
西湖大学团队研发Fast-DetectGPT,能区分虚假新闻和辨别AI生成文章等




独家抢先看
在近期一项研究中,西湖大学张岳教授和团队探究了机器生成文本和人类撰写文本的本质差异,同时实现了“快速、准确、鲁棒、以及较低的使用成本”,为机器生成文本检测技术的实际应用扫清了障碍。
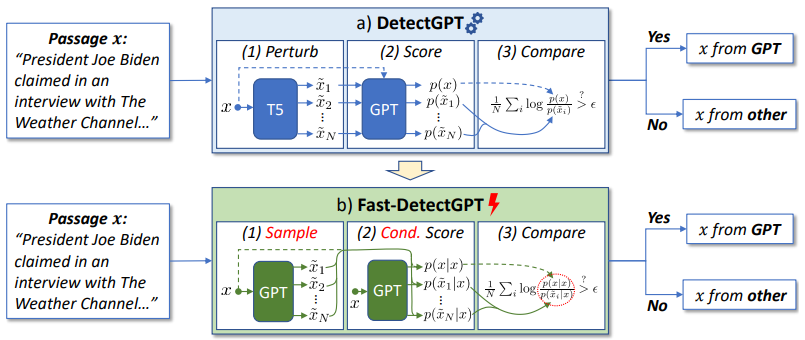
具体来说,他们提出了一种新的假设来检测机器生成文本,借此打造出一款名为 Fast-DetectGPT 的文本检测方法。
其认为,由于大语言模型采用经验风险最小化的模式,借此来学习人类集体的写作行为,具有明显的统计特性。
而人类创作受到认知和内在因果的影响,具有鲜明的个性特征。
这使得人类和机器在给定上下文的情况下,对于词汇的选择存在明显的差异,而机器和机器之间的差异则不是那么明显。
利用这种特性就能凭借一套模型和方法,检测不同源模型生成的文本内容。同时,他们使用小于 10B 参数的较小预训练语言模型,来检查 ChatGPT 和 GPT-4 等大语言模型生成的文本内容。
也就是说,在无需训练的前提之下,Fast-DetectGPT 能够直接使用开源小语言模型,来检测各种大语言模型生成的文本内容。
在 DetectGPT 基础之上,可以将检测速度提高 340 倍,将检测准确率提升 75%。
在 ChatGPT 和 GPT-4 生成文本的检测上,甚至均能超过商用系统 GPTZero 的准确率。
研究人员表示,Fast-DetectGPT 算法能够轻易用于各种预训练语言模型之中,对于不同国家的语言和内容都有很好的适用性。
未来,Fast-DetectGPT 将能用于社交平台,以便区分虚假新闻;也将能用于购物平台,以便抑制虚假产品评论;亦能用于学校或者科研机构,以便辨别机器生成文章等。
通过此,可以减轻大语言模型的广泛使用带来的潜在危害,帮助构建可信赖的人工智能系统。
“我们也在考虑,将 Fast-DetectGPT 部署到互联网服务中,提供广泛的、实时的检测服务。”研究人员表示。
(来源:ICLR 2024)
据介绍,该团队在 AI 领域深耕已有多年。而在过去两年,大语言模型的快速发展深刻影响了人们的生产和生活。
这些技术在新闻报道、故事写作和学术研究等众多领域,大大提高了人们的工作效率。
大语言模型的广泛使用,也引发了人们对安全、公平、知识产权等问题的广泛关注和讨论。
比如,在全球各大高校都引发了是否允许学生使用 ChatGPT 帮助完成课程作业的争论。
一方面,ChatGPT 的使用使学生更容易获得课程高分,但是对其他未使用这类工具的同学是不公平的。
另一方面,依赖这类工具完成课业,使学生丧失了锻炼的机会,并未达成课堂作业的目的。
总的来说,这些技术的一些不正当使用,使得虚假新闻、虚假产品评论、甚至虚假研究论文等虚假信息在网络上广泛传播,带来了一定的社会问题。
由此可见,大语言模型引发的内容安全和内容可靠性具有重要的社会价值,也是亟待研究的重要课题。
大语言模型生成的内容流畅且连贯,甚至包含很多看似合理的具体细节和引经据典的分析论证。
使得其内容在普通读者看起来特别可信,以至于不自觉地接受其内容。
然而,研究表明大语言模型比如 ChatGPT/GPT-4 生成的内容看起来一本正经,但里面可能会包含一些胡编乱造和现实情况完全不符的信息。
这类错误信息在互联网上的广泛传播,一方面会误导读者做出错误的认知和判断,另一方面也会损害读者对网络平台的信任,破坏互联网平台上内容创作者和内容消费者间的良性互动。
为了构建可信赖的人工智能系统,就需要辨别人类创作的内容和机器生成的内容。然而这些工作却无法用人工完成。
其一,人类读者很难辨别机器生成的内容。研究表明,即使是语言学专家,也难以区分机器生成的文本和人类撰写的文本。
其二,互联网上每天都会产生大量的文本内容,人工检测费时费力效率低。所以,我们需要可靠的文本检测工具来达成这个目标。
一个好的实用型文本检测工具,需要具备快速、准确、鲁棒、使用成本低等特点,只有这样才能处理互联网上大量的文本内容。
但要同时实现这几个目标,却存在一定的技术难度。
现有的机器生成文本检测器主要分为两类:有监督分类器和零样本分类器。
有监督分类器,是一类常见的文本检测工具,通过收集大量的机器生成文本和人类撰写文本,训练一个二分类检测模型。
这类方法可以使用预训练小模型进行微调,从而实现快速检测和低成本的使用。
它在训练数据集上,可以覆盖机器生成源模型、话题领域和语言,有着较高的准确率。
但是,这类方法也有非常明显的缺陷,它的鲁棒性比较差,在面对来自未学习的源模型、话题领域和语言的生成文本时,其表现就会差强人意。
零样本分类器,是另外一类文本检测工具,通过利用预训练语言模型,来检测机器生成文本。
凭借大规模的语料学习,预训练语言模型能够覆盖广泛的话题领域和语言,具备较好的泛化性和鲁棒性,并能在检测精度上能和有监督分类器相媲美。
但是,为了获得较好的检测准确率,典型的零样本分类器比如美国斯坦福大学团队的 DetectGPT,需要执行大约一百次模型调用、或调用一百次 OpenAI API,才能完成一段文本的检测,这会导致过高的使用成本和较长的计算时间。
与此同时,DetectGPT 依赖生成文本的源语言模型来进行检测,导致该方法无法用于检测由未知源模型生成的文本。
近年来,张岳实验室一直关注可信赖的自然语言处理研究。
作为自然神经语言技术的研究者,他们在创造新技术的同时,也切实感受到新技术可能带来的破坏和威胁。
而防止这些可能的破坏和威胁是他们作为科研人员的社会责任,建立可信赖的人工智能技术体系则是他们的科研理想。

(来源:ICLR 2024)
据了解,课题组一开始并没有确定是否要做机器生成文本检测。
其表示:“最开始的时候,我们是基于这样一个兴趣去探究 AI 生成式文本和人工撰写文本究竟有何不同。”
于是,他们从统计分布上、从实事性上、以及从因果关系上分析两者的差异。
首先,他们研究了 AI 生成式文本和人工撰写文本在统计分布上的差异,并主要考察两者在采样空间上的分布的特点。
为此,他们分析了大量的样本,观察它们在每个词上的分布和前后词分布的变化。
其发现,大语言模型在概率分布上,不能区分一个小概率事件和一个错误的表达。尽管这两者的概率都很小,但从人类角度来看这两者的区别十分巨大。
因为,一个是合理的内容和表达,只不过现实中较少发生。而另一个是表达错误的、不可理解的内容。
他们还发现,一些人类撰写的非常合理的内容,却落到了大语言模型的采样空间之外。
这些发现都说明大语言模型和人类有着不同的文本生成机制,产生不同的文本分布。
其次,在确定 AI 生成式文本和人工撰写文本在统计分布上存在差异后,他们觉得这种差异可以用来检测机器生成文本。
结合大语言模型的广泛社会影响,以及该团队在可信赖自然语言处理技术的研究积累,课题组正式确立了本次项目。
随后,他们考察了已有机器生成文本检测方法,包括训练的检测模型、零样本检测方法和基于水印的文本检测方法。
然后,选定零样本检测方法,并对当下零样本检测方法进行系统性调研,以及深入研究了当时最强大的零样本检测方法 DetectGPT。
该团队发现 DetectGPT 速度非常慢、使用成本很高,这些缺陷使得它很难在实际场景中使用。
结合他们对 AI 生成式文本和人工撰写文本在统计分布上差异的理解,再结合 DetectGPT 和其他改进方法已经取得的结果和分析,他们提出了 Fast-DetectGPT 这一新方法。
实验结果显示:在 DetectGPT 的基础之上,Fast-DetectGPT 不仅能将检测速度提升 340 倍,还能把检测准确率提升 75%。
进一步分析之后他们还发现:本次方法可以使用固定的小模型,来检测不同的大模型生成的文本内容,在检测准确率也能做到高于 DetectGPT。
与此同时,其还发现本次方法和常用的对数概率和熵基线有着紧密的联系,借此加深了他们对于机器生成文本检测方法之间的关系的理解。
最终,相关论文以《Fast-DetectGPT:通过条件概率曲线对机器生成文本进行高效的零点检测》(Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature)为题发在国际表征学习大会 2024(ICLR 2024,International Conference on Learning Representations 2024)。

图 | 相关论文(来源:ICLR 2024)
西湖大学博士生鲍光胜是第一作者,西湖大学的张岳教授为通讯作者[1]。

图 | 鲍光胜(来源:鲍光胜)
另据悉,机器生成文本检测对于构建可信赖的人工智能技术体系有重要意义,也是该实验室持续关注的一个领域。
基于此,他们计划从两个方面来推进后续研究:
一方面,现在的机器生成文本检测主要采用模型训练和零样本统计检验两类方法。
这两类方法对机器生成文本的检测主要依赖于机器生成文本的一些表面线索,比如用词、语法、风格等特点,对于深入的语义、知识、语用等因素并未作出考量。
随着大语言模型的发展,其模拟人类语言的能力也在不断加强,使得从语言的表面线索上越来越难以区分机器生成文本。
所以,就得进一步结合文本内容的深入的语义信息,从而做出更准确的判断。
另一方面,现在的机器生成文本检测还处于经验研究的阶段,缺乏系统性的理论指导。
因此,需要对一些基本问题加以深入探究,比如:
机器生成文本检测的极限在哪里?有哪些本质的影响因素?
这些本质因素可以被大语言模型超越,从而使得机器生成文本变得不可检测吗?
如果可以,大语言模型需要具备什么能力才能越过这个界限?
而通过对于这些问题的探索,该团队也希望让自己的研究成果可以更好地助力大语言模型的发展。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

