

商汤甩出大模型豪华全家桶!秀拳皇暴打GPT-4,首晒“文生视频”,WPS小米现场助阵




独家抢先看
作者 | ZeR0
编辑 | 漠影
智东西4月23日报道,今日,商汤科技全新升级“日日新SenseNova 5.0”大模型体系,综合能力全面对标GPT-4 Turbo。
同时,商汤在业界首次推出“云、边、端”全栈大模型产品矩阵,包括商汤端侧大模型、端云协同解决方案,以及面向金融、代码、医疗、政务等领域的边缘产品“商汤企业级大模型一体机”。
“日日新SenseNova 5.0”采用混合专家架构,基于超过10TB tokens训练、覆盖大量合成数据,推理时上下文窗口可支持200K,主要增强了知识、数学、推理、代码能力,在主流客观评测上达到或超越GPT-4 Turbo性能。

现场演示了“日日新5.0”与GPT-4多项功能对比,包括创意写作、逻辑推理、文生图、图像理解、根据图片计算食物热量等。
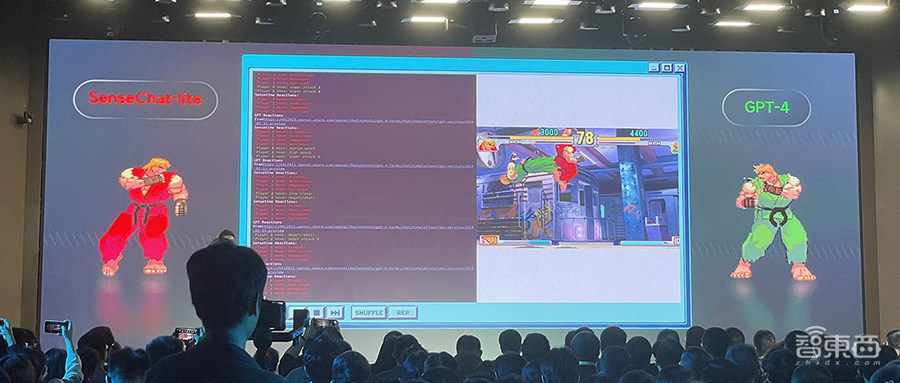
为了秀端侧大模型的肌肉,商汤科技还“玩”起拳皇。一开始绿衣玩家GPT-4略占上风,但很快就被红衣玩家SenseChat-lite各种连招打得反应不过来,最终红方取胜。

商汤董事长兼CEO徐立说,不是模型能力有多强,是在不同的适用场景下,小模型的决策速度快,当大模型还在计算,小模型已经完成了判断并出拳,不管它的拳是不是最优的,都实实在在地打到了对手的身上。
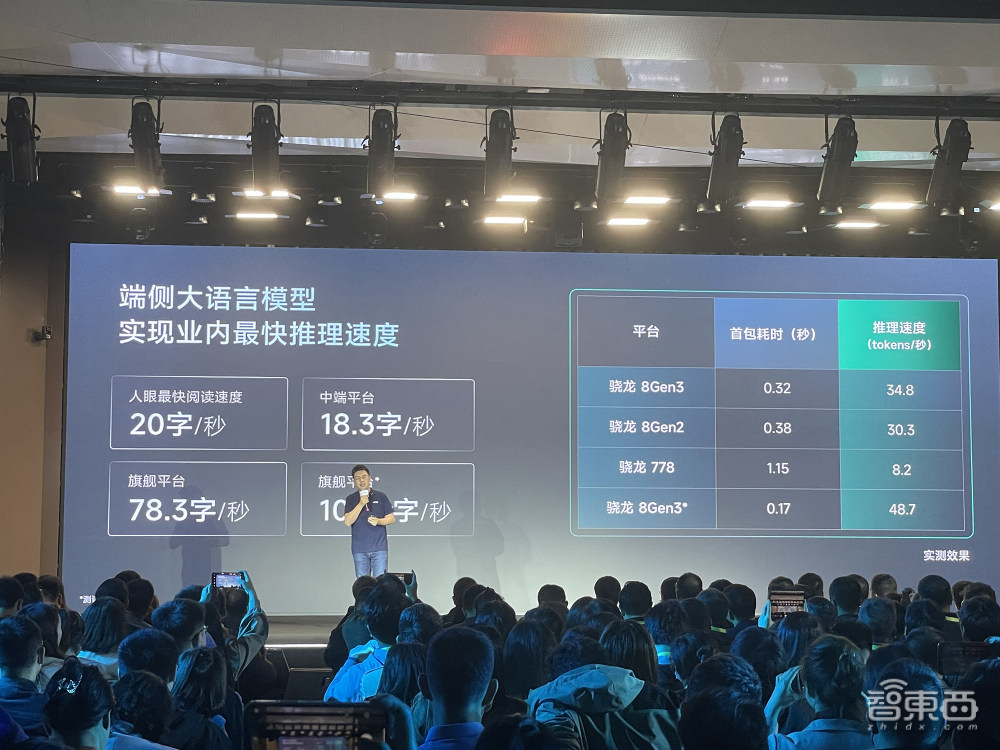
其端侧大模型实现业内最快推理速度,旗舰平台最高达109.5字/秒,而人眼最快阅读速度仅为20字/秒,现场演示的处理对话、图像处理速度快过云端。商汤还正式发布端侧业务SDK,可适配多款高通骁龙、联发科天玑芯片。

企业级大模型一体机支持千亿模型加速和知识检索硬件加速,相比行业同类产品,千亿大模型推理成本可节约80%。小浣熊·代码大模型一体机轻量版每台售价35万元起,单台支持100人团队使用,每日使用成本低至每人4.5元。

同时,商汤发布了基于昇腾原生的行业大模型,与华为共同打造面向金融、医疗、政务、代码等大模型产业生态。

在自身应用方面,商汤“日日新SenseNova 5.0”在秒画、如影、格物、琼宇、大医、小浣熊家族等产品均有重要更新。
还有One More Thing——文生视频生成平台,徐立带来了三段完全由大模型生成的视频,并着重强调对人物、动作、场景的可控性。

未来,通过输入一段文字描述即可生成一段视频,而且人物的服饰、发型、场景都能根据预先设定,保持视频内容的连贯性和一致性。
金山办公CEO章庆元、海通证券副总经理兼首席信息官毛宇星、小米集团小爱总经理王刚、阅文集团筑梦岛总经理葛文兵均来到现场,分别作为办公、金融、出行、IP角色等行业的代表进行分享。几位客户代表的发言都很有料,或连爆金句,或干货频出,对行业发展很有参考性。
一、文科数理能力均显著提升,全面对标GPT-4 Turbo
商汤董事长兼CEO徐立首先提到Scaling Law尺度定律,即随着模型参数变大、数据量变大、训练时长加长,算法性能会越来越好。
还有两条隐藏假设,一是可预测性,在小尺度上做很多实验,跨越5~7个数量级尺度依然保持性能的准确预测;二是保序性,在小尺度上验证的性能优劣,在大尺度上依然保持着优劣。
这可以指导在有限的研发资源上找到最优模型架构和数据配方,让大模型能最高效地学习。
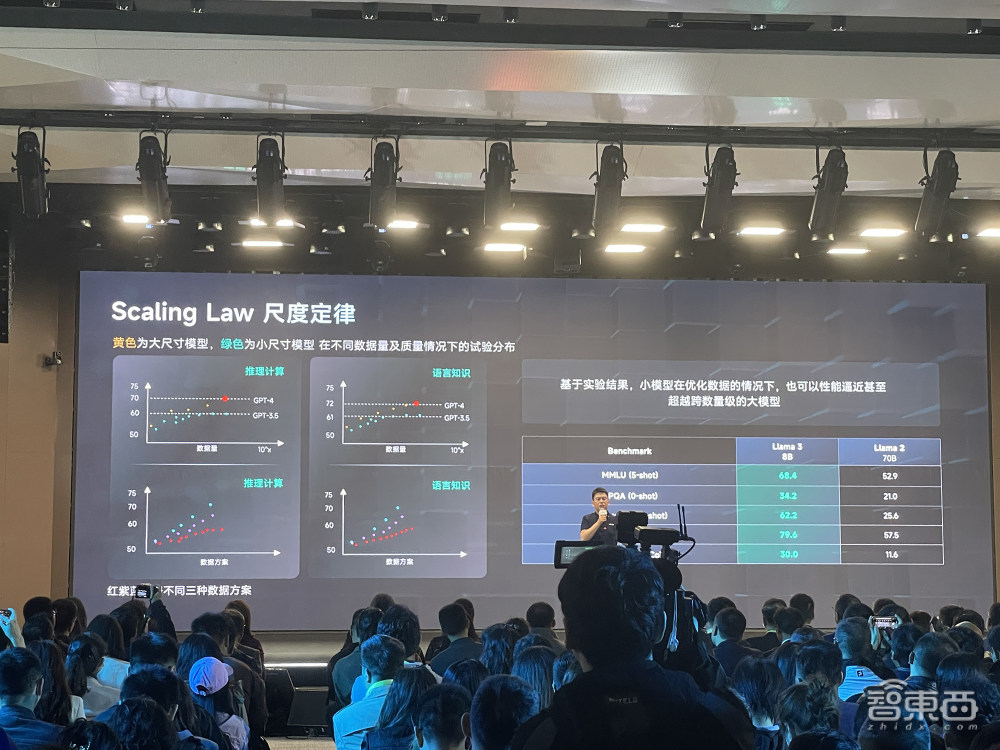
基于实验结果,小模型在优化数据的情况下,性能可逼近甚至超越跨数据级的大模型。
“商汤在尺度定律的指导下,会持续探索大模型能力的KRE三层架构(知识-推理-执行),不断突破大模型能力边界。”徐立说。

为了解决数据集质量的瓶颈,日日新5.0训练用到10T+ tokens的中英文预训练数据,进行了精细设计的清洗处理,形成高质量基础数据。
此外,合成思维链数据,是激活大模型的强理解推理能力的关键。商汤在预训练过程中大规模采用数千亿tokens量级的逻辑型合成数据。
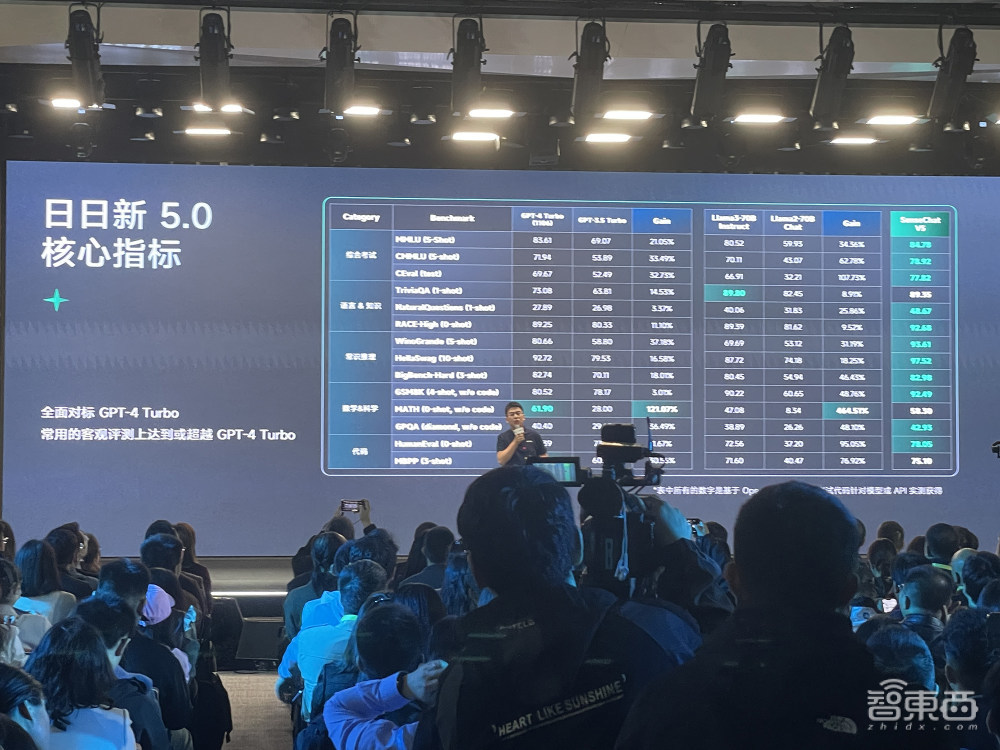
“日日新5.0”在中文理解、知识储备、数理逻辑、代码编程等方面的能力明显提升,在主流客观评测上达到或超越GPT-4 Turbo。
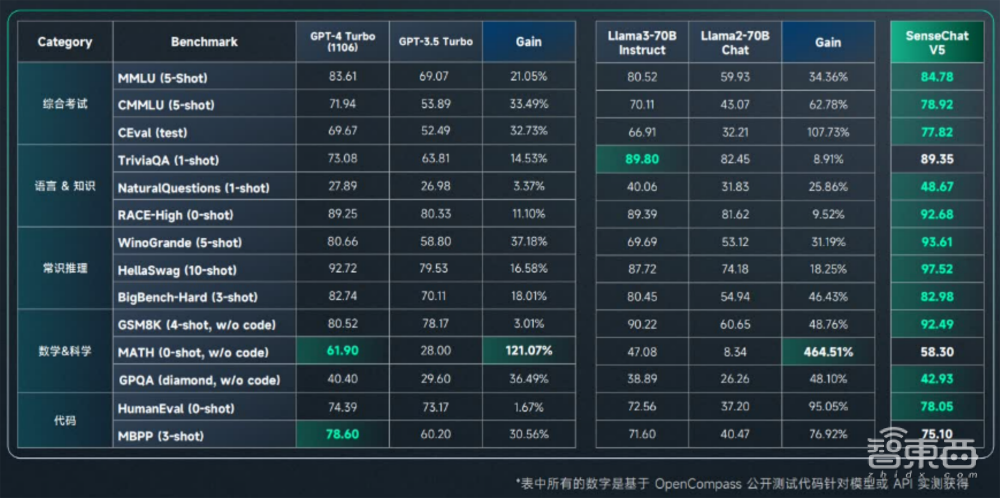
在文科能力方面,“日日新5.0”的创意写作、推理、总结能力均大幅优化,相同的中文知识注入后,可获得更好的理解总结及问答。
基于大量中文语料的构建,在开放式写作,比如让它写2022年基于《红楼梦》给匾额题名来探讨创新的高考作文,可以看到GPT-4写作风格比较生硬:“在学习上……在工作中,……”;“日日新5.0”则写得更加发散,从诗经楚辞到文化革古鼎新,再到互联网新知识的融合。

在理科能力方面,“日日新5.0”的数理、代码及推理能力达到业内领先水平。
商汤展示了一个数学题示例:妈妈给圆圆冲了一杯咖啡,圆圆喝了半杯后,加满水,她又喝了半杯后,再加满水,最后全部喝完,问圆圆总共喝掉多少咖啡和水。如果理解成总共加了两次半杯水即一杯水,那么答案是一杯咖啡一杯水。如果从每次喝掉多少水来算,计算则比较复杂。

“日日新5.0”理解完后,得出跟刚才解读一致的答案。而GPT-4把事情搞复杂了,得出的答案是喝了19/20杯咖啡和1+4/5杯水。
还有一个简单的逻辑情景题,13个小朋友玩老鹰抓小鸡,抓了5只小鸡,问还剩几只。GPT-4不理解老鹰抓小鸡游戏中有1人要当老鹰,给出的答案是8只。“日日新5.0”则给出正确答案。
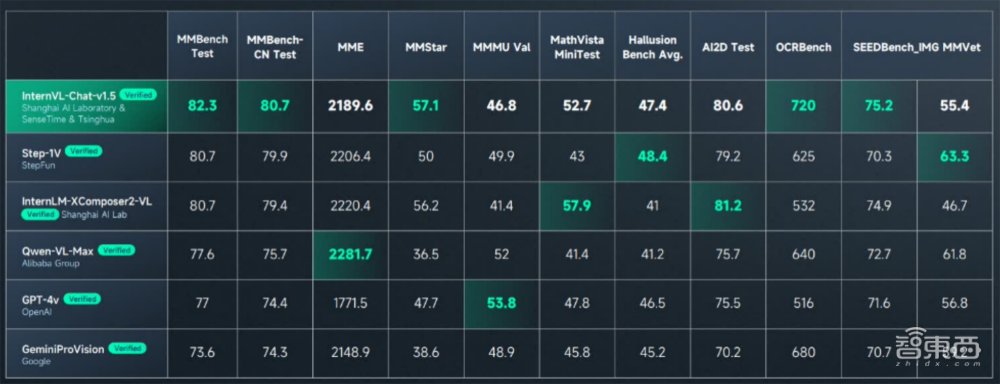
在多模态能力方面,其在多模态大模型权威综合基准测试MMBench中综合得分排名首位,在多个知名多模态榜单中取得领先成绩。
商汤将“日日新5.0”的文生图能力与几个业界最好的模型做直观对比。

徐立说,文生图的一个难点是如何将真正的理解与合成放在一起。其他主流文生图模型对于文字嵌入到图像中都有一定缺失,日日新5.0则能表现得非常好,有比较完整的指令跟随生成效果。
在应用产品层面,“日日新5.0”支持高清长图的解析和理解以及文生图交互式生成,还可以实现复杂的跨文档知识抽取及总结问答展示。
长图上会有很多信息点,但推到多模态窗口中,往往图像分辨率过高,上传不了。对此,商汤给出了非常大的分辨率接口,支持用户对长图等级性提问,包括描述图片细节、总结标题内容等。

再比如打车应用界面截图,它可以识别捕捉到其中的时间、车辆距离、文字提示、车辆信息、功能按钮、推广活动等核心信息。
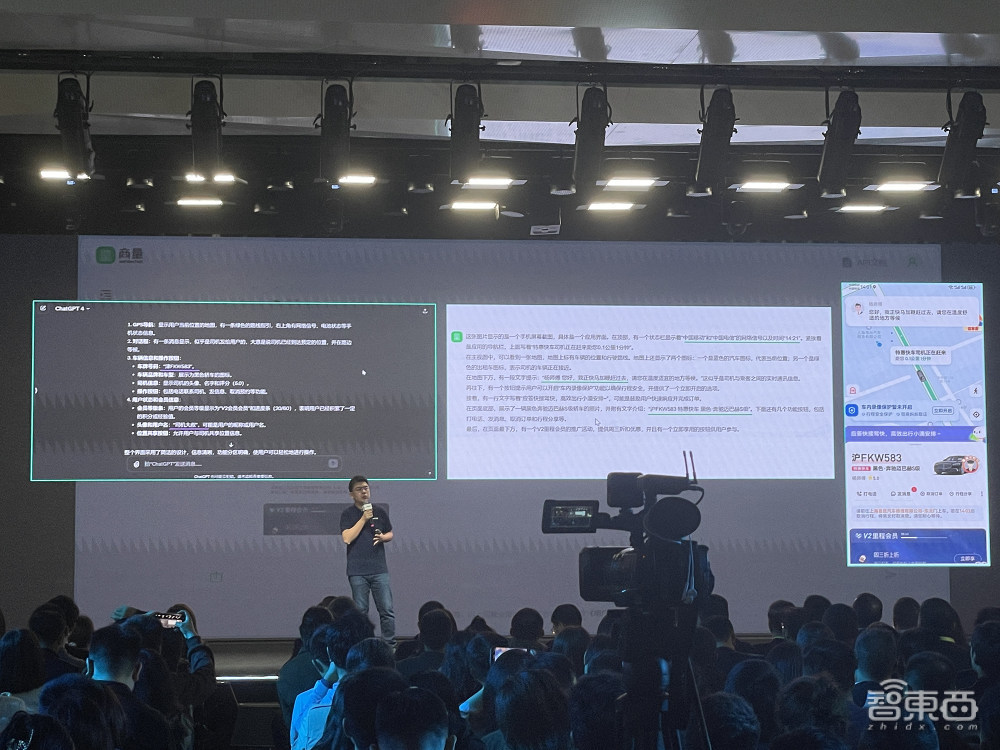
它也可以化身卡路里助手,拍一张早餐照,让它算算一共多少热量。

相比GPT-4,日日新5.0在理解中式餐饮内容中表现更好。
小浣熊家族是基于商汤大语言模型打造的AI原生生产力系列工具,覆盖软件开发、数据分析、编程教育等多个场景,旨在提升工作效率,已推出代码小浣熊、办公小浣熊等成员。输入商汤小浣熊网页截图,“日日新5.0”可以进行详细描述。

再让它根据前两个小浣熊,来生成一张新的小浣熊形象,它会先解释自己的设计思路,然后生成对应形象。而对GPT-4进行完全相同的输入,GPT-4生出的形象毫不相关,并没有将前两个小浣熊形象融入到它的设计理念中。

通过用户的自然语言输入,办公小浣熊可自动将数据转化为有意义的分析和可视化结果。比如导入数据库文件,数据库里只有英文名,而用户输入查找的是中文名,第一波输入后没查到,接着告诉办公小浣熊“肯定有的 你再找找”,它就会进行思考,再度检查和筛选,找出模糊匹配的信息。
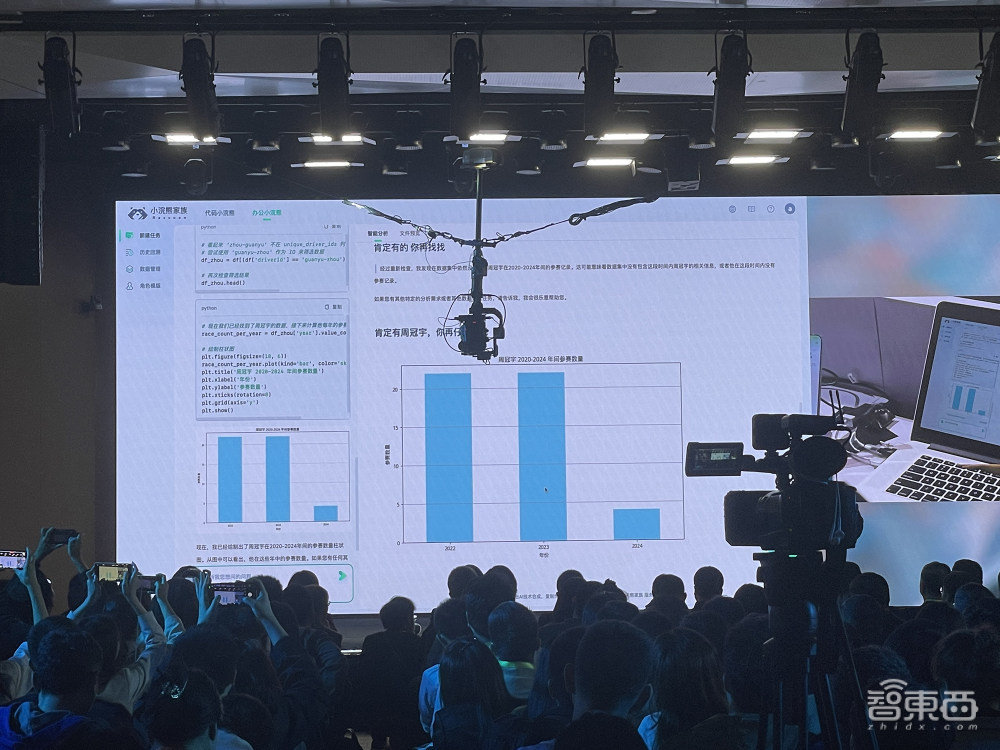
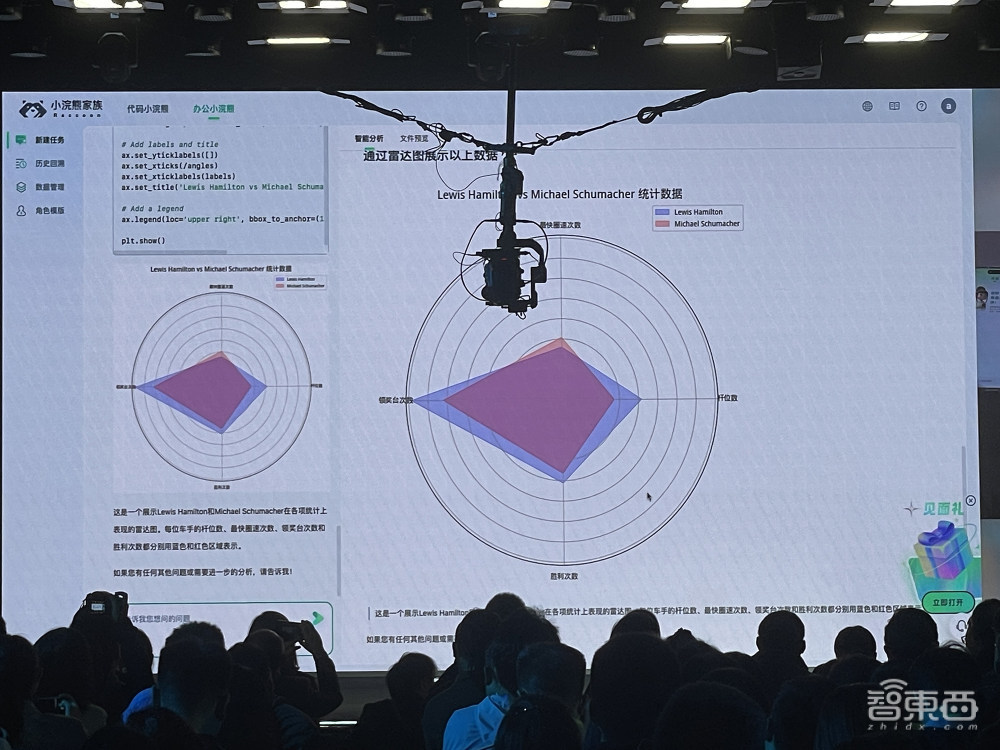
它还可以检查数据库中多个表格的交叉信息来汇总计算,并生成直观的可视化图表乃至雷达图。
二、端侧模型跨级领先,端云协同方案大降推理成本
天下武功,唯快不破。
商汤推出SenseChat-Lite版本端侧⼤模型,可落地手机、平板、VR眼镜、智能汽车等端侧。
商汤日日新·端侧大语言模型的推理速度更快,首次加载低于0.4秒,解码⼤于30tokens/秒,号称“同等尺度性能最优,跨级尺度全面领先”。

人眼最快阅读速度为20字/秒,而该模型在中端平台实现18.3字/秒的平均生成速度,旗舰平台更是达到78.3字/秒,最高能达到109.5字/秒。
商汤通过SDK形式为终端用户提供量化部署工具链,数据处理均在终端设备上完成,有效保障⽤户隐私安全。
商汤还推出端云协同解决方案,进行高性能计算,处理复杂的任务。
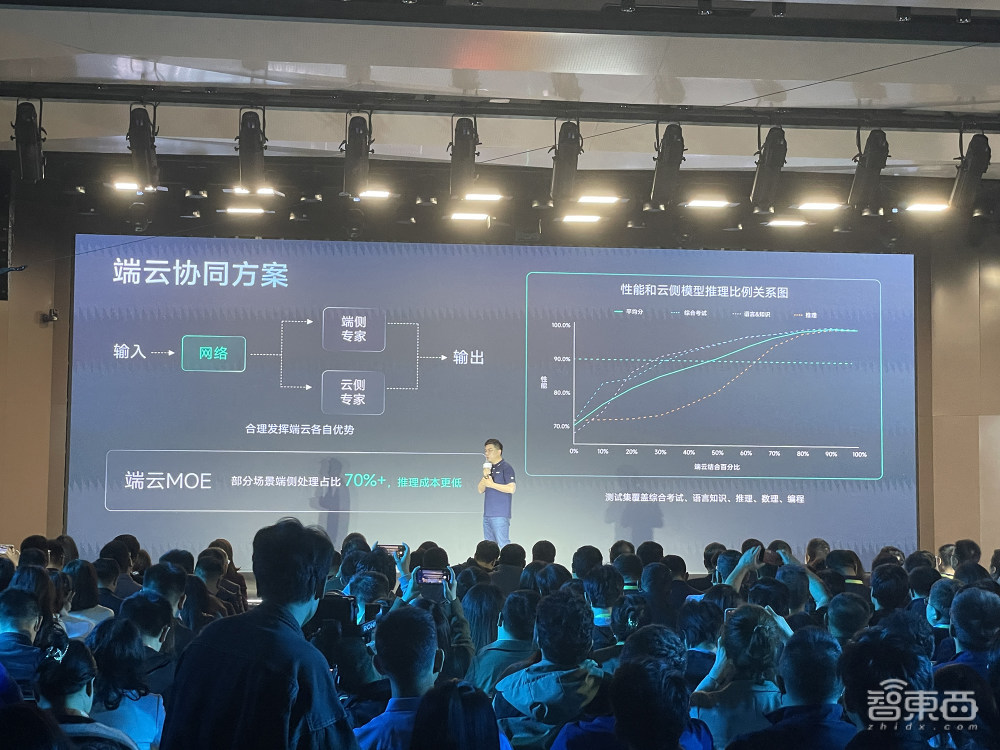
该方案支持在不同的设备和平台上运行,使得模型可以在各种终端上进行部署和应用,同时实现在离线状态下仍能保障服务和应用。
其端云协同⽅案性能指标上,在综合考试、语言、知识考试、推理等17个测试集下,平均性能接近云侧,但80%的推理将在端侧处理,因此节省了大量云侧推理成本,模型能够及时适应变化的环境和需求,保持高性能和准确性。
现场演示了端侧离线运行商量平台,比如写请假申请、将长篇大论总结成一句话。基本上眼睛还没看清,模型已经生成出答案。

其端侧扩散模型同样实现了业内最快推理速度。

1B模型支持在高通、联发科高端平台上端侧离线运行,端侧LDM-AI扩图技术在主流平台上推理速度不到1.5秒,比友商云端app快了10倍,可在数秒内生成1200万像素及以上的高清大图,并支持在端侧快速进行等比例扩图、非等比例扩图、旋转填充扩图等多种图像编辑功能。

端侧智能体也很方便,能够自动执行一连串复杂指令,比如打开邮箱-查看邮件-把邮件移动到指定文件夹-打开微信-进入指定微信群聊-在群公告中发布指定内容。

商汤宣布端侧业务SDK正式发布,适配多种主流高通骁龙、联发科天玑芯片,支持XR、PC、车载、安卓/iOS移动全平台。
三、发布企业级大模型一体机,大模型推理成本可节约80%
面向边缘侧,商汤面向金融、医疗、政务、代码四个行业推出商汤企业级大模型一体机。
一体机同时支持千亿模型加速和知识检索硬件加速,实现本地化部署,即买即用,相比行业同类产品,千亿大模型推理成本可节约80%;检索大大加速,CPU工作负载减少50%,端到端延迟减少1.5秒。

金融大模型一体机采用国产双路主控CPU及四颗智算加速卡,单机能够满足30人同时使用,支持万量级的金融文档管理和检索,在万级文档知识库规模下检索准确率超过90%,满足金融部门的精准检索要求。

医疗大模型一体机是软硬一体私有化医疗大模型解决方案,针对智能问诊、导诊、病历结构化、影像报告解读等场景,支持智能调整回复内容的语言风格、详略程度、格式要求等,一键自定义专属医疗场景,实现小成本高精度的医疗大模型部署。

政务大模型一体机是面向政务咨询场景的边缘大模型产品,采用国产双路主控CPU及四颗智算加速卡,支持万量级的政策文档管理和检索,面向有政务咨询需求的部门单位, 辅助更高效地处理与法律法规、政策标准相关的咨询和决策任务。
小浣熊·代码大模型一体机轻量版是面向软件开发的边缘大模型产品,是一套安全可靠、开箱即用、高性价比的企业软件研发软硬件一体化解决方案,能够帮助开发人员更高效地编写、理解和维护代码,提高软件开发的效率和质量。

其在HumanEval的测试通过率高达75.6%,超过GPT-4的74.4%,能够支持90多种变成语言和8K上下文,单机可满足100人团队应用需求。小浣熊·代码大模型一体机轻量版每台售价35万元起,每日使用成本低至每人4.5元。

相较于传统的云服务模式,这些一体机的所有数据处理过程均在客户的私有环境内完成,能够有效避免数据在传输过程中的泄露风险,及跨境传输等引发的合规问题。
四、四大客户晒落地成果,金融大模型、拟人大模型发布
金山办公CEO章庆元、海通证券副总经理兼首席信息官毛宇星、小米集团小爱总经理王刚、阅文集团筑梦岛总经理葛文兵均在现场分享了与商汤的合作进展,以及一些最新行业观察与见解。
金山办公CEO章庆元说,金山办公从去年下半年开始一直在跟商汤合作。大约四年前,金山办公就将AI定位为其产品核心战略之一,当时还没有大模型;金山办公一年陆续上线20多个AI功能,包括内容创作、智慧助理、知识洞察等。
两周前,金山办公发布WPS AI企业版,包括AI Hub智能基座、AI Docs智能文档库、Copilot Pro企业智慧助理。他分享说,企业关心的内容与C端应用完全不一样,所以他们做了整合。未来金山办公希望在Copilot方向有所突破。

“我始终认为,如果AI只会吟诗作画,其实AI是不可能改变世界,不可能颠覆世界。”章庆元说,AI要改变世界,真正提高生产力,不一定要多写代码,AI一定能够做一个真正的Copilot,因为它只有调取各种API,才能对企业生产力甚至对世界和社会产生巨大的影响。
金山办公去年开始与商汤合作探索Copilot,4月发布WPS AI企业版Copilot Pro企业智慧助理,就是基于商汤日日新模型。其低代码功能也接入了商汤模型,通过对话形式来生成各种自己的办公自动化应用。他谈到金山办公测试过全球的Copilot,包括GPT-4,之所以选择跟商汤合作,是因为商汤在金山办公的应用场景中准确度还是非常高的。
章庆元认为理科能力比文科能力难,因为涉及思维链推理,“文科说实话,有时候文章写出来,听君一席话,胜似一席话,总是没错的。”
海通证券是中国境内唯一一家至今仍在运营并且未更名、未被政府注资且未被收购重组过的大型证券公司,正在构建AI应用生态。海通证券副总经理兼首席信息官毛宇星分享说,海通证券与商汤科技做的最新是在生成服务上,重点分享了智能问答、智能研发、智能研报三个运营场景。
现场,商汤科技与海通证券联合发布金融行业多模态全栈式大模型,双方在智能客服、合规风控、代码辅助、办公助手等领域助推业务落地,并共研智能投顾、舆情监控等行业前沿场景,打通证券行业大模型落地的全栈式能力。
在个人出行场景,小米汽车SU7的智能车舱中应用了商汤的大模型技术,基于商汤端云大模型解决方案。小米集团小爱总经理王刚说,小米人工智能助手小爱同学已经落地到小米最新发布的汽车、手机、AIoT和机器人中,这是一个软硬件深度结合的产品,要做到全场景体验一致。小爱同学不止有语音助手,还提供小爱建议、小爱视觉、小爱翻译、小爱通话等智能服务。
小爱大模型已在多设备落地,8月份在手机上开启内测,目前有900万大模型用户。王刚说,车上大模型和手机大模型的体验设计差别很大,需要对大模型进行相应的适配调教,才能适用于汽车任务。有大模型后,月活跃用户次日留存提升了10%,中长尾Query满足率也提升至80%。
大模型技术给小爱带来了三个方面的跨越式升级:一是通用对话,二是垂直领域AI,三是NLP任务。具体而言,整个技术架构可以简化成如下图所示,基本分为4类问题,第一类偏工具类,第二类篇偏内容类,这两类相对简单,都是背后的一些执行类操作;第三类偏创作类,之前没有大模型是做不到的;第四类需要更大参数规模的大模型去回答,因为对知识的准确率要求极高。
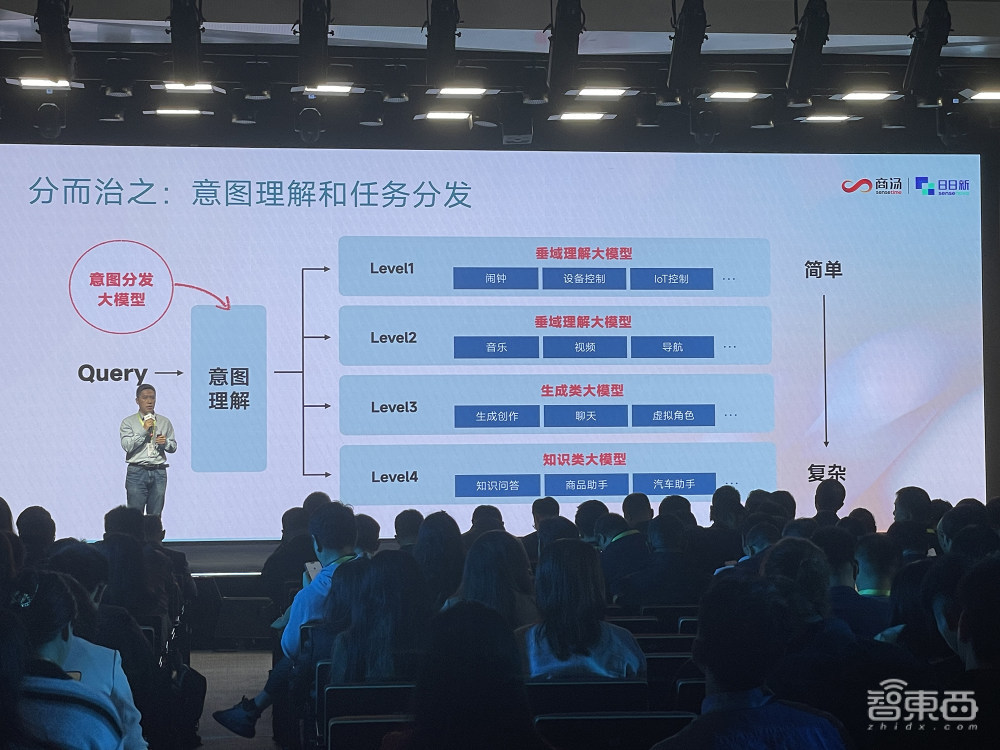 如何选择大模型?
如何选择大模型?
王刚认为,首先要建设满足业务需求的评测体系,然后选择合适的模型(大小、擅长领域、性能),并针对业务场景将模型进行优化(Prompt优化、微调、预训练)。
在大模型综合能力评测方面,他关注的重要指标是效果指标和性能指标。效果指标会拆解成不同维度,综合对比不同模型产生效果的差异,然后针对不同类别去构造一个混合系统,挑选最好的大模型。“现在我们在非常多的场景上使用了商汤的大模型。”王刚说。
在过去的合作过程中,他感受到商汤大模型有三个典型特点:

第一,模型性能好,速度快。当用户说完话,他们希望1.4秒内完成所有处理步骤,让用户听到相应的回复;但1.4秒对于大模型能力来说太苛刻了,现在要求放宽到了2秒内,王刚称能满足这一响应速度的大模型在行业内其实并不多。
第二,模型效果好,具备检索能力,可以引用高质量信息来源。
第三,模型能力强,支持知识注入、指令追随,包括能对生成内容要有一定约束和引导,支持快速对模型进行微调。在他看来,让大模型输出一个稳定的结果很不容易,大模型在实际产品场景中落地,通用基座能力要比较强大,更重要的是持续针对业务场景要求的大模型适配能力。
最后,他总结了小爱同学的未来规划,一是基于大模型进行技术升级,二是用多模态创造全新产品体验,三是和操作系统深度整合,四是端侧大模型在无网环境下提供较好的体验。
王刚还分享了一个小故事。今年1月,他所在的团队要向小米创始人、董事长、CEO雷军概括小米汽车大模型的效果,当时演示完后就被批了,团队压力很大,为达要求,希望一周完成四五个需求的优化,并达到比较好的效果。结果商汤团队在两三天内就把所有需求做完了。一周后,他们再去给雷军演示,整个效果已经非常不错。
谈到大模型推理成本,王刚说,他们最开始接入大模型时,大模性还非常贵,当时算下来一台手机一个生命周期内使用大模型的成本约20元,这是手机硬件部门接受不了的。
过去他们分析,要覆盖这部分成本,可能有3种途径,一是硬件愿意出钱,二是可商业化、互联网变现,三是用户付费。这三条路他们都尝试走了,也得益于大模型的进步,成本下降非常快,现在终端机和高端机上的硬件可以出一定费用来覆盖模型成本,大约只有原来20元的1/4~1/5。中高端手机和汽车对大模型成本已经不敏感了,手机端有机会通过接下来的内容分发、服务分发、变现去覆盖大模型成本,但如何把大模型部署到智能音箱仍难度较大。
阅文集团筑梦岛总经理葛文兵说,能够真正满足内心需求的产品存在市场空白,筑梦岛拥有广泛的角色阵容和雄厚的IP储备,随着用户对AI角色质量苛刻程度逐级提升,其中网文角色难度最大,因此筑梦岛选择与商汤合作。

商汤拟人大模型支持个性化角色创建与定制、知识库构建、长对话记忆、多人群聊等功能,可实现角色、人设及剧情推动能力,能做到人设贴合,可设置不同档位的对话亲密度,驱动各类原创及IP角色上线多个平台。
体验地址:https://character.sensetime.com/
结语:“大模型+大算力”双轮驱动,运营算力规模达12000P
基于“大模型+大算力”双轮驱动战略布局,商汤科技打造“日日新SenseNova”大模型体系和“SenseCore商汤大装置”,在推动自身大模型研发的同时,也为行业伙伴提供大模型训练、微调、部署和各类生成式AI的能力及服务。
SenseCore商汤大装置是商汤科技前瞻打造的高效率、低成本、规模化的新一代AI基础设施,目前实现了全国联网的统一调度,在上海、深圳、广州、福州、济南、重庆等地均有计算节点。
通过算法设计与算力设施联合优化,目前商汤大装置已实现万卡集群互联,运营算力有12000P;GPU超4万块;峰值算力有12000P,预计到今年年底达到18000P;国产化算力2000P,已完成58款国产芯片的适配与应用。
基于SenseCore商汤大装置,商汤新推出的“模型即服务”商业模式使客户能够轻松地在大装置微调和调用各类生成式AI能力。
日日新大模型体系在自然语言处理、视频生成和深度学习优化等多个方面取得创新,提供自然语言处理、图片生成、自动化数据标注、自定义模型训练等多种大模型及能力。
基于该大模型体系,商汤自研了中文语言大模型应用平台,以及包括AI文生图创作、2D/3D数字人生成、大场景/小物体生成等一系列生成式AI模型及应用,并面向政企客户提供多种灵活的API接口和服务。
在探索先进大模型技术的同时,商汤科技也在推动大模型与产业、应用场景更好的结合,帮助更多行业低门槛、高效落地部署AI大模型技术。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

