

多任务智能体的一大步:DeepMind 一次搞定 57 种 Atari 游戏的 PopArt




独家抢先看
原标题:多任务智能体的一大步:DeepMind 一次搞定 57 种 Atari 游戏的 PopArt

雷锋网 AI 科技评论按:多任务学习,也就是让单个智能体学习解决许多不同的问题,是人工智能研究中的长期目标。最近,该领域取得了许多重大进展,DQN 等智能体可以使用相同的算法玩不同的游戏,包括 Atari 游戏「Breakout」(打砖块)和「Pong」(乒乓球)游戏。这些算法以前为每项任务分别训练不同的智能体。随着人工智能研究深入到更多复杂的现实世界领域,构建单个通用智能体(与多个分别擅长不同任务的智能体相反)来学习完成多个任务将变得至关重要。然而,截至目前,这一任务依然是一个重大挑战。DeepMind 近期的一项研究就提出了自己的重大改进。雷锋网 AI 科技评论把研究介绍编译如下。
要做出能掌握多种不同任务的智能体的难点之一在于,强化学习智能体用来判断成功的奖励等级往往有所不同,导致他们将注意力集中在奖励更高的任务上。拿「Pong」(乒乓球)游戏来举例,智能体每一步有三种可能的奖励:-1(AI没接住对方发来的球,不仅没挣分,反而倒贴一分)、0(AI接住了球,进入了敌我双反循环往复的弹球过程,费了老劲却没有任何回报)、+1(AI终于扳回了一局,才能得1分,实属得之不易);但在吃豆人(Ms. Pac-Man)这个游戏里面就不同了,只要一出门,就可以吃到一连串的豆豆,因而智能体可以在单个步骤中获得数百或数千分。即使单次获得的奖励的大小可以比较,但随着智能体不断进化,奖励的频率可能会随着时间发生变化。这意味着,只要不被敌人抓到,吃豆的奖励明显比打乒乓球高得多。那么,智能体当然会沉迷吃豆(得分高的任务),全然忘记自己还肩负学会其它得分不易游戏的重任。
「PopArt」
为了不放任智能体胡来,DeepMind推出了 PopArt。这一技术可以让不同游戏的奖励尺度互相适应起来,无论每个特定游戏中可以得到的奖励有多大,智能体都会认为每个游戏具有同等的学习价值。研究人员用 PopArt 的正态化方法调整了当前最先进的强化学习智能体,使得一个 AI 可以学会多达 57 种不同的 Atari 游戏了,而且在这些游戏中的得分也超过了人类得分的中位数。
从广义上来说,深度学习依赖于神经网络权重更新,其输出不断逼近理想目标输出。神经网络用于深度强化学习中时也是如此。PopArt 的工作原理,就是估算各种目标的均值以及分散程度(比如把游戏中的得分作为目标)。然后,在更新权重之前,用这些统计数据,把更新网络权重时作为参考的目标归一化。这样一来,学习过程就会变得比较稳定,不容易因为奖励尺度之类的因素改变而发生改变。为了得到准确的估计(如预期未来分数),网络的输出可以通过反转归一化过程缩放到真实目标范围。
如果按照这样的想法直接去做的话,目标统计数据的每次更新都将改变所有未归一化的输出,包括那些已经很好的输出,这样会造成表现的下降。DeepMind 研究人员的解决方案是,一旦统计数据有更新,他们就把网络向着相反的方向更新;而这种做法是可以准确地执行的。这意味着我们既可以获得尺度准确的更新的好处,又能保持以前学习到的输出不变。正是出于这些原因,该方法被命名为 PopArt:它在运行中既能精确地保持输出,又能自适应地重新缩放目标。
PopArt 作为修剪奖励的替代方案
一般来说,研究人员会通过在强化学习算法中使用奖励修剪来克服变化奖励范围的问题。这种修剪方法把太大的和太小的,都裁剪到 [-1, 1] 的区间里,粗略地归一化期望奖励。虽然这个方法会让学习过程变得容易,但它也会让学习目标发生变化。仍然以吃豆人(Ms. Pac-Man)举例,智能体的目标就是吃豆和吃敌人,每颗豆 10 分,而每吃掉一个敌人会获得 200 到 1600 不等的分数。如果用奖励裁剪的话,吃豆和吃敌人可能就没区别了。这样训练出来的AI,很可能只吃豆,完全不去追敌人,毕竟吃豆容易。如下图所示。

当移除奖励裁剪方案,并使用 PopArt 归一化代替剪裁步骤之后,训练效果就截然不同了。智能体会去追敌人了,得的分数也高了许多。

利用 PopArt 进行多任务深度强化学习
DeepMind 将 PopArt 应用于Importance-weighted Actor-Learner Architecture (IMPALA)上,这是 DeepMind此前提出的、最常用的深度强化学习智能体。在实验中,与没有使用 PopArt 的基线智能体相比,PopArt 显著提升了智能体的性能。不论仍然有奖励修剪和还是去除了奖励修剪,PopArt 智能体游戏得分的中位数都超越了人类玩家得分的中位数。这远远高于有着奖励修剪的基线智能体,而直接去掉了奖励修剪的基线智能体完全无法达到有意义的性能,因为它无法有效地处理游戏中奖励规模的大范围变化。
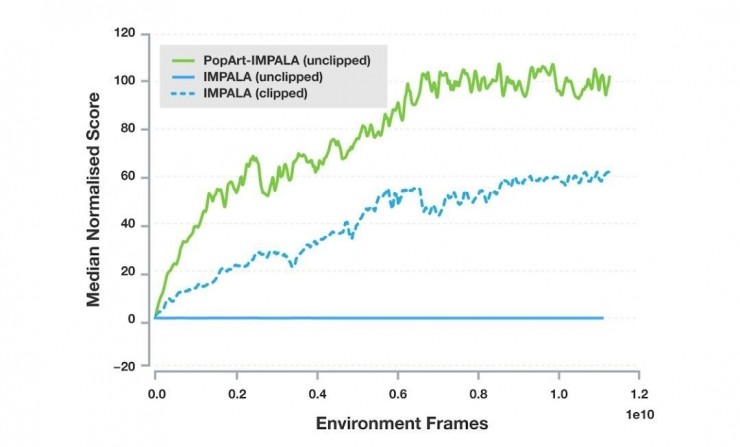
57 个 Atari 游戏上的中位数标准化性能。每一条线对应单个智能体使用同一个神经网络在所有游戏中得到的中位数性能。实线代表使用了奖励修剪的智能体。虚线代表未使用奖励修剪的智能体。
这是首次使用单个智能体在这种多任务环境中实现超越人类的表现,表明 PopArt 可以为这样的开放性研究问题提供线索,即如何在没有手动修剪或缩放奖励的情况下平衡不同的目标函数。PopArt 实现在学习的同时自动适应归一化的能力在应用 AI 到更加复杂的多模态领域时可能是很重要的,其中智能体必须学会权衡多个不同的具备变化奖励的目标函数。
via deepmind.com,雷锋网 AI 科技评论编译
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

