

摩尔线程开源音频理解大模型MooER:基于国产全功能GPU训练和推理




下载客户端
独家抢先看
独家抢先看
IT之家 8 月 23 日消息,摩尔线程开源了音频理解大模型 —MooER(摩耳),是业界首个基于国产全功能 GPU 进行训练和推理的大型开源语音模型。
基于摩尔线程夸娥(KUAE)智算平台,MooER 大模型用 38 小时完成了 5000 小时音频数据和伪标签的训练。
MooER 不仅支持中文和英文的语音识别,还具备中译英的语音翻译能力。在 Covost2 中译英测试集中,MooER-5K 取得了 25.2 的 BLEU 分数,接近工业级效果。
摩尔线程 AI 团队在该工作中开源了推理代码和 5000 小时数据训练的模型,并计划进一步开源训练代码和基于 8 万小时数据训练的模型。
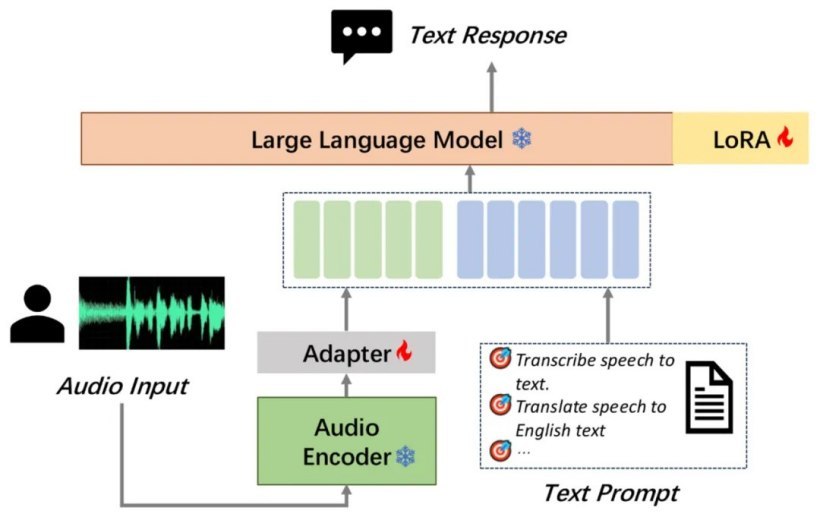
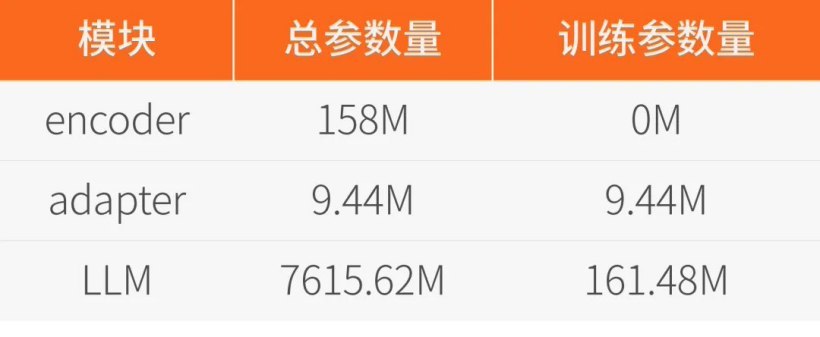
MooER 的模型结构包括 Encoder、Adapter 和 Decoder(Large Language Model,LLM)三个部分,具体的模型参数规模如下:
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

