


NAACL | 评价端到端生成式聊天系统,哈工大提出新型数据集 LSDSCC
2018年07月06日 17:21:45
来源:机器之心

原标题:NAACL | 评价端到端生成式聊天系统,哈工大提出新型数据集 LSDSCC 机器之心专栏
原标题:NAACL | 评价端到端生成式聊天系统,哈工大提出新型数据集 LSDSCC
机器之心专栏
作者:徐振、刘秉权(哈尔滨工业大学智能技术与自然语言处理实验室)
端到端的生成式聊天系统在模型层面的研究工作近年来取得了长足进展,但是对于生成结果的合理评价方法的探索却不足,无法为模型的优化提供有效指引。基于此,本文提出了两种用于自动测评生成回复的语义多样性的量化指标 PDS 和 MDS,并开放了一个由电影领域的高质量 query-response 组成的数据集。本工作是哈工大ITNLP实验室联合北航的姜楠及其导师一起完成的。
引言
得益于深度学习的发展,端到端的生成式聊天系统在模型层面的研究工作在近两到三年中取得了长足的进步 [1-5]。与之相比,对于生成结果的合理评价方法的探索则极为滞后,无法为模型的优化方向提供有效的指引。现有的较为通用的自动评价方法多是来源于机器翻译、自动文摘等领域,被普遍认为无法有效评测端到端的生成式模型生成结果的语义多样性,而人工评测的开销较大且无法保证很高的一致性 [6,7]。与此同时,尽管目前开放域聊天的通用训练数据较多,但针对特定领域的富含较大信息量的对话数据则比较缺少。针对这些问题,论文 LSDSCC: A Large Scale Domain-Specific Conversational Corpus for Response Generation with Diversity Oriented Evaluation Metrics 提出了两种用于自动评测生成回复的语义多样性的量化指标,并开放了一个由电影领域的高质量 query-response 组成的数据集。
1 新的端到端对话生成数据集 LSDSCC
生成式聊天是自动对话领域中最前沿的研究方向之一,其核心技术就是利用端到端的一体化结构自动生成回复(Response Generation),而回复生成模型通常需要大规模的聊天数据进行训练。理论上,用户通过社交网络平台积累的海量对话数据可以用于训练端到端的回复生成模型。然而,目前学术界常用的大规模训练数据集普遍存在噪声数据比例较高、主题分散等问题,给模型的训练和评价带来了一定的问题。针对这方面的问题,本文给出了一个基于单一领域数据源的高质量对话生成训练数据集。
1.1 基于单一领域的对话生成数据集
现有的很多聊天数据集通常是开放域数据集(包括很多领域,如电影,音乐等),如果生成的回复与参考回复不在统一领域,评价生成回复的质量的难度可想而知。除此之外,常见的训练数据集诸如 Twitter、Ubuntu 等 [8,9],包含了大量的噪声信息(如,typos 和 slangs,超链接等),也不利于模型的有效训练。因此,使用高质量的单一领域数据集评价不同的回复生成模型更加合理。为此,作者选取了 Reddit 论坛的电影板块的对话作为候选数据集,并在此基础上进行了数据清洗(替换掉 html 标签、表情符等)、词表截断以及对话精简(删除特别长的句子)等复杂的预处理。
数据清洗:首先,在 Reddit 获取的原始人与人的对话数据中通常包含 mark-down 和 html 标签,这些标签会干扰语句的合法性,作者将这种类型的标签剥离,从而得到完整通顺的句子。此外,Reddit 的回复通常还包含大量的 URL、Email 和数字,本文利用正则表达式将此类字符串统一格式化为「__URL__」、「__EMAIL__」和「__DIGIT__」。然后,如 Reddit 这样的社交网络中会经常使用表情符号传递信息,作者将利用对应的表情符号与词语的映射表,将其转换为对应的词语,从而有利于文本分析和理解。最后,本文将重复多次的词语或者字(如,「cooool」and「ahahaha」)也转化为正常的形式。
词表剪枝:经过上述清洗之后,词表中仍然存在大量的超长或者低频字串(如,「ILoveYou」),这导致词表包含超过 160K 的词语。如表 1 所示,这些词语中约 45% 左右的是超长组合词汇或者不是 ascii 的词汇。对于「序列-序列」模型来说,这么大的词表将使得模型参数非常庞大、模型很难收敛等问题。将这些词语全部映射成「UNK」会损失掉大量的信息,从而影响模型的表现。为此,作者将超长或者低频的字符串拆解成若干高频词,尽量保留的回复所包含的信息。
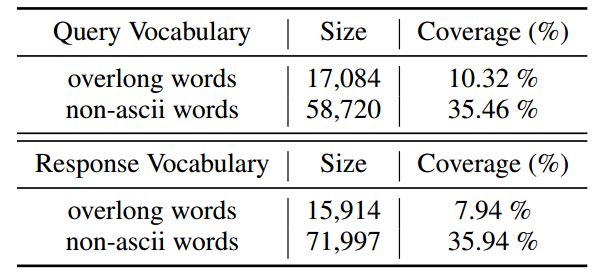
表 1 Post 和 Response 中的噪声词汇的比例
对话精简:图 1 是数据集中询问 post 和回复 response 的长度分布情况,可以看出约有 40% 的话语长度超过了 50。而大多数回复生成模型的关键组件循环神经网络(RNN)在实际的应用中很难捕获长距离的语义信息。此外,回复过长,「序列-序列」模型中的解码器也很难训练,并且生成过程中的效率也会受到影响。【同时,聊天场景下的回复通常是用很少的句子表达一个单一的观点】。为此,作者选取了询问 post 长度不超过 100、回复长度不超过 60 的对话,最终获取了一个包含约 74 万单论对话的数据集。
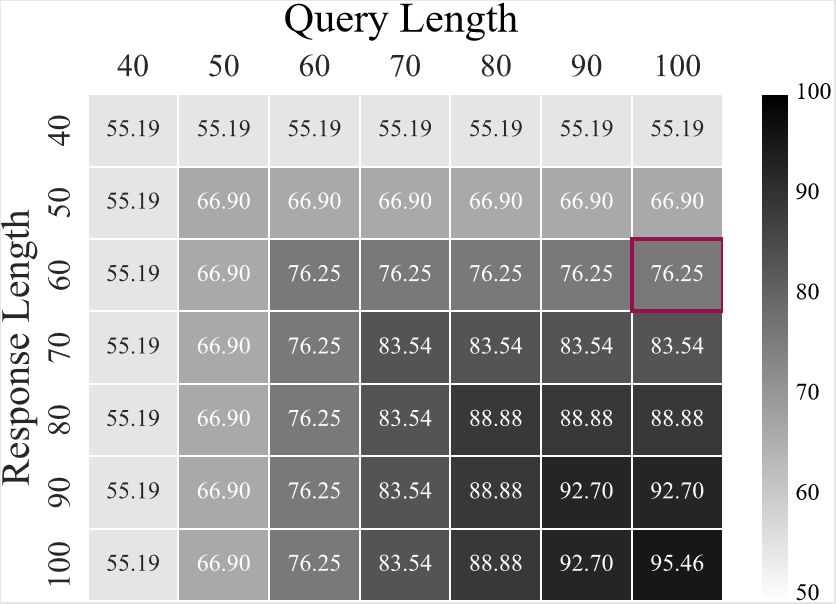
图 1 数据集中 Post 和 Response 长度分布
2 面向生成结果语义多样性的自动评价方法
自动生成的回复的自动评价方法一直都是一个难点。目前大多数生成的回复质量自动评价方法大多数来源于机器翻译 (如 BLEU Score)[10,11],这些方法可以从一定程度上度量生成的回复与输入话语的相关性。但是,由于聊天场景下回复通常比较发散(一个输入话语常有很多语义相差很大的回复,如表 2 所示),与机器翻译有很大不同,因此上述这些自动方法很难评价生成回复的质量,特别是面向回复的语义多样性 (semantic diversity) 的评价。此外,基于人工标注的方法固然能够保证较全面的评价,但主要问题在于开销较大且无法保证很高的一致性。为了自动地对回复生成模型合理地评价,作者使用半自动地方法构建了一个电影领域的、高质量的测试集合,同时提出了两个多样性的自动评价指标。

表 2 多样性回复的实例
2.1 复合参考回复集的半自动构建
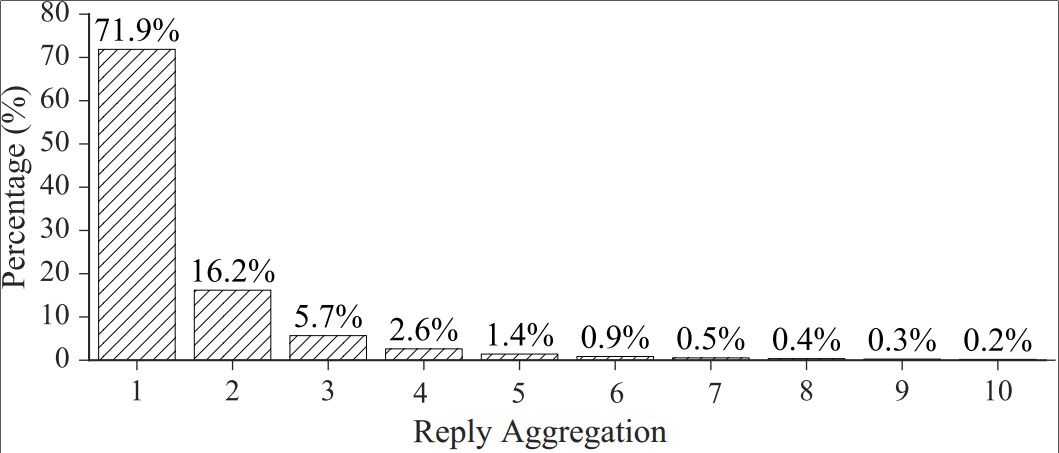
图 2 数据集中询问 post 的回复个数分布
图 2 给出了 Reddit 语料中 post 的回复个数分布。可以看出,约 70% 的只有一个回复,16% 的有两个回复,这与我们最终的聊天场景下一个输入话语有很多回复不相符。因此,如果使用这样的测试数据去衡量回复生成模型的表现是不合理的。为此,本文使用半自动的方法为输入话语构建了多个回复,并按照回复语义关系进行了分组。
为一个输入话语构建多个回复的第一步就是从大规模的数据中将与输入话语语义相似的话语找出来。为此,作者通过基于 TF-IDF 和语义向量的相似度方法计算话语之间的相似度,从而找到跟当前话语最相似的若干个语句。整个过程可以分为两个阶段,首先根据词的 TF-IDF,使用 apache lucence 抽取 100 个最相似的语句;然后,使用 Doc2Vec 将当前话语和所有候选语句向量化,根据向量计算当前话语与候选语句之前的语义相似度,进而对候选语句重新排序,选取相似度大于某一阈值(如,0.9)作为当前话语最相似的语句。
将与当前话语语义相似的语句的回复作为当前话语的回复是合理的,因此,作者将 15 个最相似语句的回复收集起来作为当前话语的回复。而在社交网络中噪声比较大,会有一些不合理的回复混入到其中。为了保证数据质量,邀请了一些标注人员进行话语与回复的相关性判断。在相关性判断过程中,要求标注人员首先判断候选回复的语法是否正确,是否与对应的话语语义相关,如果这两个条件都满足,该回复被标为「1」,否则被标为「0」。经过这个过程之后,每个话语的回复的个数分布如下:
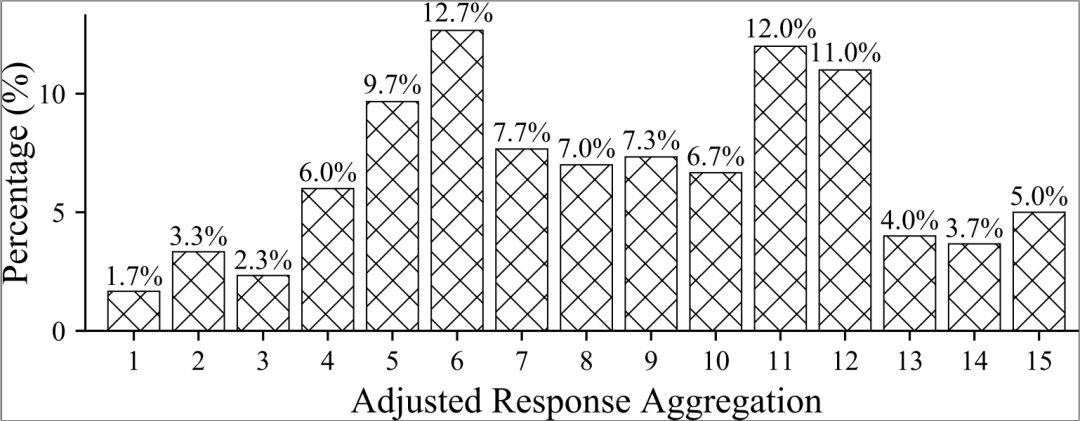
本文主要的目的是构建一个可以评价对话模型多样性的测试数据集,为此,作者对获取的回复集合进行了分组,每个组内的回复语义高度相关,组之间的语义有较大差异。首先,通过回复之间的词重叠度的将回复自动分组。这种自动分组方法非常粗糙,只能将一些词重叠比较多的回复归并到一个组里,而对于那些语义相近用词差异很大的回复没法合并到一个组里。为此,作者请标注人员将语义相似的组合并,从而实现了将话语的多个回复分成了若干组。在这个过程中标注人员需要先理解 post 的语义,然后阅读每组回复理解其表达的语义,在此基础上,将语义相近的回复组进行归并。因此,可以通过对话模型生成回复对于这些组的覆盖情况判断其多样性。
2.2 基于复合参考回复的多样性评价指标
现有的回复生成框架大都基于神经机器翻译模型,因此 BLEU Score 对于生成结果的语义相关性的度量是有相对的指示价值的。然而,由于多个参考回复的语义差异较大,使用生成回复与每一个参考回复的平均 BLUEU 值评价生成模型的表现是不合理的。为了揭示生成的回复的多样性,本文首先提出了一个基于 Multi-BLEU 的 MaxBLEU 评价生成回复与参考回复集合之前的相关性。然后,基于 MaxBLEU 提出了两个多样性的评价指标。其过程如下:
给定一个输入问句,生成模型会生成一组回复假设 {h_i},同时还有一组半自动的参考回复 {r_ij},r_ij 表示第 i 组的第 j 个回复,基于此 MaxBLEU 定义如下:
基于 Max BLEU,本文提出了两个多样性评价指标:平均多样性 (Mean Diversity Score, MDS) 和概率多样性 (Probabilistic Diversity Score, PDS),用于评价生成模型生成的回复的多样性。其计算过程如表所示,

从 MDS 和 PDS 算法中可以看出,MDS 假设每组回复都有相同的概率,而不考虑其中包含的参考回复的数量;与之相反,PDS 在估算每组回复的概率的时候,则将回复的数量考虑在其中。总之,MDS 和 PDS 越大,生成的假设回复覆盖的参考回复组越多,对应的生成模型的多样性就越好。下图用一个实际的例子展示了 PDS 和 MDS 计算过程。

3 结语
本文提出了一个电影领域的对话数据集以及复合参考回复的测试集,并基于此提出了两个度量生成式对话模型多样性的评价指标 PDS 和 MDS。实验发现本文提出的评价指标可以更好的反应已有的回复生成模型在回复多样性上的表现。此外,由于缺乏统一的评价标准和数据集,生成式对话的研究一直无法专注于模型的主航道上,本文提出的数据集和评价方法从一定程度上缓解这个问题。同时,期望本文的多样性指标可以为构建基于多样性的损失函数提供新的研究思路,从而实现对回复多样性的直接优化。
数据集链接:http://anthology.aclweb.org/attachments/N/N18/N18-1188.Datasets.zip
参考文献
[1] Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conversation. In Proc. of ACL, pages 1577–1586.
[2] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. 2016a. A diversity-promoting objective function for neural conversation models. In Proc. of NAACL-HLT, pages 110–119.
[3] Iulian Vlad Serban, Alessandro Sordoni, Yoshua Bengio, Aaron C. Courville, and Joelle Pineau. 2016. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proc. Of AAAI, pages 3776–3784.
[4] Jianan Wang, Xin Wang, Fang Li, Zhen Xu, Zhuoran Wang, and Baoxun Wang. 2017. Group linguistic bias aware neural response generation. In Proceedings of the 9th SIGHAN Workshop on Chinese Language Processing, pages 1–10.
[5] Yu Wu, Wei Wu, Dejian Yang, Can Xu, Zhoujun Li, and Ming Zhou. 2018. Neural response generation with dynamic vocabularies. In Proc. of AAAI.
[6] Chia-Wei Liu, Ryan Lowe, Iulian Serban, Mike Noseworthy, Laurent Charlin, and Joelle Pineau. 2016. How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. In Proc. of EMNLP, pages 2122–2132.
[7] Ryan Lowe, Michael Noseworthy, Iulian Vlad Serban, Nicolas Angelard-Gontier, Yoshua Bengio, and Joelle Pineau. 2017. Towards an automatic turing test: Learning to evaluate dialogue responses. In Proc. of ACL, volume 1, pages 1116–1126.
[8] Alan Ritter, Colin Cherry, and William B. Dolan. 2011. Data-driven response generation in social media. In Proc. of EMNLP, pages 583–593.
[9] Rudolf Kadlec, Martin Schmid, and Jan Kleindienst. 2015. Improved deep learning baselines for ubuntu corpus dialogs. In Machine Learning for SLU Interaction Workshop, NIPS.
[10] Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proc. of ACLCVPR, pages 311–318. Association for Computational Linguistics.
[11] Michel Galley, Chris Brockett, Alessandro Sordoni, Yangfeng Ji, Michael Auli, Chris Quirk, Margaret Mitchell, Jianfeng Gao, and Bill Dolan. 2015. deltableu: A discriminative metric for generation tasks with intrinsically diverse targets. In Proc. Of ACL, pages 445–450.
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






