


学界 | SIGIR 2018最佳论文:基于流行度推荐系统有效性的概率分析
2018年07月12日 13:26:49
来源:机器之心

原标题:学界 | SIGIR 2018最佳论文:基于流行度推荐系统有效性的概率分析 选自SIGIR
原标题:学界 | SIGIR 2018最佳论文:基于流行度推荐系统有效性的概率分析
选自SIGIR 2018
作者:Rocio Cañamares、Pablo Castells
机器之心编译
参与:刘晓坤、思源、李泽南
ACM 国际信息检索研究与发展会议 SIGIR 2018 近日于美国密歇根州 Ann Arbor 举行。昨日,大会公布了最佳论文等奖项,来自马德里自治大学(Universidad Autónoma de Madrid)的学者 Rocio Cañamares 和 Pablo Castells 的论文《Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems》获得了最佳论文奖,微软与马萨诸塞大学阿姆赫斯特分校合作论文《Cross-Domain Regularization for Neural Ranking Models Using Adversarial Learning》获得最佳短论文奖。本文将对最佳论文进行简要介绍。
引言
使用 IR 方法论和指标用于推荐系统的评估在近年来发展迅速,已成为该领域中的常用实践方法,其将理解推荐看成排序任务 [14]。然而 IR 指标已被发现在推荐受欢迎条目(即很多人知道、喜欢、评分或交互的条目 [4,21,35])的奖励算法中有很强的偏见。同时,当前最佳的推荐算法也被发现在推荐多数人喜欢的条目时存在显而易见的偏见 [21]。人们可能自然地对常用的实验设置和最佳算法真实输出的可靠性提出质疑。
这个问题在 IR 方法论并没有得到特别的关注,因为流行度偏见在传统的搜索和 IR 任务中并没有出现,或者没有以如此奇怪的方式出现。推荐系统评估的常用数据集的流行度偏见非常强,即使是纯粹的和简单的流行度排序,相比当前最佳个性化算法 [14],也可能达到次优但不可忽视的推荐准确率。并且,实际上在高评分稀疏性条件下,其差距不一定是微不足道的。因此近期的研究开始着手解决这个问题,目前主要聚焦于证实和测量流行度偏见,并将其移除 [4,21,34,35]。但一个基础的问题仍然未得到回答:流行度偏见真的是必须要避免的吗?如果推荐流行的条目恰好是正确的,那么评估指标和推荐算法不是应该正好支持它们吗?
对产品的主要评价确实对人们而言是很有用的信息,这是一种简单、公平而有用的人类决策大部分时候默认的标准。并且我们实际上经常接受这个标准,例如,在缺乏足够证据来做出个人选择的时候,或作为从零开始的减少决策精力损耗的引导,或作为社会学习机制 [3]。从应用的角度上看,基于很多选择的推荐在很多情形中都是可接受的 [16],并只需要最少的开发技巧和维护成本。它确实是一个使用广泛的方法,很多应用以热门排行榜、最热卖排行榜、平均用户评分等的形式展示它。甚至在充分训练的个性化推荐系统中,热卖产品列表对于新用户而言仍然能提供很好的帮助。
多数人品味的有效性实际上有其统计意义:很多人喜欢的条目(根据观察到的用户活动)很有可能被很多(测试集中的)其他人所喜欢 [19]。然而,从实验的角度上看,如果观察结果有些微偏见,并且该偏见在训练数据和测试数据中一致,则推荐中的多数人偏见可能只是准确地猜测实验者的数据中隐含的用户偏好,而不是真正满足用户口味的产品。此外,多数人信号可能被来自真实用户赞赏的趋势所干扰 [5,29]。近期的研究表明多数人构造涉及某种程度的可能性,凭此不同的输出都有可能成为最流行的产品 [31]。此外,人们知道公众动态经常受到外部、内部信息以及偏见因素的影响 [26,27,29],例如大众媒体 [7]、市场营销、意见管理 [6]、算法偏见 [28],或社会整合 [13]。
因此问题是非常开放的,即流行度到底是不是真正高效的实现准确推荐的要素,它的效用在什么样的程度以及什么样的情况下有效,以及我们是否能恰当地度量它。我们通过考虑、分析和对比 IR 度量的两个方面来解决这个问题,即有偏和无偏 IR 度量。前者表示在一般离线实验中测量的值,其中相关信息并不是随机缺失的(MNAR)[23,24,25,34,35],后者表示在缺失信息可获得的情况下的真实度量值。
Rocio Cañamares 等研究者在理论和实证层面都做了研究。在分析阶段,他们构建了问题的概率表达式。从修改推荐系统的概率排序原则 [30] 开始,研究者通过对比最佳排序分析了基于流行度的推荐。Rocio Cañamares 等人发现流行度的有效性或无效性取决于三个主要变量的相互作用:条目相关性、用户对条目的发掘度以及用户决策与发掘条目之间的相互影响。他们确定了决定流行度的因素之间的关键概率依赖性,并且描述了由不同独立性假设定义的一组趋势,其中每个趋势都导致了特定的流行度行为模式。通过使用在众包平台构建的数据集,实证性观察也支持理论发现,其中该众包数据移除了公共数据集一些常见的偏见。
在其它研究结果中,Rocio Cañamares 等研究者证明并展示了一种定性的矛盾,即在一般离线实验设置所测量的准确率与在无偏观察下估计的真实准确率之间的矛盾。研究者们确定了确保流行度可成为推荐中安全元素的条件,并且他们还描述并说明了这样一种相反情况,即流行度可能完全是一种误导的方向,它会指向比随机推荐更差的效用。研究者们进一步发现平均评分可能比评分的数量更加有效,它作为很多情况下的推荐的趋势,而这与有偏度量值所建议的正好相反。最后,研究者展示了他们的研究成果在个性化协同过滤算法中的意义。
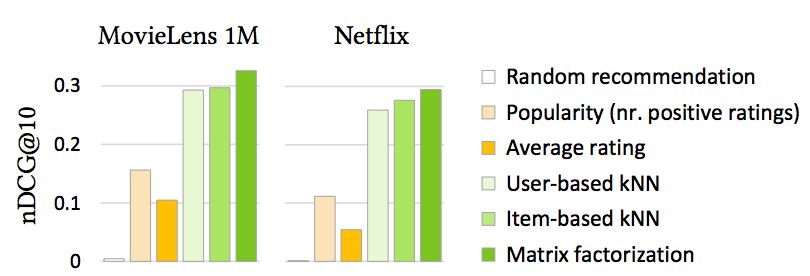
图 1:非个性化流行度推荐的典型离线实验结果与个性化算法在两个公共数据集上的对比。
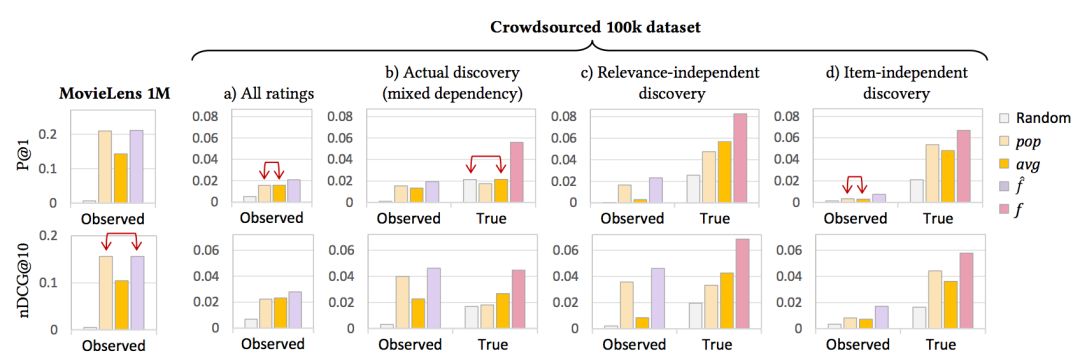
图 5:分析结果验证。a)栏对应 2 和 3a 的结论;c)对应 2 和 3c 的结论;d)匹配结论 1;b)例证了结论 4 中的一般场景。研究确认了观察到的和真实情况的准确率之间的几个不一致,并且发现了在情景 d 中流行度推荐的低于随机推荐的表现。我们还展示了(oracle)最佳非个性化排名的准确率。非统计学上显着的差异(2-tailed Student』s t-test 在 𝒑 < 𝟎. 𝟎𝟏时)在图中用红色双箭头表示。
论文:Should I Follow the Crowd? A Probabilistic Analysis of the Effectiveness of Popularity in Recommender Systems
论文链接:http://ir.ii.uam.es/pubs/sigir2018.pdf
摘要:在推荐系统的评估中使用 IR 方法论在近年来已成为惯例。然而,IR 指标在推荐受欢迎条目的奖励算法中被发现有很强的偏见,相同的偏见在当前最佳的推荐算法中也出现了。近期的研究证实并测量了这种偏见,并提出了相应的方法来避免它们。基础问题仍然是开放性的:即流行度是不是一种需要避免的偏见;它在推荐系统中是不是一种有用的和可靠的信号;或者它是否可能由实验偏见带来不公平的奖励。我们通过确定和建模可以决定(关于关键随机变量之间的依赖关系,涉及条目评分、发现和相关性)答案的条件,在形式层次上解决了这个问题。我们发现了保证有效流行度(或恰好相反)的条件,和反映真实有效性的测量指标值的条件,或定量地从中导出。我们通过经验结果例证并证实了理论发现。我们构建了一个完全没有通常公共数据中存在的偏见的众包数据集,其中我们解释了在常见带偏见离线实验设置的准确率,和通过无偏见观察数据测量得到的真实准确率之间的矛盾。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






