


让AI掌握星际争霸微操:中科院提出强化学习+课程迁移学习方法
2018年04月07日 01:13:21
来源:机器之心

原标题:让AI掌握星际争霸微操:中科院提出强化学习+课程迁移学习方法 选自arXiv 机器之心编译
在围棋之后,即时战略游戏星际争霸是人工智能研究者们的下一个重要目标。近日,中科院自动化所提出了一种强化学习+课程迁移学习方法,让 AI 智能体在组队作战的条件下掌握了微操作的能力,该研究或许可以让多智能体 AI 方向的发展向前推进一步。该论文已被学术期刊 IEEE Transactions on Emerging Topics in Computational Intelligence 收录。
该研究的代码和结果已公开:https://github.com/nanxintin/StarCraft-AI
人工智能(AI)在过去的十年中已经有了巨大的进展。作为 AI 研究的绝佳测试平台,游戏自从 AI 诞生之时就在其身边推动技术的发展,与人工智能产生联系的游戏包括古老的棋盘游戏、经典的 Atari 街机游戏,以及不完美信息博弈。这些游戏具有定长且有限的系列动作,研究人员只需要在游戏环境中控制单个智能体。此外,还有多种更加复杂的游戏,其中包含多个智能体,以及复杂的规则,这对于 AI 研究非常具有挑战性。
在本论文中,我们专注于即时战略游戏(RTS)来探索多智能体的控制。RTS 游戏通常需要即时反应,这与棋盘游戏的回合制不同。作为最为流行的 RTS 游戏,《星际争霸》拥有庞大的玩家基础和数量众多的职业联赛——而且这个游戏尤其考验玩家的策略、战术以及临场反应能力。对于游戏 AI 的研究,星际争霸提供了一个理想的多智能体控制环境。近年来,星际争霸 AI 研究取得了令人瞩目的进展,这得益于一些星际争霸 AI 竞赛,以及游戏 AI 接口(BWAPI)的出现。最近,研究人员开发出了一些更加有效的平台来推动这一方向的发展,其中包括 TorchCraft、ELF 和 PySC2。
星际争霸 AI 旨在解决一系列难题,如时空推理、多智能体协作、对手建模和对抗性规划 [ 8 ]。目前,设计一款基于机器学习的全星际游戏 AI 是不现实的。许多研究者将微操作为星际争霸人工智能研究的第一步 [11]。在战斗场景中,单位必须在高度动态化的环境中航行,攻击火力范围内的敌人。星际争霸有很多微操方法,包括用于空间导航和障碍规避的潜在领域 [12] [13]、处理游戏中的不完整性和不确定性的贝叶斯建模 [14]、处理建造顺序规划和单位控制的启发式博弈树搜索 [15],以及用于控制单个单位的神经进化方法 [16]。
作为一种智能学习方法,强化学习 ( RL ) 非常适合执行序列决策任务。在星际争霸微操任务中,RL 方法有一些有趣的应用。Shantia 等人使用在线 Sarsa 和带有短期记忆奖励函数的神经装配 Sarsa 来控制单位的攻击和撤退 [ 17 ]。它们利用视觉网格获取地形信息。这种方法需要手工设计,而且输入节点的数量必须随着单元的数量而改变。此外,他们还采用增量学习方法将任务扩展到具有 6 个单元的更大场景中。但是,增量学习的成功率仍然低于 50 %。温德尔等人在微操作中使用不同的 RL 算法,包括 Q 学习和 Sarsa [ 18 ]。他们控制一个强大的单位对抗多个彼此之间不存在协作的弱单位。
在最近的几年里,深度学习在处理复杂问题上已经实现了令人瞩目的成果,也大大提高了传统强化学习算法的泛化能力和可扩展性 [5]。深度强化学习(DRL)可以让智能体学习如何通过端到端的方式在高维状态空间中做出决策。Usunier 等人提出了一种通过深度神经网络进行微操作的强化学习方法。他们使用 greedy MDP 在每个时间步上有顺序地为单位选择动作,通过零阶优化(zero-order optimization)更新模型。这种方法能够控制玩家拥有的所有单位,并检视游戏的全局状态。Peng 等人则使用 actor-critic 方式和循环神经网络(RNN)来打星际争霸的对战(参见:阿里人工智能新研究:在星际争霸中实现多兵种协同作战)。单位的控制由隐藏层中的双向 RNN 建模,其梯度更新通过整个网络高效传播。另一方面,与 Usunier 和 Peng 设计集中控制器的工作不同,Foerster 等人提出了一个多智能体 actor-critic 方法来解决去中心的微操作任务,这种方法显著提高了集中强化学习控制器的性能 [22]。
对于星际争霸的微操,传统方法在处理复杂状态、行动空间和学习合作策略方面存在困难。现代方法则依赖于深度学习引入的强大计算能力。另一方面,使用无模型强化学习方法学习微操通常需要大量的训练时间,在大规模场景中,这种情况更为明显。在中科院自动化所的新研究中,研究人员试图探索更高效的状态表示以打破巨大状态空间引发的复杂度,同时提出了一种强化学习算法用以解决星际争霸微操中的多智能体决策问题。此外,研究人员还引入了课程迁移学习(curriculum transfer learning),将强化学习模型扩展到各种不同场景,并提升了采样效率。
本论文的贡献主要分为三部分。首先,我们提出了一种高效的状态表征方法以处理星际争霸微操中的大型状态空间。这种方法考虑了单位的属性与距离,并允许双方使用任意数量的单位。与其他相关研究相比,我们的状态表征方法将更加高效、简洁。其次,我们提出了一种参数共享的多智能体梯度下降 Sara(λ) 算法(PSMAGDS)来训练我们的单位。使用神经网络作为函数近似器,智能体会共享集中化策略的参数,并同时使用自己的经验更新策略。这种方法能有效地训练同质智能体,并且鼓励合作行为。为了解决稀疏问题和延迟奖励,我们在 RL 模型中引进了包含小型中间奖励的奖励函数。该奖励函数能提升训练过程,并成为帮助单位相互协作的内在动力。最后,我们提出了一种迁移学习方法来扩展模型适应各种情景。与从头开始学习相比,这种方法在训练速度上有非常大的提升,并且在学习性能上也有很大的扩展。在大规模场景中,我们应用课程迁移学习(curriculum transfer learning)方法成功地训练了一组单位。就胜率而言,我们提出的方法在目标场景中优于很多基线方法。
本论文由六部分组成。第二节描述了星际争霸微操问题,以及强化学习和课程迁移学习的背景。在第三节中,本论文提出了用于微操的强化学习模型,包括状态表征方法、网络架构和行动定义。在第四节中,本论文介绍了参数共享的多智能体梯度下降 Sara(λ) 算法(PSMAGDS)和奖励函数。在第五节中,研究者介绍了本论文使用的星际争霸微操场景和训练细节。在最后第六节中,研究者对实验结果进行了分析,并进一步讨论模型学习到的策略。
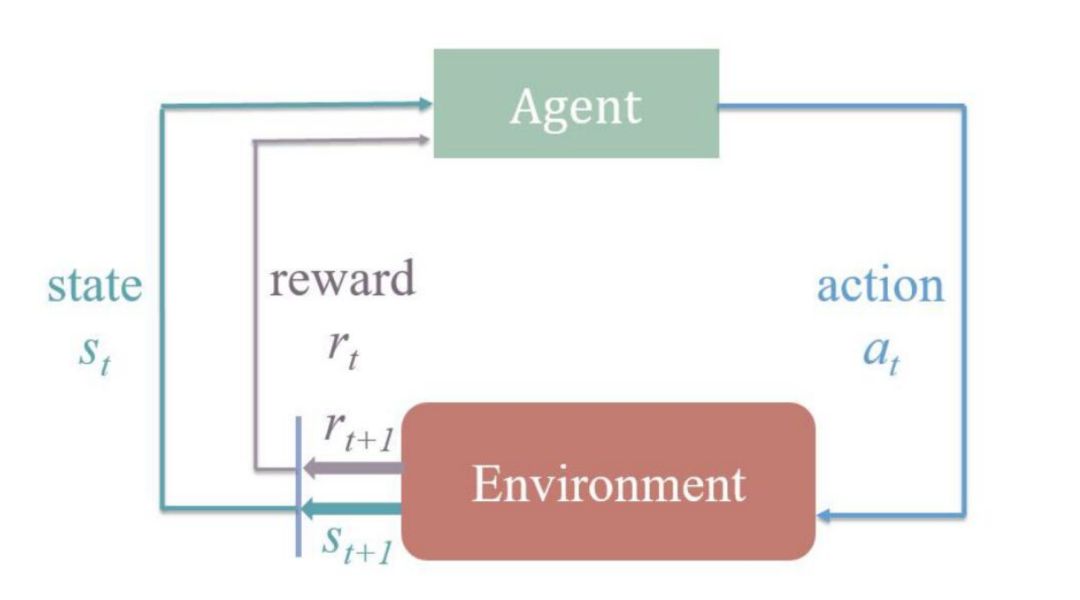
图 1:智能体-环境交互在强化学习中的表示。
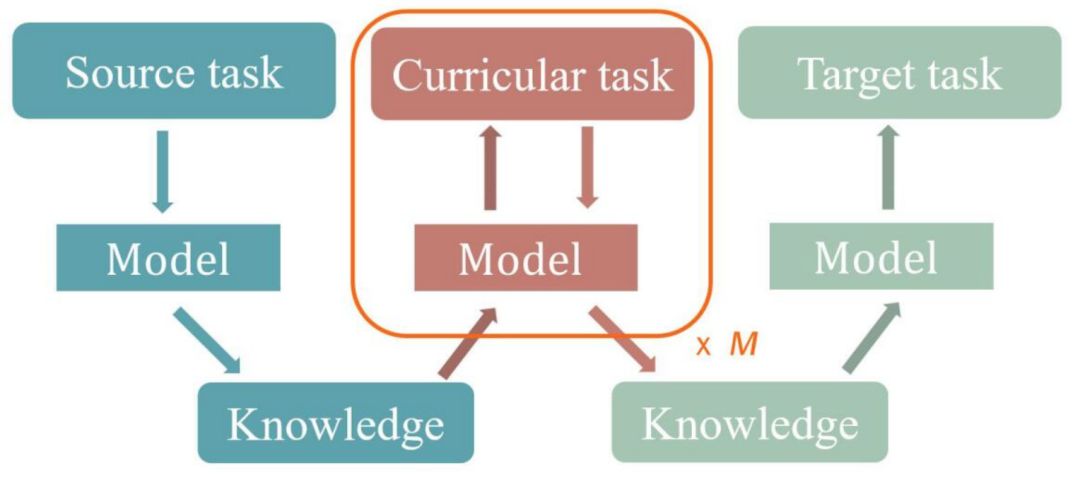
图 2:课程迁移学习图示。存储通过解决源任务而获得的知识,逐渐应用到 M Curricular 任务上以更新知识。最终,知识被应用于目标任务。
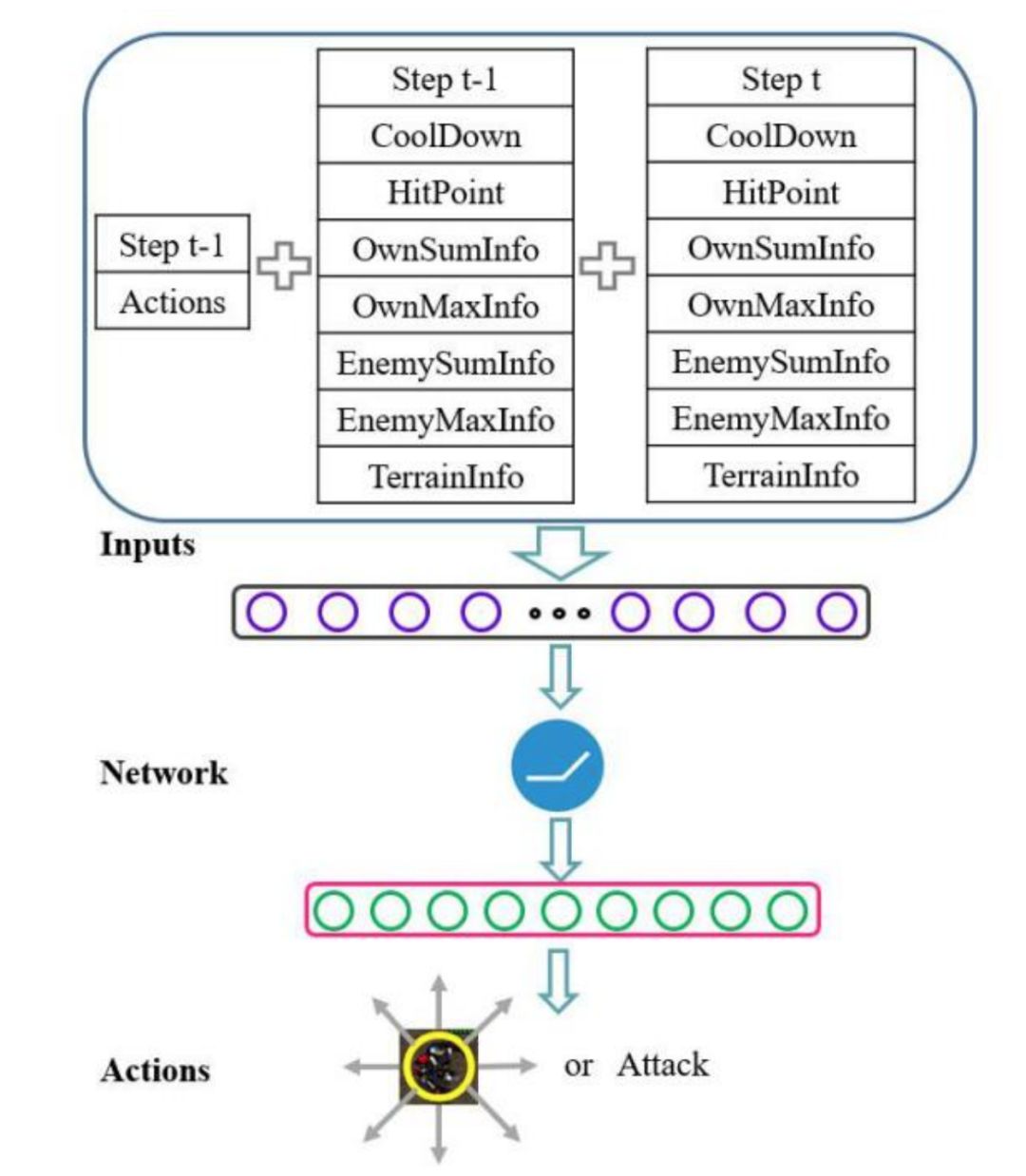
图 3:一个单位在星际争霸微操场景中的学习模型表示。状态表示含三个部分,神经网络被用作函数逼近器。网络输出移动的 8 个方向和攻击动作的概率。
在这一研究中,星际争霸微操被定义为多智能体强化学习模型。我们提出了参数共享多智能体梯度下降 Sarsa(λ)(PSMAGDS)方法来训练模型,并设计了一个奖励机制作为促进学习过程的内在动机。整个 PS-MAGDS 强化学习范式如图 4 所示:
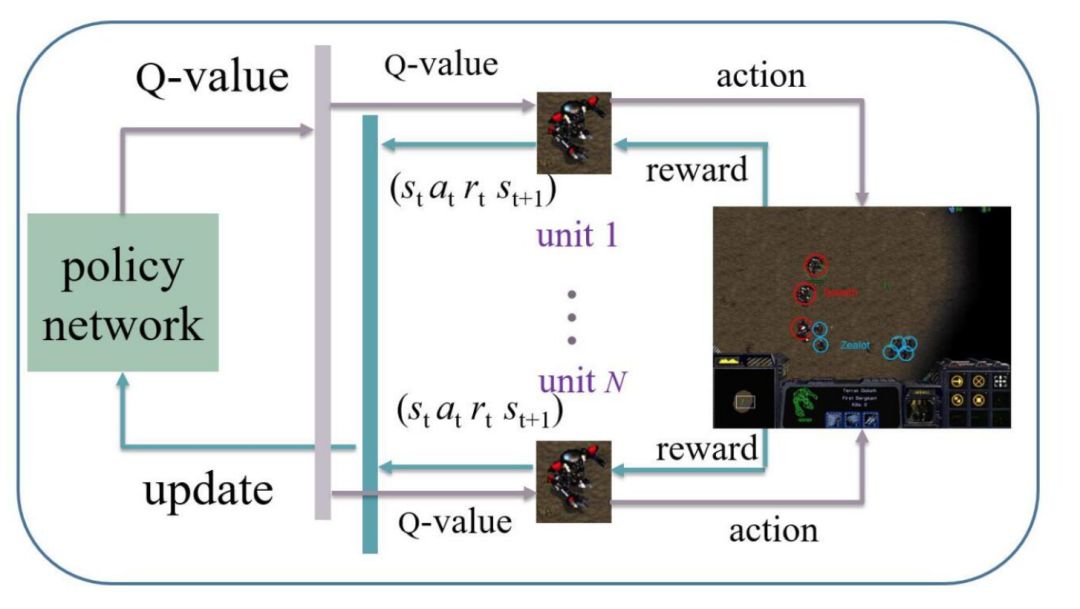
图 4:StarCraft 微操场景中的 PS-MAGDS 强化学习图示。
微操场景中不同单元的属性对比
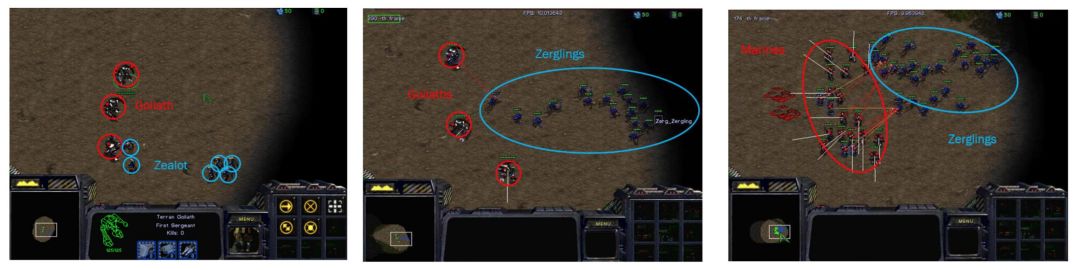
图 5:实验中 StarCraft 微操场景中的表征。左:人族巨人 vs. 狂热者;中:人族巨人 vs. 狗;右:机枪兵 vs. 狗。
结果
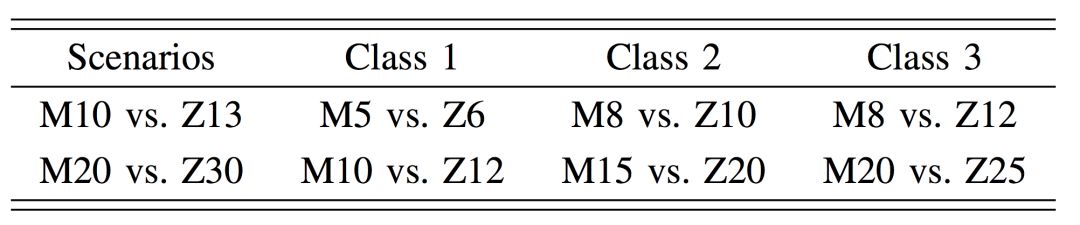
机枪兵 VS. 狗的微操的课程设计。M:机枪兵,Z:狗。
两个大场景中使用基线方法的模型的性能对比。M:机枪兵,Z:狗。
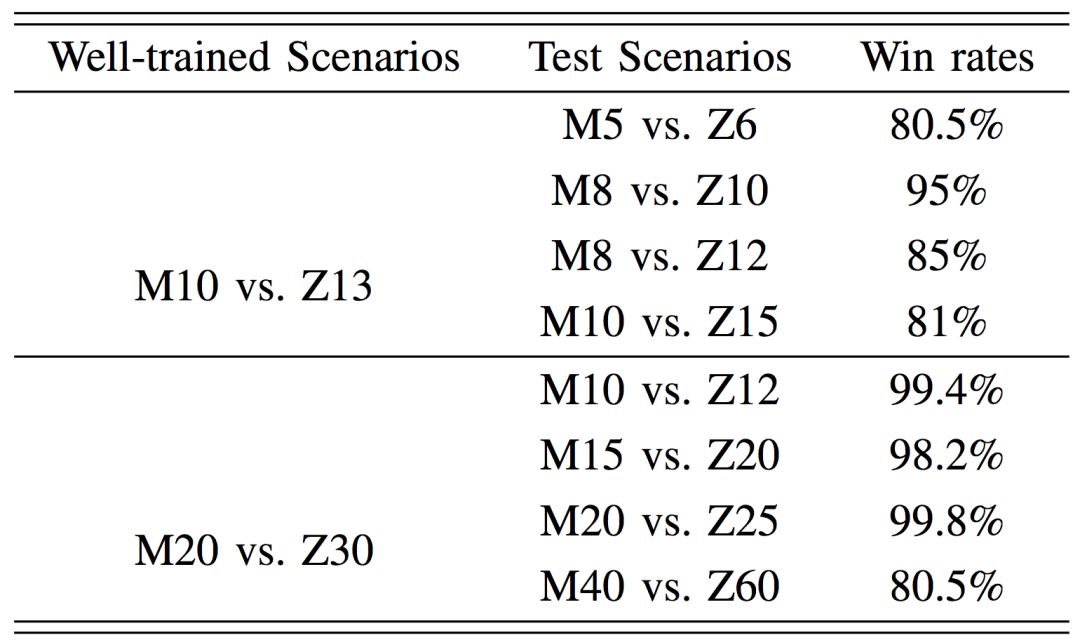
不同课程场景和未知场景中的胜率。M:机枪兵,Z:狗。

图 12:3 个人族巨人 vs. 6 个狂热者的微操场景中的样本游戏回放。

图 13:3 个人族巨人 vs. 20 只狗的微操场景中的样本游戏回放。

图 14:20 个机枪兵 vs. 30 只狗的微操场景中的样本游戏回放。
论文: StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning

论文链接: https://arxiv.org/abs/1804.00810
摘要:近年来,即时战略游戏已成为游戏 AI 的一个重要领域。本论文展示了一种强化学习和课程迁移学习方法,可在星际争霸微操中控制多个单元。我们定义了一种高效的状态表征,破解了游戏环境中由大型状态空间引起的复杂性,接着提出一个参数共享多智能体梯度下降 Sarsa(λ)(PS-MAGDS) 算法训练单元。学习策略在我们的单元中共享以鼓励协作行为。我们使用一个神经网络作为函数近似器,以评估动作价值函数,并提出一个奖励函数帮助单元平衡其移动和攻击。此外,我们还用迁移学习方法把模型扩展到更加困难的场景,加速训练进程并提升学习性能。在小场景中,我们的单元成功学习战斗并击败了胜率为 100% 的内置 AI。在大场景中,课程迁移学习用于渐进地训练一组单位,并展示在目标场景中一些基线方法上的出众性能。通过强化学习和课程迁移学习,我们的单元能够在星际争霸微操场景中学习合适的策略。


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






