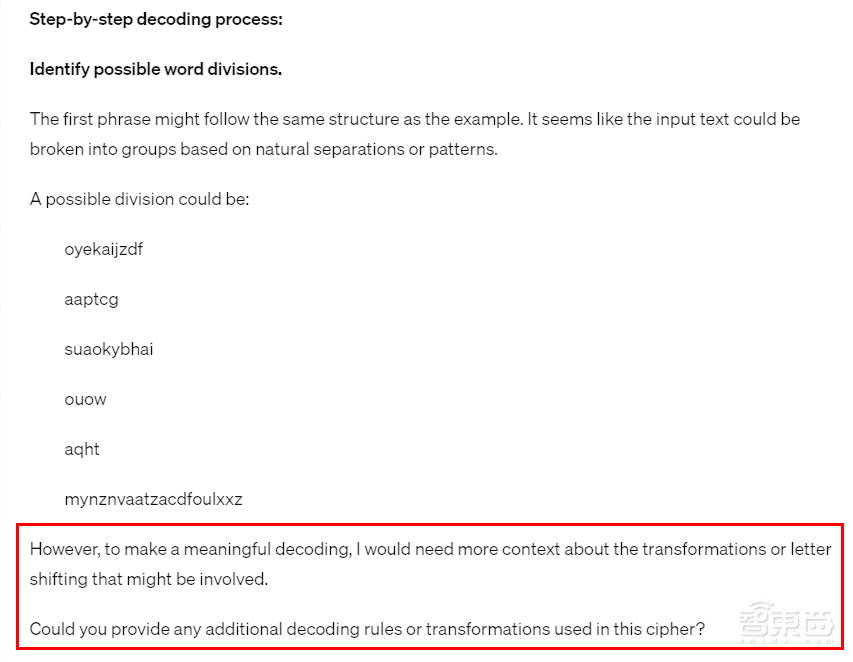
▲GPT-4o称需要更多信息
另一边,OpenAI o1-preview则通过一番思考准确给出了答案。
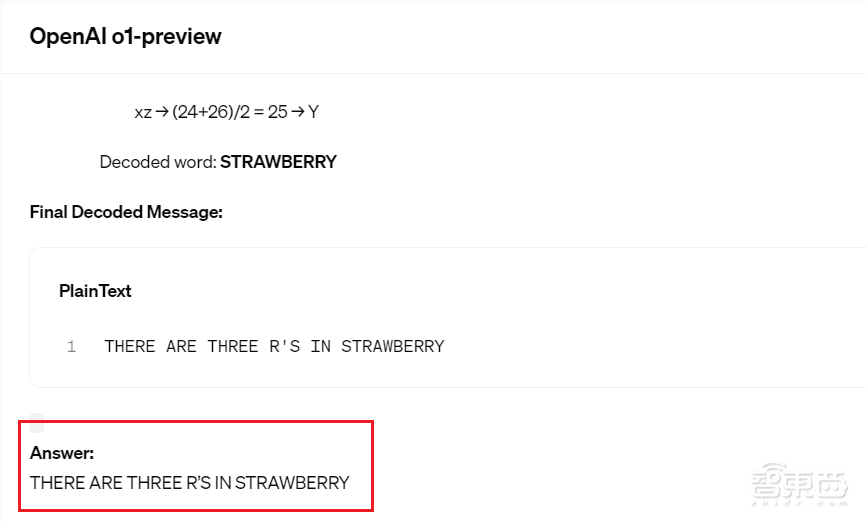
▲o1-preview正确解答解码问题
虽然最后呈现出的答案很简短,但o1的思考过程非常长,并且思考方式和用词很像人类。它会先问自己“这里发生了什么”,然后复述一遍要求,随后开始拆解任务、明确目标。
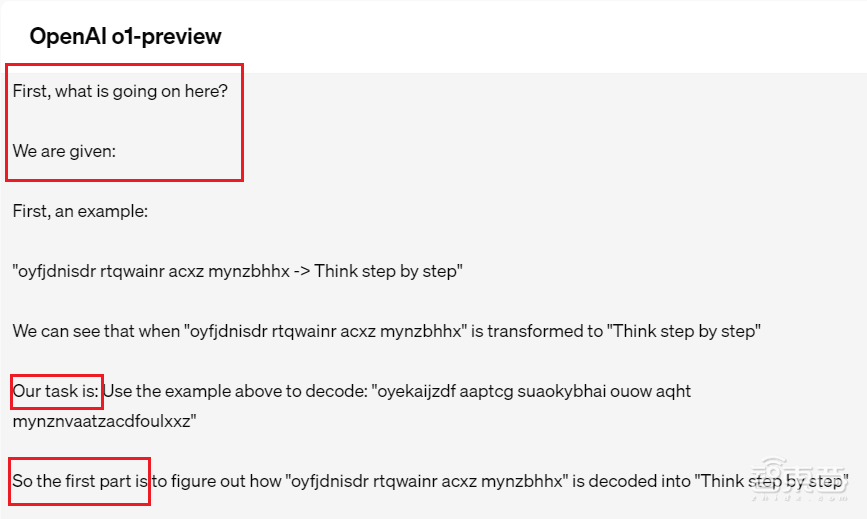
▲o1思考过程
接着,o1开始观察自己得到的信息,并逐步分析。

▲o1思考过程
在进行了一些推理后,o1开始提出不同的解决方案。在这个过程中,还会像人类一样突然说“等一下,我觉得……”,然后思维一转开始尝试新的方法。

▲o1思考过程
不仅如此,在o1的思考过程中甚至还会出现“嗯”、“有趣”等口语化、情绪化的表达。

▲o1思考过程
完整的思维链非常长,这里不再一一赘述。总得来看确实如OpenAI所说,o1能够像人类一样不断完善自己的思维过程,尝试新的策略、认识到自己的错误并解决。而且这里的“像人类”不仅局限于思考方式,还体现在语气上。
四、每周可对话30~50次,Ilya参与基础贡献
不同于以往,这次OpenAI没上期货,而是直接上线了两款模型。
即日起,ChatGPT Plus和Team用户可以在ChatGPT中访问o1模型,通过模型选择器手动选择o1-preview或o1-mini;企业和教育用户则下周起可以使用,面向免费用户未来也有获取访问权限的计划。
▲用户可在ChatGPT访问o1模型
但也许是出于安全或成本的考虑,目前这两款模型均限制了消息次数,预览版和mini版每周发送消息次数分别为30、50条。OpenAI称正在努力提高额度,并使ChatGPT能够根据给定的提示词,自动选择合适的模型。
OpenAI还上线了o1模型的API(应用程序接口)。符合等级的开发人员现在可以开始使用两种模型的API进行原型设计,速率限制为20 RPM。这些API目前不包括函数调用、流式传输、对系统消息的支持等其他功能。
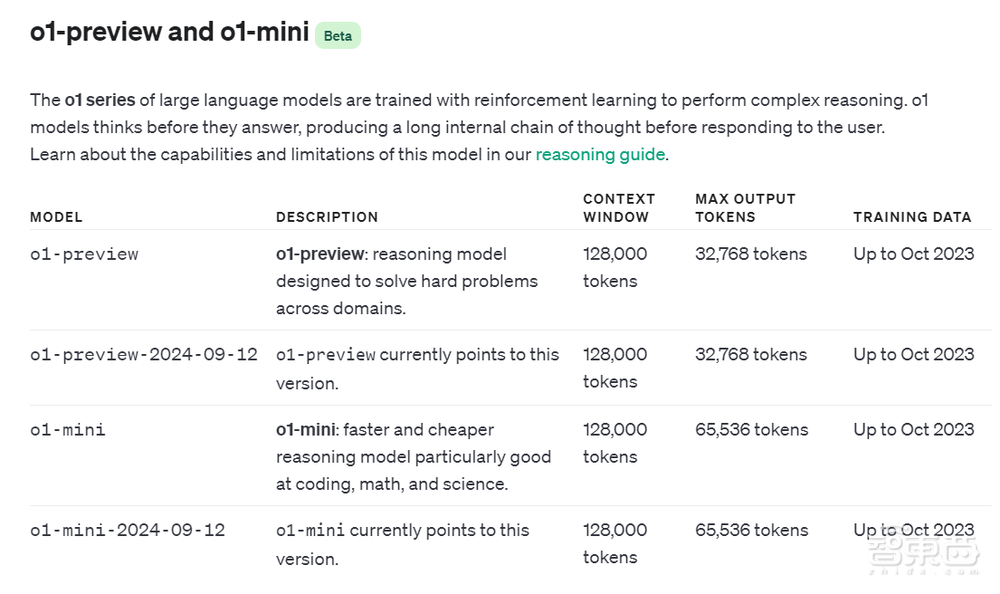
▲o1、o1 mini模型API
从API文档可见,这两款模型的上下文窗口均为128k,而mini版输出窗口更长,是o1的两倍,此外两款模型训练数据均截至2023年10月。
OpenAI还公布了o1模型背后的核心团队成员:

▲o1模型背后的核心团队成员
其中基础贡献成员有21名,包括已经离职创业的前OpenAI首席科学家Ilya Sutskever。
团队负责人有7名,分别是Jakub Pachocki、Jerry Tworek (overall)、Liam Fedus、Lukasz Kaiser、Mark Chen、Szymon Sidor、Wojciech Zaremba。项目经理是Lauren Yang和Mianna Chen。
据其团队成员介绍,推理是一种将思考时间转化为更好结果的能力,他们投入比以前更多的计算,训练模型产生连贯的思路,产生与以前截然不同的表现。
他们使用强化学习训练AI模型生成和磨练自己的思维链,甚至能比人类为它编写的思维链做得更好。这种训练AI模型产生自己的思维过程的方式,使其理解和纠正错误的能力显著提高,早期o1模型已经在数据测试中取得更高的分数。
核心贡献者和其他贡献者名单如下:

▲o1核心贡献者和其他贡献者名单
行政领导包括OpenAI的CEO Sam Altman、总裁Greg Brockman、CEO Mira Murati等8人,支持领导有8人。

▲o1行政领导、支持领导
全新o1模型可根据上下文推断并更有效地利用安全规则。OpenAI已对o1-preview进行了严格的测试及评估,确保该模型可以安全发布,不会增加现有资源可能带来的风险。
结语:OpenAI掀桌子,“草莓”重构大模型格局?
从神秘Q*模型到“草莓”模型,OpenAI的新模型终于面世。自去年11月OpenAI“政变”开始,这一模型就被曝成为导致阿尔特曼被开除的关键因素之一。当时据传Q*模型的演示在OpenAI内部流传,发展速度让一些AI安全研究人员感到震惊。
不同于GPT-4o,o1模型选择直接开启了一个新的数字命名系列,而不是GPT的延续,这表明了OpenAI对其的重视。
在如今一众大模型厂商开始卷多模态、卷应用的情况下,OpenAI发布纯文本模型o1,也许会再次将大众的目光拉向底层模型能力的提升。大模型格局是否会在o1的影响下重构,还有待进一步观察。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

