


学界 | 分离特征抽取与决策制定,如何用6-18个神经元玩转Atari游戏
2018年06月18日 13:56:19
来源:机器之心

原标题:学界 | 分离特征抽取与决策制定,如何用6-18个神经元玩转Atari游戏 选自arXiv
原标题:学界 | 分离特征抽取与决策制定,如何用6-18个神经元玩转Atari游戏
选自arXiv
机器之心编译
参与:路
本论文提出了一种在复杂的强化学习设置中同时又独立地学习策略和表征的新方法,通过基于向量量化和稀疏编码的两种新方法来实现。这使得仅包含 6 到 18 个神经元的网络也可以玩转 Atari 游戏。
在深度强化学习中,大型网络在直接的策略逼近过程中,将会学习如何将复杂的高维输入(通常可见)映射到动作。当一个拥有数百万参数的巨型网络学习较简单任务时(如玩 Qbert 游戏),学到的内容中只有一小部分是实际策略。一个常见的理解是网络内部通过前面层级学习从图像中提取有用信息(特征),这些底层网络将像素映射为中间表征,而最后(几)层将表征映射至动作。因此这些策略与中间表征同时学习得到,使得独立地研究策略几乎不可能。
将表征学习和策略学习分离方能独立地研究二者,这潜在意义上能够使我们对现存的任务及其复杂度有更清晰的理解。本论文就朝着这个目标前进,作者通过实现一个独立的压缩器(即特征提取器)将特征提取和决策分离开来,这个压缩器在策略与环境互动中所获取的观测结果上进行在线训练。将网络从构建中间表征中解放出来使得网络可以专注于策略逼近,从而使更小的网络也能具备竞争力,并潜在地扩展深度强化学习在更复杂问题上的应用。
该论文的主要贡献是提出一种在复杂的强化学习设置中同时又独立地学习策略特征的新方法。这通过基于向量量化(Vector Quantization,VQ)和稀疏编码(Sparse Coding,SC)的两种新方法来实现,研究者将这两种方法分别称为「Increasing Dictionary VQ」和「Direct Residuals SC」。随着训练继续、网络学习到更复杂的策略,网络与环境的复杂互动带来更多新的观测结果;特征向量长度的增长反映了这一点,它们表示新发现的特征。类似地,策略通过可解决维度增加问题的指数自然进化策略(Exponential Natural Evolution Strategy)进行训练。实验结果显示该方法可高效学习两种组件,从而仅使用 6 到 18 个神经元(神经元数量比之前的实现少了两个数量级)组成的神经网络就可以在多个 ALE 游戏中获得当前最优的性能,为专用于策略逼近的深度网络研究奠定了基础。
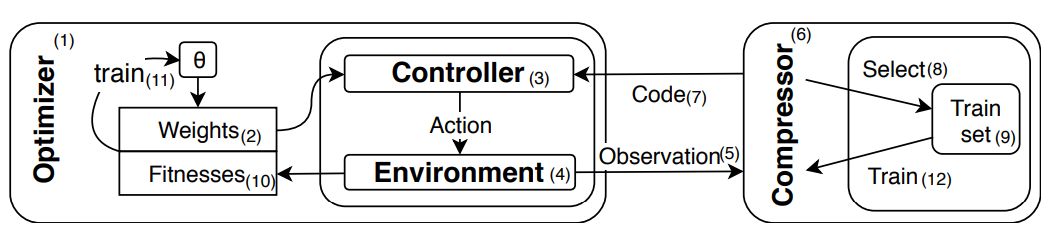
图 1:系统图示。在每个生成阶段,优化器(1)为神经网络控制器(3)生成权重集合(2)。每个权重都是偶发地(episodically)通过环境进行评估(4)。在每一步,环境将观测结果(5)发送到外部压缩器(6),压缩器生成紧凑编码(7)作为网络输入。压缩器为训练集(9)选择观测结果(8)。在该 episode 结束时,环境向优化器返回适应度分数(累计奖励,10)进行训练(神经进化,11)。压缩器训练(12)发生在生成阶段。
3 方法
该系统包括四个主要部分:1)Environment(环境):Atari 游戏,采取动作、提供观测结果;2)Compressor(压缩器):从观测结果中提取低维代码,同时系统其他部分执行在线训练;3)Controller(控制器):策略逼近器,即神经网络;4)Optimizer(优化器):学习算法,随着时间改进网络的性能,在本研究案例中优化器采用的是进化策略。
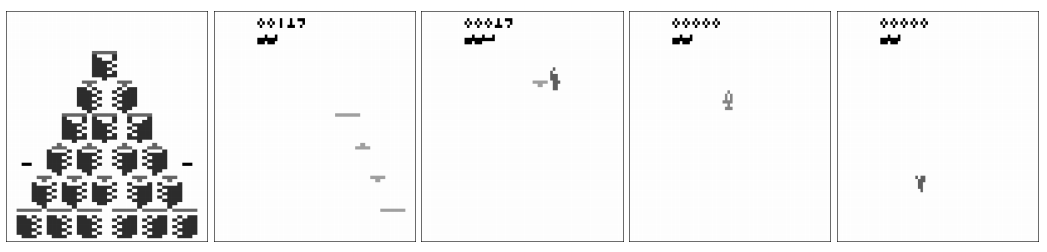
图 2:训练中心点。在 Qbert 游戏运行期间,使用 IDVQ 训练多个中心点。注意第一个中心点如何捕捉游戏的初始状态(背景),其他中心点将特征构建为后续残差:发光立方体、avatar 和敌人。
5 结果
研究者在 10 个 Atari 游戏上展示了对比结果,这十个游戏选自 ALE 模拟器上的数百个游戏。选择结果依据以下筛选步骤:1)OpenAI Gym 上可获取的游戏;2)与 [210, 160] 具备同样观测分辨率的游戏;3)不包含 3d 视角的游戏。

表 1:本研究提出方法在 Atari 游戏样本上与 HyperNeat [HLMS14] 和 OpenAI ES [SHC+17] 的对比结果。所有方法都是从头开始在原始像素输入上训练的。HyperNeat 列的结果使用的网络具备一个包含 336 个神经元的隐藏层。OpenAI ES 列中的结果使用两个包含 64 个神经元的隐藏层。IDVQ+XNES 列的结果未使用隐藏层。列 # neur 表示单个(输出)层中使用的神经元数量。粗体数字表示设置条件下最好的分数,斜体数字表示中间分数。
论文:Playing Atari with Six Neurons

论文地址:https://arxiv.org/abs/1806.01363
摘要:Atari 游戏上的深度强化学习直接将像素映射至动作;本质上,深度神经网络同时负责提取有用信息和基于此进行决策。为了设计专用于决策的深度网络,我们提出了一种新方法,独立但同时学习策略和紧凑状态表征,以得到强化学习中的策略逼近。状态表征通过基于向量量化和稀疏编码的新算法生成,状态表征与网络一道接受在线训练,且能够随着时间不断扩大表征词典规模。我们还介绍了允许神经网络能和进化策略处理维度变化的新技术。这使得仅包含 6 到 18 个神经元的网络可以学习玩 Atari 游戏,性能可以达到甚至偶尔超过在大两个数量级的深度网络上使用进化策略的当前最优技术。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






