


业界 | Facebook发布Tensor Comprehensions:自动编译高性能机器学习核心的C++库
2018年02月15日 12:13:47
来源:机器之心

原标题:业界 | Facebook发布Tensor Comprehensions:自动编译高性能机器
原标题:业界 | Facebook发布Tensor Comprehensions:自动编译高性能机器学习核心的C++库
选自facebook research
机器之心编译
机器之心编辑部
今天,Facebook 人工智能实验室宣布发布 Tensor Comprehensions,这是一个 C++库和数学语言,它能帮助缩小使用数学运算的研究人员和专注在各种硬件后端运行大规模模型的工程师之间的距离。Tensor Comprehensions 的主要区别特征是它使用一种独特的准时化(Just-In-Time)编译来自动、按需生成高性能的代码,这正是机器学习社区所需要的。
生产力的数量级增长
创造全新高性能机器学习模型的典型工作流需要花费数天或者数周来完成两个流程:
在 NumPy 层级的使用上,研究人员编写一个全新层,并在 PyTorch 这样的深度学习库中链接已有运算,然后在小规模实验上进行测试。代码实现的表现需要通过数量级的加速来运行大规模试验;
然后工程师使用该层,并为 GPU 和 CPU 编写有效的代码:
工程师需要成为高性能计算的专家,现在这方面的人才极为有限;
工程师需要明了这个环境,筹划出相关策略,编写代码以及做 debug;
将代码移到与实际任务相关的后端(例如检查冗长的评论),并添加样板融合代码。
结果导致,过去几年深度学习社区一直依赖 CuBLAS、MKL、CuDNN 这样的高性能库来获得在 GPU 和 CPU 上的高性能代码。想要实验不依赖于这些库的新思路需要一定量级的工程量,这对研究人员来说可能是惊人的。
开源一种能将这一流程从数天或者数周缩减到数分钟的工具包,我们觉得有非常大的实用价值。有了 Tensor Comprehensions,我们想象的是研究人员能够以数学符号的方式编写自己的想法,这种符号能被我们的系统自动编译并调整,且结果是有很好表现的专业代码。
在此发布中,我们能提供:
一种以简单语法形式表达大量机器学习 idea 的数学符号;
一个基于 Halide IR 的 C++前端,面向此数学符号;
一个基于 Integer Set Library(ISL)的多面准时化(polyhedral Just-in-Time /JIT)编译器;
一个基于进化搜索的多线程、多 GPU 的自动调节器。
早期研究
近期,高性能图像处理领域中一种语言逐渐开始流行,即 Halide。Halide 使用类似的高级函数式语法描述图像处理流程,接着在独立的代码块中,将其明确调度到硬件上,详细说明操作是如何被平铺、矢量化、并行化和融合的。对于具有架构技能的人来说,Halide 是一个非常有生产力的语言,但是却难以为绝大多数机器学习从业者所用。Halide 的自动调度是一个活跃的研究领域,但对于 GPU 上运行的 ML 代码还没有很好的解决方案。
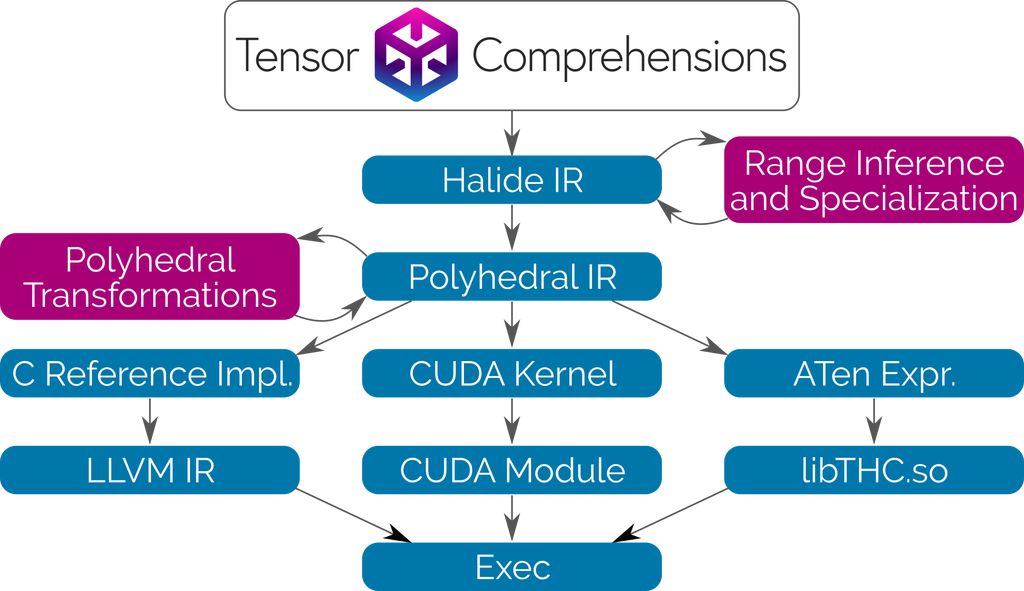
Tensor Comprehension 将 Halide 编译器作为所要调用的库。我们构建了 Halide 的中间表征(intermediate representation/IR)和分析工具,并将其与多面编译(polyhedral compilation)技术配对,因此你可以使用相似的高阶句法编写层,而无需搞懂其运行原理。我们也发现了使语言更加简洁的方法,而无需为缩减运算指定循环边界。
细节

Tensor Comprehensions 使用 Halide 和多面编译(Polyhedral Compilation)技术通过委托内存管理与协调自动合成 CUDA 内核。该编译可对一般的运算符混合、快速局部内存、快速缩减和 JIT 专业化进行优化。由于我们并不尝试获取所有权或优化内存管理,因此我们的工作流可以简单而高效地集成到任何能调用 C++函数的 ML 框架和语言中。
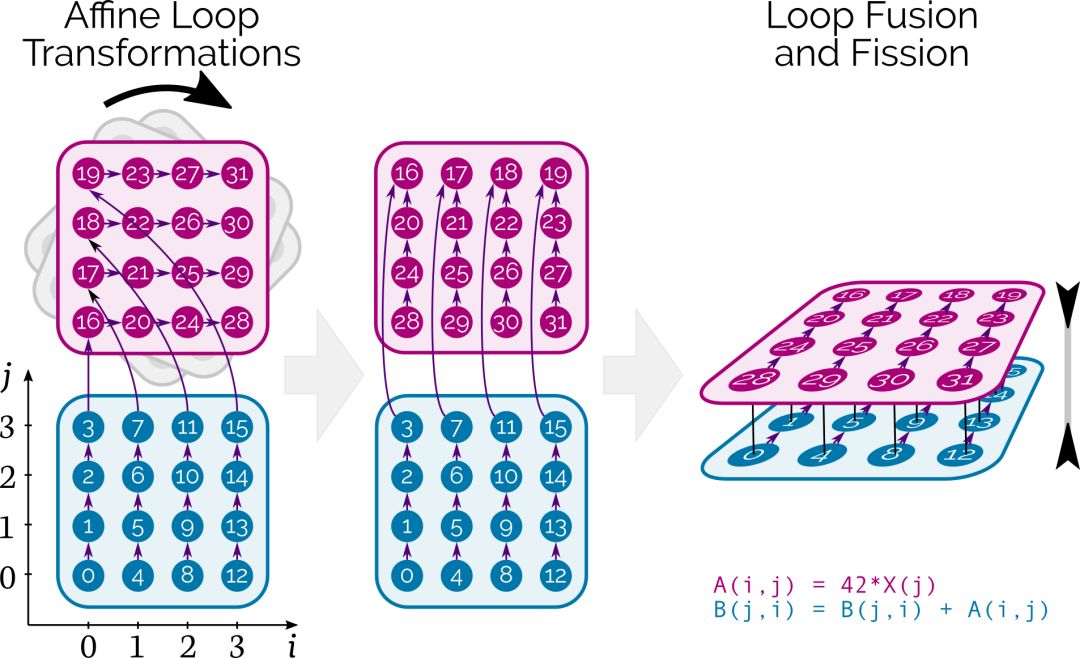
与经典编译器技术和函数库所采用的方法相反,多面编译允许 Tensor Comprehensions 为每个网络按需调度单个张量元素的计算。在 CUDA 层级,它结合了仿射循环转换、fusion/fission 和自动并行化,且能同时确保数据正确地流经内存层级。
图中的数字表示最初计算张量元素的顺序,箭头表示它们之间的依赖关系。在该案例中,图像的旋转对应着允许深层运算符混合的循环交换。
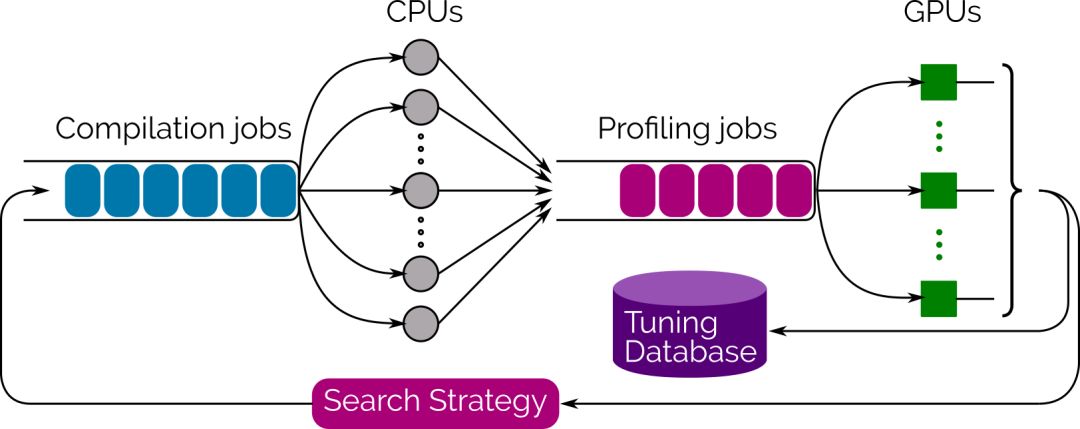
为了推动搜索过程,我们同样提供了一个集成的多线程、多 GPU 自动调优的库,它使用进化搜索来生成和评估数千种实现方案,并选择性能最好的方案。只要在 Tensor Comprehension 上调用 tune 函数,就能实时地查看性能提升,并在满意的时候终止进程。最好的策略是通过 protobuf 执行序列化,并立即或离线的情况下复用。
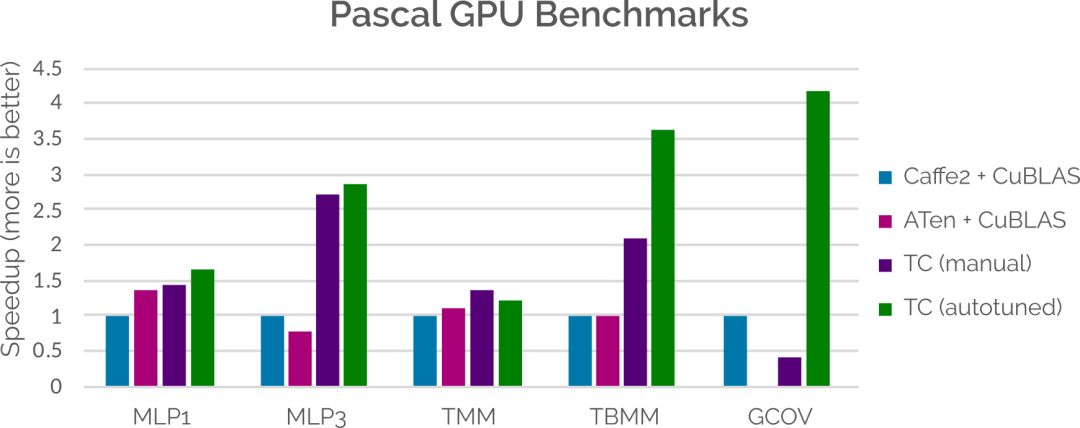
在性能方面,虽然我们在工作上还有很多地方需要提升,但 Tensor Comprehensions 已经能相匹配或胜过当前 ML 框架与手动调参库所集成的性能。这主要通过将代码生成策略适应于特定问题而解决。下面的条形图说明了将 Tensor Comprehensions 自动生成的内核与 Caffe2 和 ATen 等相对比时得到的性能提升。更多性能提升的细节,请查看以下 Tensor Comprehensions 的研究论文。
随着我们扩大对更多硬件终端的贡献,Tensor Comprehension 将补足由英伟达和英特尔编写的快速库,并将与 CUDNN、MKL 或 NNPack 等库联合使用。
下一步计划
该工具的出现让研究者与程序员们可以使用符号编写层,这种方式与论文中使用的,用以描述程序的简洁数学表达方式相同。这意味着人们可以快速方便地将这种表达转化为实现,此前需要数天的任务目前仅需数分钟的时间。
FAIR 将在未来放出 Tensor Comprehensions 的 PyTorch 集成版本。
FAIR 致力于向科学领域作出贡献,并一直积极与机器学习社区合作。Tensor Comprehensions 已经在 Facebook、India、ETH Zurich 和 MIT 开始了应用。目前,这项工作还处于开发的初始阶段,FAIR 将在未来对其进行进一步改进。
论文:Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions

论文地址:https://arxiv.org/abs/1802.04730
摘要:卷积和循环模型的深度学习网络已经相当普及,可以分析大量的音频、图像、文本和图表数据,并应用于自动翻译、语音到文本转换、场景理解、用户偏好排序、广告定位等。用于构建这些网络的深度学习框架,如 TensorFlow、Chainer、CNTK、Torch/PyTorch、Caffe1/2、MXNet 和 Theano,都在可用性和表达性、研究或产品导向以及硬件支持之间探索不同的权衡。它们在运算符的 DAG 上运行;封装了高性能的库,如 CUDNN(NVIDIA GPU)或 NNPACK(多种 CPU);以及自动化的内存分配、同步化和分布式。当计算无法调用已有的高性能库时,需要使用自定制的运算符,这通常需要很高的工程代价。当研究者发明了新的运算符时,这很常见:而这种运算符会使得运行性能大幅降低,导致其创新意义受限。此外,即使存在这些框架可以使用的运行时调用库,对于用户的特定网络和数据集也无法提供最优的性能,因为它没有优化运算符之间的关系,也不存在对数据的大小和形状进行优化的工具。我们的贡献包括了(1)构建了一种和深度学习的数学过程很接近的语言,即 Tensor Comprehensions,提供了命令式和声明式的语言;(2)构建了一个多面即时(JIT)编译器,以将表征深度学习的有向无环图数学描述转换成一个具备内存管理和同步化功能的 CUDA 核,并且提供了运算符融合和指定特定数据大小等优化功能;(3)构建了一个由模组填充的高速编译缓存。特别是,我们证明了多面框架可以有效地针对 GPU 上的当前最佳深度学习模型构建领域特定的优化器。我们的工作流相比将英伟达库应用在机器学习社区常用的的核,以及应用在 Facebook 的真实产品级模型,要快了 4 倍。它集成了主流的框架 Caffe2(产品导向)、PyTorch(研究导向),以及 ATen 非共时张量库。
原文链接:https://research.fb.com/announcing-tensor-comprehensions/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰网科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






