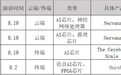

18位巨头火拼芯片黑科技!阿里华为炫技Hot Chips顶会




独家抢先看
芯潮(公众号:sxaiguan)
文 | 韦世玮
芯潮8月22日消息。美国当地时间8月20日,旧金山举行的芯片行业顶级学术会议Hot Chips落下帷幕,英特尔、谷歌、英伟达、阿里巴巴和华为等各大高科技公司也在这场会议上大秀了一把肌肉。
在这场为期三天的学术研讨会上,学界和业界的代表人物详解了他们目前在芯片领域较为前沿与核心的相关技术,也发布了一些重量级的芯片产品,如英特尔的首款云端AI推理芯片、美国创企Cerebras发布的全球有史以来最大计算机芯片。
一方面,从各大公司前沿技术的展示和发展规划中不难看出,AI芯片已然成为当今芯片创新和发展的一个巨大趋势,甚至有些公司进一步将技术聚焦在AI芯片的推理或追踪方面等性能中。另一方面,大数据流的规模正愈发庞大,系统对算力的高要求也推动着云端芯片技术和架构平台的革新。
值得一提的是,我国的芯片技术实力不管是从架构还是AI芯片上看,相比以前都有了突破性的进展,并且在芯片的安全性方面也有了新的发展方向。随着2019年Hot Chips会议的结束,芯潮专门为大家梳理了各大科技公司和学界知名高校在会上所发布和分享的相关芯片产品和技术。
一、四款AI芯片发布,涉及DL和语音
今年,英特尔、Cerebras和阿里巴巴达摩院在这场会上都发布了他们最新研发的AI芯片,分别涉及深度学习和AI语音技术。

1、英特尔:Nervana NNP-T和Nervana NNP-I
最早在8月18日的会议上,英特尔发布了两款AI芯片,它们为16nm的Nervana NNP-T和10nm的Nervana NNP-I,分别用于机器学习训练和推理。
Nervana NNP-T芯片的代号为Spring Crest,是一款神经网络处理器,专为大型数据中心设计,主要运用于深度学习训练。
此外,它采用了台积电的16nm制程工艺,拥有270亿个晶体管,硅片总面积达680平方毫米。应用上,它据有高度的可编程性,并支持所有主流深度学习框架,如TensorFlow、PYTORCH 训练框架和C++深度学习软件库等。
另一方面,英特尔发布的另一款AI芯片名为Nervana NNP-I,代号Spring Hill。这是一款专为推理而设计芯片,采用英特尔10nm Ice Lake处理器架构。
据英特尔介绍,Nervana NNP-I同样支持所有的主流深度学习框架,它在ResNet50上的效率可达4.8 TOPs/W,功率范围为10W到50W之间 。

▲ 英特尔Nervana NNP-I
2、Cerebras:史上最大计算机芯片问世
美国的这家AI芯片创企在大会上无疑赚足了人们的眼球,该公司的联合创始人兼首席硬件架构师Sean Lie,向大家推出了一款有史以来最大的深度学习芯片——The Cerebras Wafer Scale Engine。
这款芯片边长约8.5英寸,46225平方毫米的面积上拥有40万个AI优化核心。同时,它还采用台积电16nm制程工艺,拥有1.2万亿个晶体管,总带宽每秒100 PB,片上内存为18 Gigabytes,内存带宽9 PByte/s。

▲WSE和GPU芯片面积的并排比较
3、阿里巴巴:发布Ouroboros语音AI芯片
在人工智能领域,阿里从2017年起就开始了新的布局,虽然近两年的时间看似不长,但在此次的会议上,阿里达摩院终于递交了一份成绩单,发布一款名为Ouroboros的语音AI芯片。
据官方表示,这款芯片是业界首款专门用于语音合成算法的AI芯片,它基于FPGA芯片结构设计,能进一步提高语音生成算法的计算效率。同时,在FPGA环境下,Ouroboros只需0.3秒即可生成语音。

▲阿里巴巴达摩院张建松正在会上发布自研语音芯片技术
二、云端和终端AI芯片架构大比拼
在先进AI芯片架构这一领域,除了老牌的高科技创企玩家在互相角逐,就连著名车企特斯拉也刷了一把存在感,而这一部分主要可从云端和终端两部分玩家来介绍。

1、云端AI芯片
云端AI芯片主要由谷歌、华为和赛灵思三家公司展示。
(1)谷歌:TPU v3
AI芯片一直是亚马逊、谷歌和微软等科技巨头眼馋的一块肥肉。会上,谷歌研究人员为大家介绍了谷歌云端的TPU v3芯片架构,以及基于TPU的大型系统。
据介绍,TPU v3包括TPU软件设计,允许客户从单个芯片扩展到大型系统,而无需更改代码。相比TPU v2,v3的功率将是v2的八倍,同时每个v3的性能将为每秒钟运算 100 多千万亿次。

▲TPUv2机架(左)和 TPUv3机架(右)
(2)华为:达芬奇架构
在人工智能领域,华为达芬奇架构是针对AI计算特征而研发的云端AI芯片架构。会上,华为Fellow、2012实验室首席科学家廖恒为大家深入解读了达芬奇架构的真正实力。
达芬奇架构是一款用于从纳米级到高性能神经网络计算的可扩展统一架构,它基于高性能3D Cube计算引擎,能加速矩阵运算,提升单位面积下的AI算力。而它16*16*16的3D Cube能够进一步提升数据利用率,大大缩短运算周期,实现更高效的AI运算。

▲3D Cube技术引擎
(3)赛灵思:Versal系列芯片
作为全球FPGA芯片巨头,赛灵思也研发了一套AI系列芯片,名为Versal。会上,赛灵思的研究人员为大家介绍了这套Versal AI芯片。
Versal是赛灵思首款ACAP架构芯片,也是业界首款自适应计算加速平台 。该系列芯片采用了台积电的7nm FinFET技术,包含6个系列的组件,分别针对云端、网络、无线通信、边缘计算和端点等不同市场的应用,均提供了可扩展性和AI推理功能。
2、终端AI芯片
这一领域的亮点,主要为特斯拉第三代车载计算机和Facebook Zion硬件系统。
(1)特斯拉:第三代车载计算机,内置两组AI芯片
作为自动驾驶汽车领域的核心玩家之一,特斯拉在大会上向大家展示了其自研的第三代车载计算机,其中内置了两组AI芯片,为消费者提供了一套计算和冗余解决方案。
芯片设计人员表示,第三代的运行速度是第二代的21倍,并且成本仅为第二代的80%,拥有32MB高速SRAM缓存。与此同时,为了提高安全性,这款车载电脑除了采用两组AI芯片外,设计人员在其芯片的供电和数据输入方面也考虑了冗余。
(2)Facebook:Zion AI硬件系统
近年来,Facebook在人工智能的技术研发和开源方面也在不断发力。会上,该公司的研究人员专门为大家介绍了一套名为Zion的AI硬件系统,它是Facebook的下一代存储统一训练平台。
Zion平台作为AI训练系统,主要分为8插槽服务器、8加速器平台和OCP加速器模块三个主要部分。同时,它采用了Facebook的OAM模块(OCP Accelerator Module),在设计上还能够处理一系列神经网络,包括CNN、LSTM和SparseNN等。

▲Zion AI硬件系统示意
三、学界与业界竞赛CPU等终端芯片
在这一领域,除了像AMD、ARM和IBM等老牌玩家展示了自己的先进芯片技术,还有清华大学和普林斯顿大学的学术界力量也参与了进来。

1、CPU
CPU方面,除了3家科技巨头向大家展示各自的技术亮点外,还有清华大学和普林斯顿大学2所世界著名学府进行了分享。
(1)AMD:Zen2 CPU
为期三天的Hot Chips顶会上,AMD率先向大家展示的是新一代Zen2 CPU。
Zen2 CPU内部分为了CPU核心与I/O核心两部分,其中CPU核心采用7nm工艺,I/O核心采用12nm工艺。
采用台积电的7nm制程工艺的CPU核心部分,不仅有着高频低耗的优势,其成本相比上一代Zen+也进一步降低。由于IPC架构的优化和7nm工艺和频率的提升,Zen2与上一代Zen+相比,前者单线程性能提升了多达21%。
(2)ARM:Neoverse N1 CPU
此外,ARM也介绍了它的Neoverse N1 CPU,以及其下一代云端到边缘的基础设施SoC。
Neoverse N1 CPU是ARM推出Neoverse N1平台的核心部分,虽然它与Cortex A76架构有些相似,但在基础设施应用方面也有些略微的差异。它采用台积电7nm工艺制造,功耗为1W~1.8W,高速缓存为64MB,芯片尺寸接近400mm²。
在数据吞吐量方面,Neoverse N1拥有两个128位加载/存储单元,能够维持一定的带宽,以提供和服务执行流水线。同时,它大容量的L1和L2具有低延迟访问性能。

▲Neoverse N1处理器的特性介绍
(3)IBM:Power 10 CPU
IBM在会上宣布,他们将在2021年推出Power CPU的全新版本——Power 10。
Power 10采用了新晶体管的新核心,能够让系统内存实现更高的传输带。它支持PCI-E 5.0总线,传输率达32GT/s,x16通道可提供单向64GB/s、双向128GB/s。
同时, Power 10还将支持DDR5内存,带宽超过435GB/s,远超DDR4的极限。
(4)清华大学:津逮服务器CPU
清华大学的魏少军教授团队在会上分享了津逮服务器CPU芯片和CPU硬件漏洞防护方案两大内容。
据介绍,津逮服务器CPU是全球首款采用第三方芯片对处理器内核硬件实施运行时安全监控的CPU芯片,采用了英特尔至强内核处理器。能够管控硬件木马、漏洞、后门,甚至是恶意利用前门的行为。
经研究人员测试,当数台津逮服务器CPU同时运行,其有效检测硬件攻击的概率为99.8%以上,性能损失为0.98%。
(5)普林斯顿大学:内存计算嵌入式CPU
在计算机存储方面,普林斯顿大学的研究人员也提供了一个新的方向,就是让内存来干CPU的活。会上,芯片设计师之一洪阳佳为大家详细介绍了内存计算嵌入式CPU技术。
研究人员采用了一项名为存算一体(PIM,Process in-memory)的技术,将芯片的计算和存储功能合二为一,其运算速率是传统芯片的百倍。
一方面,它的计算模式使其更适合应用在深度学习等新型计算模式上;另一方面,该技术一定程度上也避免了冯·诺依曼结构处理器频繁访问内存的问题,能够减少数据的传输次数,降低功耗。
2、GPU
GPU方面,主要有英伟达和AMD进行分享。
(1)英伟达:图灵GPU及RTX光追技术
英伟达的图灵架构对计算机图形学领域来说无疑是一大创新,该架构融合了光线追踪、AI、光栅化和模拟共四项技术,综合这些技术实现了实时光线追踪,为计算机显卡领域带来了颠覆性的技术突破。
另外,RTX光线追踪技术是一种先进的实时渲染算法,它利用光线扩展到整个场景中,在通过计算生成出十分逼真的3D世界。这两项技术的结合对游戏领域来说,能够更好地还原现实场景,带来了革命性的视觉体验和享受。

▲图灵架构TU102核心
(2)AMD:Navi GPU
除了Zen2 CPU,AMD还在会上深度揭秘了Navi GPU架构技术。它同样采用了7nm制程工艺,基于RDNA架构,拥有PCIe 4.0原生支持和GDDR6显存等特性。
今后,Zen2 CPU+Navi GPU的组合,也将会为游戏领域的玩家带来更多新颖的游戏体验。
3、SoC:英特尔Lakefield芯片
除了分享AI芯片外,英特尔还进一步为大家介绍了Lakefield芯片。
Lakefield芯片采用Foveros逻辑晶圆3D堆叠技术,能够以低功耗提供比以往更强大的性能,拥有比以往更小的面积,尺寸接近12*12mm。同时,它的待机功耗比以往更低,并且性能也得到了一定的提升。
英特尔表示,目前搭载Lakefield的原型机正在测试中,它的第一款商用产品将在今年年底亮相。
四、聚焦云计算和系统内存解决方案
面对数据信息越来越庞大的环境,如何针对性地解决内存容量不足、高延迟、吞吐量低等问题,也是各个企业一直在努力优化的方向。

1、存储芯片技术
在存储芯片方面,不仅有英特尔这家巨头展示其核心技术,身为创企的Upmem也分享了具有创新性的加速器技术。
(1)英特尔:傲腾技术
傲腾是英特尔专为平衡存储成本和系统性能打造的一项存储技术。傲腾的核心是英特尔3D XPoint技术,它可以通过改变线缆中的电压,来实现数据读取,而不需要通过晶体管。同时,它还拥有低延迟、高耐久性、高吞吐量等特性。
此外,傲腾技术不仅能够扩展系统内存池,同时其响应速度比高性能NAND固态盘还要快。
(2)Upmem:DRAM加速器技术
关于优化系统内存计算方面,Upmem这家创企也有自己的一套想法,并在会上为大家介绍了新一代的DRAM加速器技术。
该公司表示,他们的DRAM芯片内置了DPU(数据处理单元),每个DPU可以访问64MB的DRAM,相当于该内存的1 GB/s带宽。其中,PU则构建在一个32位ISA上,具有大量优化功能,例如基本逻辑指令和rotate指令。
Upmem透露,他们的处理器以及该项技术已获得专利,目前正在与内存供应商合作开发20nm制程工艺的产品。
2、内存互联:惠普Gen-Z芯片组
Gen-Z是一套可扩展的高性能互联架构,主要负责对接计算机与内存。
具体来说,Gen-Z能够实现高传输带宽与低延迟水平,其传输带宽主要为数十GB每秒到数百GB每秒,加载到使用内存延迟低于100纳秒。另外,它还具有较高的软件兼容性,供应商无需修改操作系统都可实现互联。
而惠普在会上展示的Gen-Z,是能够适用于Exascale级超算技术的芯片组,其计算性能和驱动都将进一步提高,逐渐满足数据量越来越庞大的工作负载需求。
3、云计算虚拟化:AWS Nitro架构
AWS推出的Nitro架构可谓是给云计算领域的虚拟化计算带来了十分新颖的发展方向。会上,AWS高级首席工程师Anthony Liguori重点为大家介绍了Nitro的发展。
Nitro既是一块ASIC芯片,也是一套轻量级的虚拟管理系统。它包括Nitro虚拟机管理程序、Nitro加速卡和Nitro安全芯片三大部分,能够满足用户在云端的存储、网络、监控和安全等需求,进一步提高服务器性能,并允许用户已安全的方式支持各种裸机实例类型。

▲Nitro架构三大部分介绍
五、其他相关芯片技术的测试与应用
这次参会的高科技企业和知名高校关注AI芯片、GPU、CPU和存储芯片等技术的发展和应用,也会聚焦其他例如机器学习基准测试、光电I/O芯片这方面的技术。

1、MLperf:MLPerf Benchmark ML基准测试套件
MLPerf是一项用于测试ML(Machine Learning)硬件、软件以及服务的训练和推理性能的公开基准,同时也正迅速成为测量机器学习性能的行业标准。
该基准得到了来自亚马逊、ARM、百度、谷歌和微软等40多家公司和研究人员的支持。而在这次会议上,谷歌大脑计划的工程师Peter Mattson为大家介绍了MLPerf Benchmark机器学习基准测试套件的更新与进展。
2、Cypress:Wi-Fi和蓝牙组合芯片CYW89459
作为全球领先的嵌入式解决方案供应商,Cypress(赛普拉斯)在此次会上为大家介绍了一款用于物联网和汽车的无线连接组合芯片,名为CYW89459。
据介绍,CYW89459能够以高性能、低功耗的方式,连接Wi-Fi和蓝牙5.1,通过简单的方式进一步全面实现各个设备之间的网络通信。目前,该组合芯片主要用于物联网和汽车领域。
3、Ayar Labs:光电I/O芯片TeraPHY
Ayar Labs是一家美国硅光子创企,在此次会议上,该公司的总裁Mark Wade为大家分享了一个用于低功耗、高带宽的光电I/O芯片技术,名为TeraPHY。
据悉,TeraPHY采用了格芯的45nm CMOS SOI工艺,它能够让芯片之间以光的速度进行通信连接,且它的带宽将高达1 Terabit/s,比传统铜互联芯片的速度还要快十倍。
结语:芯片技术百花齐放,期待未来新突破
在今年的Hot Chips会议上,不管是学界还是业界的研究人员、学者都展示了他们最前沿和先进的芯片工艺和技术,进一步提升了行业的技术水平,也给行业带来更多元化的解决方案。
随着芯片的制程工艺越来越接近天花板,全球芯片领域的科技公司依然在不断用新的技术去突破物理极限,尝试为目前芯片领域的瓶颈提供新的出口和研究方向。
在未来,当这些技术的全面商业化落地后,它们的应用与更新是否又会为行业带来更具变革性的突破,这是十分值得我们期待的。
“特别声明:以上作品内容(包括在内的视频、图片或音频)为凤凰网旗下自媒体平台“大风号”用户上传并发布,本平台仅提供信息存储空间服务。
Notice: The content above (including the videos, pictures and audios if any) is uploaded and posted by the user of Dafeng Hao, which is a social media platform and merely provides information storage space services.”

