

清华大学文生视频专利公布




下载客户端
独家抢先看
独家抢先看
国家知识产权局网站显示,2月2日,清华大学申请的“一种定制化多主体文生视频方法、装置、设备及介质”专利公布。
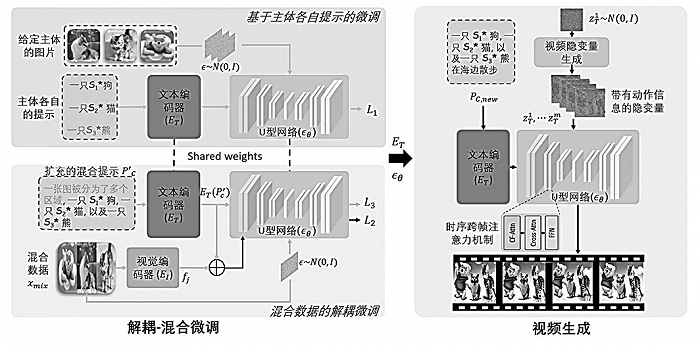
专利摘要显示,该申请提供一种定制化多主体文生视频方法、装置、设备及介质,涉及神经网络技术领域,包括:获取多个主体分别对应的主体文本表述以及主体图像;基于多个主体分别对应的主体文本表述以及主体图像,获取混合文本以及组合图像;将混合文本以及组合图像输入文生视频模型,生成第二噪声预测值,并基于第二噪声预测值与组合图像,获取第二损失和第三损失;基于第一损失、第二损失与第三损失,对文生视频模型进行优化,得到优化的文生视频模型。该申请通过多种损失对文生视频模型的参数进行优化,使优化的模型基于文本描述生成视频中的图像时,文本描述与定制化主体保持一致,且在每个主体在生成过程中的特征不会发生混淆的同时消除合成痕迹。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

