

Live回顾:值得你去了解的“存算一体AI芯片技术”




独家抢先看

【大咖Live】 人工智能与芯片专场第一期,我们邀请了知存科技CEO王绍迪,带来了关于“存算一体AI芯片的架构创新”的主题分享。目前,本期分享音频及全文实录已上线,「AI投研邦」会员可进「AI投研邦」页面免费查看。
本文对本次分享进行部分要点总结及PPT整理,以帮助大家提前清晰地了解本场分享重点。
分享提纲:
AI运算和其瓶颈;
AI存算一体化;
存算一体化的芯片架构介绍;
存算一体化芯片的发展和挑战;
知存科技简介。
以下为知存科技CEO王绍迪的部分直播分享实录,【AI投研邦】在不改变原意的基础上做了整理和精编。完整分享内容请关注【AI投研邦】会员内容。
大家晚上好,我是知存科技CEO王绍迪,今天我来讲一下《存算一体AI芯片的架构创新》。非常感谢大家能够来雷锋网来参加我的直播课程活动,谢谢大家!
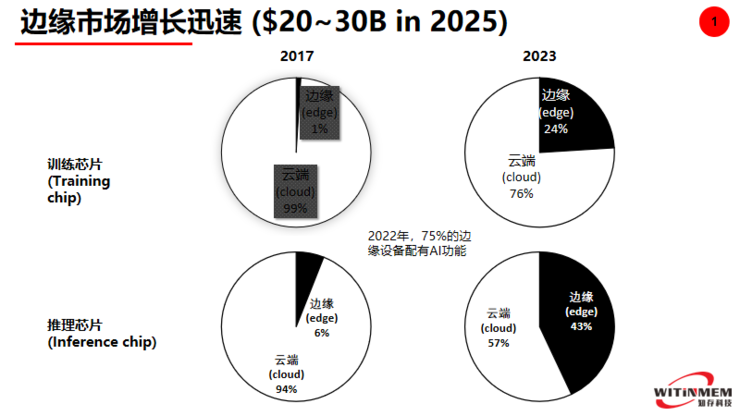
人工智能芯片是分两个市场,一个是边缘市场,一个是云端市场,云端芯片主要针对是服务器类的人工智能芯片,一般来说它的要求是算力大,然后对成本和功耗是不太在乎的。另外一部分市场就是边缘市场。比如说像我们手机、可穿戴智能家居,这些市场中用的芯片都是边缘人工智能计算的芯片,这类的边缘芯片它们有多种要求,一个是首先要求芯片的成本必须要足够低,在边缘这个场景下,要求功耗要低,另外还是要满足人工智能运算所需求的算例。
训练芯片一般都是在云端芯片,如果我们看2017年训练芯片的市场几乎都是在云端,而在2023年预计有一部分的端侧会有一些训练的芯片的市场,我认为在端测或者边缘侧,它并不是真正意义训练,应该只是做一些增强性的训练应用,而我们看边缘芯片在2017年也是几乎大部分都是云端市场,但是到了2023年在边缘侧芯片的推理侧增加的市场是非常大,接近一半了,而且预计在2025年边缘侧的芯片会超过云端的芯片。在推理市场中,预计在2025年边缘侧的人工智能芯片的份额将达到200亿到300亿美元,这是一个非常大的市场。其实在半导体集成电路市场中,这也是一个非常大的一个市场。


接下来讲一下人工智能运算分类,一个是训练的运算,一个是推理的运算,从功能上来看,训练的运算就是我们给大量的数据,这个数据都已经标记好了,比如说我标记这张图他就是一个狗,然后我们经过我们让我们神经网络进行正向的一个推理运算,然后看神经网络的输出结果跟我们标记的数据是不是一致,如果不一致,它还会将进行神经网络的反向运算来去修复神经网络中的权重,使得推理运算的结果跟我们标记的一致。比如说训练的运算,它其实包含两部分,一部分是正向运算,一步是反向运算,它所包含的计算量是非常大的。
而这种非常大计算量的训练运算,它就需要芯片首先有很大的算利,它的功耗包括它的体积都很难被控制得住,因此大部分的训练的芯片都是应用在云端市场。而推理运算就是完成训练工作之后,我们已经有一个训练好的一个神经网络之后,我们就可以用神经网络去进行推理运算,我们可以用它去判断我们输入的一张图片是不是我们是到底是什么东西,比如说我们给一个狗的图片,我们经过训练的过的神经网络推理运算神经网络就可以去判断这个到底是不是一条狗。
推理运算相比于训练运算,它所做的计算量是相对少很多的,因为他只做正向的运算,也不需要去反向修复神经网络的权重,因此推理运算有很多的可以放在边缘侧,用一些小型的低成本的低功耗的芯片去完成。这样的话针对整个云端一体的这样的一个市场中,这种边缘推理的这种一个做法会降低整体成本,同时提升效率。我们就以安防的应用来看边缘计算和云端计算在不同场景下对功耗和算力的需求。安防场景下首先最最前边最右边就是一个摄像头,里边一般会有一个边缘的人工智能推理芯片,功耗一般会要求是在五瓦以下,算力是在1到20Tops之内。
边缘侧的芯片,它需要做的一些事情就是去提取一些他感兴趣的行为,做一些简单的人脸检测,然后或包括做一些行为识别、车辆检测,这些运算一般不会太复杂,所以它的算力一般也控制在一个15Tops和20Tops以内。而且在摄像头里这种边缘侧的人工智能芯片,他所接受的信息,就只有大陆的。这一个摄像头它输入过来的一路信息,对它的要求就是首先功耗低,摄像头里不能放很大的功耗,同时它算力要满足运算的需求,以及满足实时性,我要他要做到实时的检测,去抓拍一些他感兴趣的信息。
而从摄像头提出来有效信息或者感兴趣信息之后,他会送到更高一级有更大算力的这样的一个机器上。一般像现在的情况下,有时候会加一个叫边缘服务器,它会收集摄像头过来的一些信息,边缘服务器中会有人工智能的加速卡,一般它的功耗要小于200瓦,然后他做也是做人工智能的一些检测运算,它的算力一般最大有可能会达到200Tops,常见的是100tops以内,这样的边缘服务器的一个应用。
从边缘服务器采集到的敏感信息,有的时候会送到云端上去做,云端上一般会做一些很复杂的一个运算的,包括对一些非常敏感的信息做一些检测比对,然后在云端上面对芯片的要求他算力要大,然后它相当于另外这个单位算力的成本要低,它的功耗要低,因为我们知道在云端这个数据中心中,一半的钱其实是花在降温上面,实际上如果芯片的功耗非常大的话,其实需要给它降温冷却的成本是非常高的。

接下来讲讲人工智能的运算和它的一个瓶颈。我们看深度学习是现在人工智能中最流行的一种算法,也是目前商业化落地非常多的一种算法,就是深度学习。深度学习中其中的一种网络神经网络就叫全连接的神经网络,或者是有一些神经网络中它有一些全连接层,它实际上这种结构是比较简单,比如说我红框画出这个范围内,全连接层比如说我左边这边有M个节点右面N个节点,我左边这一列的节点和右边这一列节点,任意两个节点之间都有这个连线,所以总共有M乘N的连线。
然后他做的运算实际上也是相当于做M乘N的这样一个矩阵,M乘1这样一个向量的矩阵乘法运算。M乘N的矩阵里面有M乘N的权重,比如说M是1000,N是1000的话,这里边就有100万个这样的权重,这100万个权重就是神经网络,我们训练得到的结果它是一个固定的值,就在我们完成训练之后,这个权重都是已知的。然后输入,X就是M乘一的这样一个向量,它里边这个值是一些待处理数据,一般是比如说我们输入的一些语音图像信息,或者经过神经网络一层输出之后的这样的一些临时数据,这个是一个变量。比如说是经过神经网络训练之后,我们在做推理运算的时候,M乘N矩阵里的权重都是已知的,然后我们后边这个向量X个向量是一个变量,就是相当于用一个已知的数去乘一个变量的数。
在之后我们用一个M乘N的矩阵乘一个M乘1的向量,得到的就是一个N乘1的这样的一个向量,就是这一层神经网络的输出结果,这层神经网络输出结果他会继续放到下一层,继续做下一层的一个神经网络的一个运算。所以简单来看神经网络对于全连接层的运算就是一个矩阵乘法运算,矩阵就是有非常多神经网络权重,需要存储器去存储下来,同时它输出运算的结果一般不大,这是一个向量,比如说我们每层一千个节点,它就是1000×1这样一个数,它权重的需要的数量是非常大的,或者运算量也很大,比如说我M和N都是一千的话,我们矩阵有100万个权重,它需要完成100万个乘法和100万个加法才能去把一层的运算完成。

除去全连接神经网络,神经深度学习中最流行的还有卷积神经网络,这一页的PPT实际上它本是一个动画效果,画了一个如何进行三维卷积的这样的一个运算。我们这里一个比较简单的一个输入数据,比如说我们正常输入一个图像数据,红黄蓝三原色就是RGB值。然后卷积我们这里假如有一个4×3×3这样的一个卷积和,这就是一个三维的一个卷积和里边总共有4×3×36个这样的一个权重值,他就会在我们红黄蓝的三成中,在平面上去做平移,然后每当它移动到一个位置,它跟4×3×3卷积和所重合的这些点就是做乘加法运算,它会输出一个值,然后卷积和就是会在整个的这样一个区域进行扫描,然后他们每扫描一个点,他做乘加法运算之后就会输出一个值,扫描完之后就会输出一层的一个图像。然后一般不会只有一个卷积和,一般的话我们会有32个64个,然后128、256,甚至有时候达到1024个,就是每个卷积和它会输出一层的一个图像,假如我们这个图像的像素是360×200,它输出的就是一个300×200这样一层数据针对每一个卷结合,如果我们有1024个卷积格,就要输出1024个这么多的一个数据。因此这个数据量其实是一个非常庞大的一个数。
同时我们比如说1024个卷积和,里边所包含的和里边这个值,其实他也是神经网络权重,这个值也是一个不小的值,这些都会占用非常多的一个存储空间。这一页就画了这个当前的一些主流的神经网络中它的所需要的一个存储权重的一个数量,一般权重的数量会从1兆到200兆占用这么大的一个空间,这是针对一个计算,尤其是段元电测计算,这是一个非常大的一个数了。同时除了权重的存储需要很大的空间,我们在做卷积运算的时候,每层的一个输出它是一个临时数据,这个临时数据所需要占用的空间更大,有的时候会需会达到甚至上G这么多的一个临时数据,也都需要存储器去把它存储下来,很多时候芯片片上是很难把这些数据存储起来,就需要芯片片外去放内存dram去把这些临时数据给缓存下来。
而从刚才我们卷积运算和全联接运算,其实可以看到这两种运算都涉及到非常大的一个存储空间的使用,像全联接的运算中神经网络权重值非常多,我们每读一个权重值过来就只做了一次乘加法运算,但是读一个权重值所消耗的资源是非常多的,像卷积神经网络,他每完成一层运算,它所需要缓存的临时数据是非常大的,同时大家做下调预算,还需要把这些缓存的数据在一个个读出来,再去做下一层的运算,这个也需要做非常多的存储调用。 这其实是涉及到人工智能运算中最大的一个瓶颈,就是存储和运算之间的瓶颈。



、

部分雷锋网「AI投研邦」会员问答:
Q: 知存科技的存算一体技术目前是否取得了业内普遍认可?存算一体技术非常复杂,如何保证产品的良率?
A: 首先知存科技得存算一体技术目前并没有得到业内的普遍认可,其他所有的存算一体公司到目前没有得到业内的普遍认可,因为目前来看存算一体芯片还没有进行大规模的量产,但是对于存算一体技术方向以及技术实施方案,目前业内包括大部分的半导体公司以及AI公司都已经认可这种技术方向了。
包括像美国的英特尔、arm、软银、微软、亚马逊、博世、摩托罗拉等都参与到存算一体技术方向的投资。存算一体技术确实是非常复杂的,这也是为什么大部分半导体公司AI公司都选择去投资创业公司去完成这件事情,而不是自己从头去开发,包括我们公司在存算一体技术上的积累已经也是超过六年才完成,流片已经超过十次,技术本身非常复杂,目前来看良率其实并不是一个问题,因为它本身是一个成熟的工艺,在工艺方面并没有做调整,所以良率都是可以保证的。
但在芯片不断的流片设计当中会发现很多新的问题需要去解决,包括一些新的技术优化方式去提高运算效率,在发现这些新的点之后,我们会去改变,优化设计,尝试提出新的架构,然后去不断的优化芯片,去把芯片从工作到量产当中这样去不断的推进。
Q2: 如果做dram的AI,需要对颗粒做什么改造,或是对控制器做什么改造?
A:DRAM做AI我们感觉挑战难度相对来说是较大一些,DRAM有它的优势,就是数据量存储比较多,但劣势是因为他用电容存储数据,而且这个电容本身特点一个是存储的电荷逐渐的减少,它需要经常刷新,然后另外读出来的数,需要把它区分成一和零,再放到运算单元做相关的运算,所以它首先很难去把存储和计算结合起来。如果在控制器层角度上去做DRAM的AI运算,大部分控制器也是在DRAM的外边,所以数据搬运也没有解决,所以他提升的效率有限。
另外DRAM它如果是做在片内加上乘加法运算单元,再做AI的运算中应该也会有一些效率提升,但是它其实面临的问题,需要一个比较好的契机,因为在芯片DRAM内部去加运算单元,首先他会把金属层处提高,把整个的工艺改变,导致芯片的成本提高,另外需要去仔细评估一下这样的运算方式能够提高多少倍效率,同时还要再找到一家比较好的一个DRAM厂商去合作,好的DRAM厂商在全球也是少见的。
但是DRAM如果想做比较好的存算一体,其实从单元角度上来说,它可以增大存储单元,把电容增大,使里边电量可以保持较长的时间,同时可以尝试让电容保持不同level不同级的电压,做到一个单元存储多个电极,然后再去做一些其它类型的运算,不过这个是非常规的一个做法需要做的一个挑战,也是一个比较大的挑战,这是我自己随便想想的一种一个解决方法。
完整内容和PPT查看可进入雷锋网「AI投研邦」查看
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

