

开发者用脚投票,通义千问风靡中英文AI社区,今日再开炸裂新模型




独家抢先看
作者 | 香草
编辑 | 漠影
智东西9月25日报道,今天,阿里云举办了一场大模型开源发布会,正式发布通义千问140亿参数模型Qwen-14B及对话模型Qwen-14B-Chat,开源免费。
继开源社区口碑之作Qwen-7B之后,Qwen-14B有望成为下一个炸场式的存在。据介绍,Qwen-14B在众多同尺寸开源模型中突出重围,在MMLU、C-Eval、GSM8K、MATH、GaoKao-Bench等12个权威测评集上都取得了最优成绩,超越所有测评中的SOTA大模型。部分能力相比Llama 2的34B、70B模型也并不逊色。

▲Qwen-14B模型在12个权威榜单上超越SOTA大模型
Qwen-14B在“易用性”方面下了很大功夫。通义千问团队升级了Qwen模型对接外部系统的能力,开发者可以通过简单的操作实现复杂的插件调用,也可以基于Qwen系列基座模型快速开发Agent等AI系统,利用Qwen的理解和规划能力完成复杂的任务。同时,Qwen-7B也实现了全面升级,核心指标最高提升22.5%。

▲阿里云智能CTO周靖人在发布会上发布Qwen-14B
就在上个月,阿里云破天荒地成为国内首个步入大模型开源阵营的大厂。开源通用模型Qwen-7B、对话模型Qwen-7B-Chat等。短短一个多月,Qwen-7B等模型的下载量就突破了100万,开源社区出现了50多个相关衍生模型,且有多家月活过亿的企业向通义千问团队申请使用。浙江大学等的智海-三乐教育垂直大模型、浙江有鹿机器人的智能清洁机器人等均基于Qwen-7B打造。
开源,显然不是阿里云一时兴趣的决定。阿里云智能CTO周靖人在发布会上表明,阿里云会坚持拥抱开源开放的决心,“让算力更普惠,让AI更普及”。
一、“反向推理”没有难倒Qwen-14B,怎么做到的?
Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Tokens,使得模型具备更强大的推理、认知、规划和记忆能力,最大支持8k的上下文窗口长度。
与Qwen-7B相比,Qwen-14B模型进一步增强了Agent能力,在使用复杂工具时的可靠性有了显著提升。例如,Qwen-14B可以熟练地使用Code Interpreter(代码解释器)工具执行Python代码,进行复杂的数学计算、数据分析和数据图表绘制等工作。此外,Qwen-14B的规划和记忆能力也得到了提升,在执行多文档问答和长文写作等任务时表现更加可靠。
有趣的是,当智东西向Qwen-7B-Chat聊天机器人提出一个涉及到“反向推理”的问题时,Qwen-7B-Chat给出了准确的回答。近日,来自英国前沿AI工作组、Apollo Research、纽约大学、牛津等机构的一项研究表明,大模型在从“A是B”推理出“B是A”的问题上存在困境,在519个关于明星的事实中,预训练大模型可以在一个方向上复现,但在另一个方向上却不能。
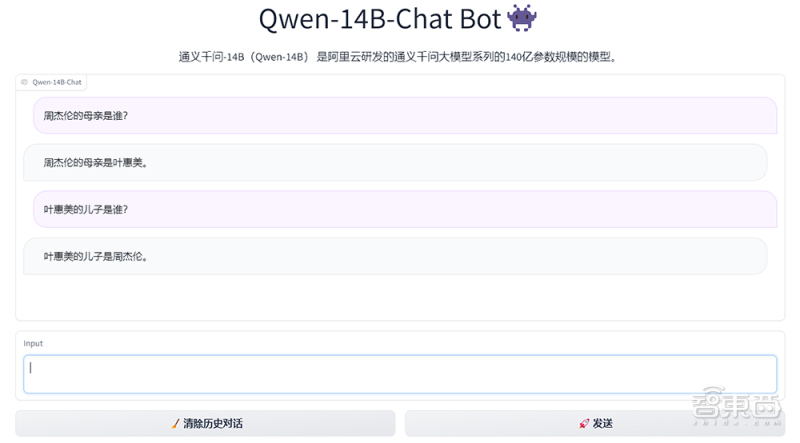
▲Qwen-7B-Chat聊天机器人对“反向推理”问题的回答
那么,Qwen-14B是如何做到的呢?
首先,在数据集构建方面,通义千问研发团队使用了3万亿Tokens的大规模预训练数据集,覆盖了各个领域和千行百业的知识,包含多个语种的语言、代码数据等。在此基础之上,研发团队做了较为精细的数据处理,包括大规模数据去重、垃圾文本过滤、以及提升高质量数据比例等。
其次,在模型结构方面,通义千问研发团队做了一系列前期实验,用来验证模型结构设计对效果的影响。整体而言,Google的PaLM、Meta的Llama模型中,大多数的技术选择都是效果较好的,包括SwiGLU的激活函数设计、ROPE的位置编码等,这些技术在Qwen的结构设计中均得到采用。
通义千问团队针对词表做了专门优化,词表大小超过15万,具有较好的编码效率。相比其他Tokenizer(分词器),能用更少的Token表示更多的信息,通过节省Token的数量来实现更低的成本。
此外,通义千问团队重点针对长序列数据建模做了优化,采用当前最有效的策略,包括但不限于Dynamic NTK、Log-N Attention Scaling、Window Attention等,并做了一些细节的调整以保证长序列数据上模型表现效果更稳定。目前,Qwen-14B模型能够适配并取得稳定表现的序列长度达到了8192。
通义千问研发团队表示,大模型训练其实没有太多复杂的技巧,更多的是通过大量尝试与迭代,找到更好的训练参数,达到训练稳定性、训练效果和训练效率的最优平衡,包括但不限于优化器的配置、模型并行的配置等。
最后,在外接工具的能力方面,研发团队主要做了两方面的优化。一是在微调样本方面,通过建立更全面的自动评估基准,主动发现了之前Qwen表现不稳定的情況,并针对性地使用Self-Instruct自我指导方法扩充了高质量的微调样本。二是提升了底座预训练模型的能力,从而增强了模型的理解和代码能力。因此,Qwen-14B的表现明显优于Qwen-7B。
目前,Qwen-14B及对话模型Qwen-14B-Chat已上线魔搭社区,供全社会免费使用。除了从魔搭社区直接下载模型,用户还可通过阿里云灵积平台(DashScope)访问调用Qwen-14B和Qwen-14B-Chat,体验阿里云提供的包括模型训练、推理、部署、精调等在内的全方位服务。
二、开发者用脚投票,通义千问跑出落地加速度
8月3日,阿里云开源通义千问70亿参数模型Qwen-7B和对话模型Qwen-7B-Chat,两款模型均开源、免费。在多个权威测评中,通义千问7B模型取得了超越国内外同等尺寸模型的效果。
海量开发者的反馈验证了Benchmark的测评结论。据介绍,Qwen-7B在魔搭以外的开源社区也广受欢迎,先后冲上Hugging Face、GitHub等社区的Trending(趋势)榜单,在英文世界大模型占据统治地位的海外开源社区也刷遍存在感。

▲Qwen-7B冲上GitHub的Trending榜单
开发者用脚投票,一个多月间累计下载了100多万次Qwen-7B等模型,开源社区先后出现50多款基于Qwen的新模型,通义千问团队也已收到多家月活超1亿的企业申请使用授权。
目前,开源社区多个知名工具和框架都集成了Qwen,如支持用大模型搭建WebUI、API以及微调的工具FastChat,量化模型框架AutoGPTQ,大模型部署和推理框架LMDeploy,大模型微调框架XTuner等等。
还有大量开发者基于Qwen开发了自己的模型和应用,如个人开发者开发的LLaMA-Efficient-Tuning、Firefly和OpenAI.mini等项目,均支持或使用了Qwen模型。

▲量化模型框架AutoGPTQ集成了通义千问Qwen模型
在开源举措加持下,通义千问大模型跑出了落地应用的加速度,接入通义千问的应用机构涵盖互联网和传统行业、学界和工业界、头部企业和初创公司等,包括阿里系的淘宝、钉钉、未来精灵(原天猫精灵),三方的浙江大学和高等教育出版社、浙江有鹿机器人科技有限公司等。

▲周靖人在发布会上介绍Qwen-7B的落地情况
阿里云在发布会上展示了多个通义千问应用案例,让“大模型落地”变得可知可感。比如,浙江大学联合高等教育出版社和阿里云,基于Qwen-7B训练了智海-三乐教育垂直大模型,已在阿里云灵积平台上线服务,开发者仅需一行代码即可使用。该模型已在全国12所高校应用,可提供智能问答、试题生成、教学评估等能力。
初创企业浙江有鹿机器人科技有限公司,则把Qwen-7B集成到机器人身上,开始面向“具身智能”的新探索。在路面清洁机器人AI130中,有鹿通过集成Qwen-7B,让机器人能使用自然语言和用户进行实时交互,理解用户提出的需求,比如“去清理一下5号楼边上的可乐瓶”,机器人能自动对用户的高层指令进行分析和拆解,通过高层的逻辑分析和任务规划,完成清洁任务。
三、“一花独放不是春”,全面拥抱开源开放
阿里云称,百模大战中,很多人看到“大战”,而阿里云看到“百模”。
阿里云副总裁、公众与客户沟通部总经理张启对记者说:“一花独放不是春,百花齐放春满园。不管是闭源大模型的还是开源大模型,自研大模型还是第三方大模型,大规模参数模型还是小规模参数模型,通用大模型还是行业、企业专属大模型,阿里云全部欢迎和支持,共同建设一个最大的大模型自由市场。我们希望所有大模型都能跑在阿里云上,跑得更快、更便宜、更安全。也因为此,阿里云率先开源7B、14B模型,并将持续开源开放,为开源社区贡献力量。”
这解释了阿里云的另类路线:造生态。回顾大模型兴起以来阿里云的种种举措,从理论到实践,阿里云都在做同一件事。
2022年,阿里云在业界首提MaaS(Model as a Service,模型即服务)理念,为新一轮AI浪潮下的大模型生态建设提供了理论依据和最佳实践。MaaS理念的内核,在于提出一种全新的、以AI模型为核心的开发范式。阿里云据此搭建了一套以AI模型为核心的云计算技术和服务架构,并将这套能力向大模型初创企业和开发者全面开放。不到一年时间,大模型行业已是“言必称MaaS”。

▲周靖人在发布会上介绍阿里云的MaaS理念
2023年7月,阿里云宣布将把促进中国大模型生态的繁荣作为首要目标,向大模型创业公司提供全方位的服务,包括最强大的智能算力和开发工具,并在资金和商业化探索方面提供充分支持。
根据本次发布会分享,提供底层算力服务,阿里云有几重独有优势:
在基础设施层,阿里云拥有国内最强的智能算力储备,其灵骏智算集群可支持最大十万卡GPU规模,承载多个万亿参数大模型同时在线训练。
在AI平台层,阿里云机器学习平台PAI提供AI开发全流程的工程能力,可将大模型训练时间缩短10倍;一站式模型服务平台灵积拥有自动化的模型上云统一工具链路,支持模型自主接入并自动获取平台的强大服务能力。灵积平台现已托管通义千问、Stable Diffusion、ChatGLM-v2、百川、姜子牙等大模型。
在开发者生态层,阿里云牵头建设了中国的AI开源第一门户——魔搭社区ModelScope。魔搭社区秉承“模型即服务”的创新理念,聚集了由30多家顶尖AI机构贡献的1200多个优质AI模型,并将AI模型变为直接可用的服务,为开发者提供一站式的模型体验、下载、推理、调优、定制等服务。

▲周靖人在发布会上介绍魔搭社区
魔搭社区的模型贡献者基本覆盖国内大模型赛道核心玩家,大模型企业不约而同将魔搭作为自研模型开源首发第一站。9月,百川智能的Baichuan 2系列模型、上海人工智能实验室的书生·浦语20B模型、智谱AI的MathGLM等模型均在魔搭开源首发。其中,书生·浦语系列模型与魔搭社区达成生态合作,表示将共同推动中国大模型生态建设。
模型供给的丰富,带来了开发者的汇聚,“找大模型上魔搭”已经成为开发者的共同心智。上线不到一年时间,社区已经聚集230万AI开发者,模型累计下载量突破8500万。
在阿里云畅想的“大模型自由市场”中,通义千问只是“百模”之一。而开源开放,正是阿里云知行合一,开展大模型生态建设的“最佳实践”。
开源生态对促进通用大模型的技术普惠与应用落地至关重要。大模型训练成本高,绝大部分中小企业和开发者难以承受。大模型开源,能够将头部企业的大模型能力以更低成本、更快速度推向中小企业和开发者,加快推进大模型生态建设,孕育大模型应用创新。
从更宏观的视角看,AI大模型的竞争不仅是公司之间、研究团队之间的竞争,更是生态与生态之间的竞争。如果说“公共云+AI”的系统能力是大模型竞争的入场券,那技术和产业生态就是全球大模型竞争的主战场。产业生态是构筑商业闭环和竞争壁垒的关键,越早将大模型推向市场,越多吸纳用户的反馈来反哺大模型,越能实现“模型越强、应用越多,应用越多、模型越强”的“飞轮效应”。
最终,受益的是每一个开发者、中小企业,以及整个大模型行业。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

