


专栏 | 后RCNN时代的物体检测及实例分割进展
2018年01月27日 13:31:35
来源:机器之心

原标题:专栏 | 后RCNN时代的物体检测及实例分割进展 机器之心专栏 作者:huichan che
原标题:专栏 | 后RCNN时代的物体检测及实例分割进展
机器之心专栏
作者:huichan chen
物体检测是计算机视觉的重要任务之一,从最开始的 Viola-Jones 2001 的人脸检测开始,到 Ross 的 Deformable Part Model(DPM)2007 通用物体检测,再到现在基于深度学习的 Region Convolution(RCNN)2013 模型,我们见证了物体检测的准确率快速的提升,并且计算机视觉所使用的数学方法也从 Boosting,变成了 SVM,到最近的 Deep Neural Network。基于物体检测,研究者们成功的设计出了实例分割 Mask RCNN。RCNN 是近年来物体检测的基石,有大量的论文和博客在分析和改进 RCNN,本篇文章希望通过介绍除了 RCNN,YOLO,SSD 和 Mask RCNN 之外的 novel idea 来帮助大家开拓眼界,避免思维陷入单一模式。
基础网络的改进方向
说起神经网络,大家就会想起用 ResNet,VGG 或者 Inception 来作为主干。来自韩国 Intel 公司的组发明的 PVANet 和 MSRA 的代季峰组的 Deformable Convolution 成功的跳出了惯性思维,大大提升了检测网络的速度和准确性。
PVANet : Deep but Lightweight Neural Networks for Real-time Object Detection
PVANet 贡献了一个可以适用于 Fully Convolution Network 的网络结构,该网络的浅层使用了 CRelu 可以将 Channel 减半,在深层使用 Inception 加强网络的学习效果。CRelu 和完整网络结构如下:
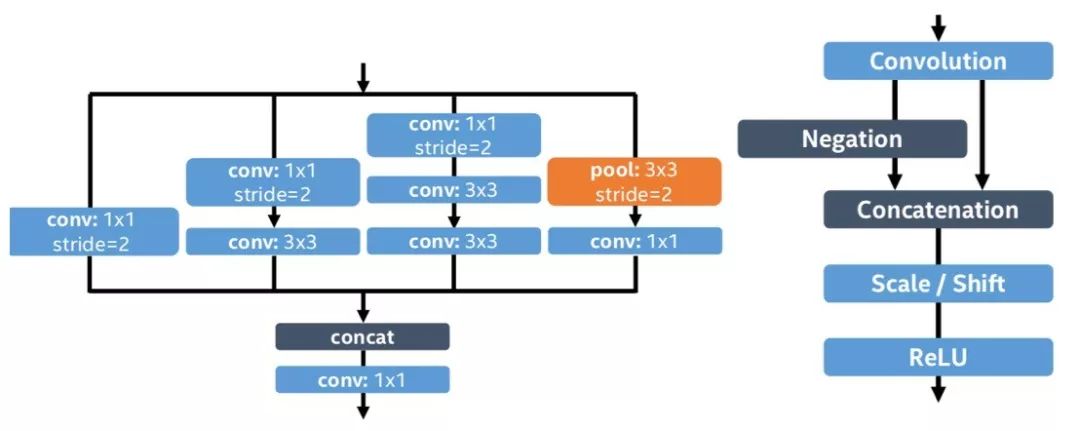
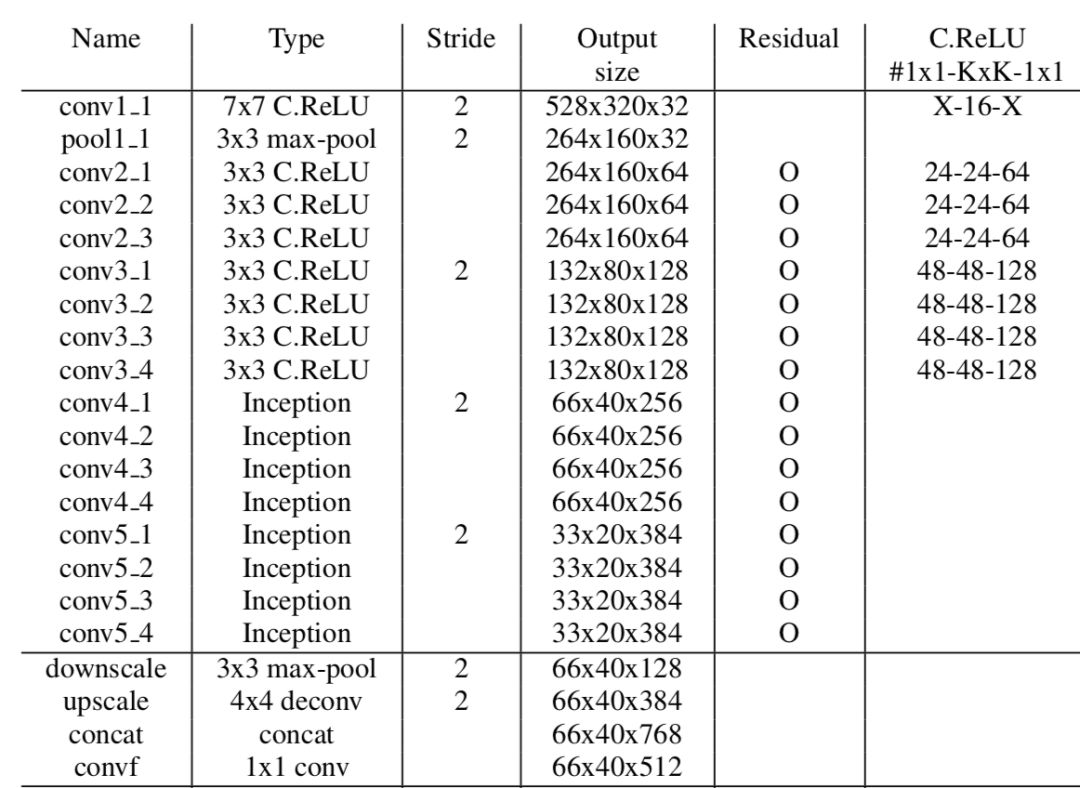
网络参数能够减半的原因是因为,CRelu 发现浅层的网络冗余度高,并且存在反相现象,通过 CRelu 可以重建出另一半的通道。PVANet 跟 Faster RCNN 的速度对比如下表:
Deformable Convolution Networks (ICCV 2017 oral)
本篇文章在 Spatial Transform Network 的基础上提出了 Deformable Convolution Network。个人感觉这篇论文是很有可能的 ICCV Best Paper 的论文之一。这篇论文和 Dilation Network 也有一定的关系。并且这篇论文提供了完整,清晰的代码,为之后的研究提供了很好的平台。
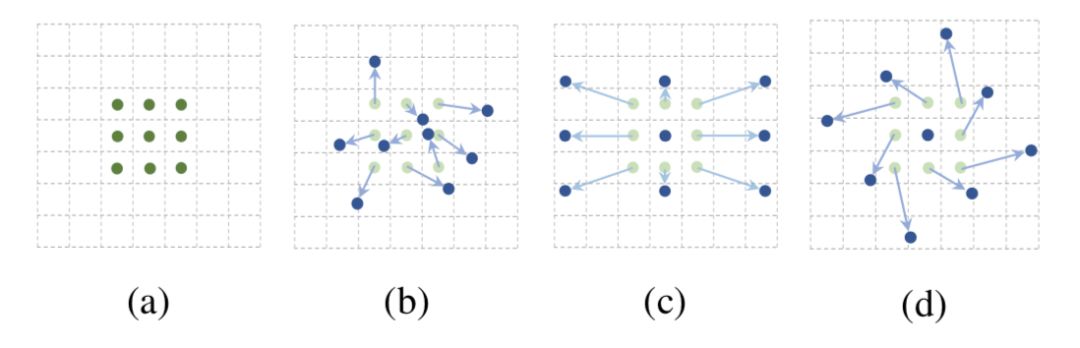
如上图(a)是传统的 CNN,采样是在 3 by 3 的 regular grid 进行采样。(b)为作者提出的 Deformable Convolution,可以看出采样点在 regular grid 的基础上面加上了 offset,能够让神经网络自己决定采样点的位置。(c)和(d)为一种特殊的采样方法,为 Deformable CNN 在某种位移情况下的表现形式。
网络的训练是基于 spatial transformer Network,通过 Bilinear interpolation 的方式进行学习,Backpropagation 也是可以微分的。Deformable CNN 的结构如下图:
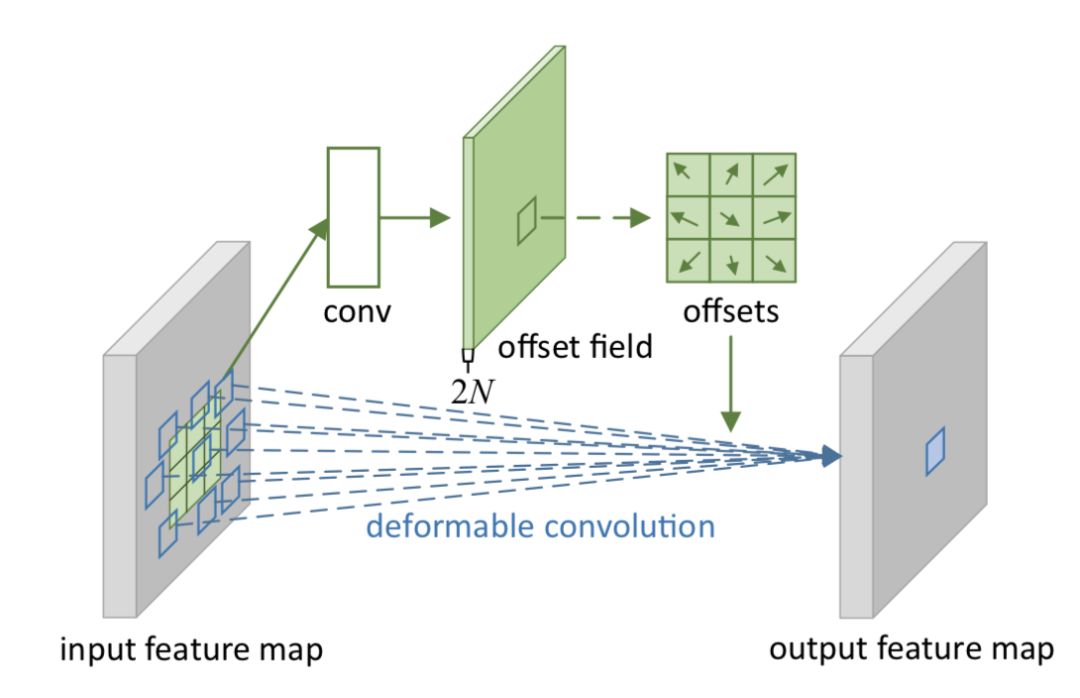
作者在 Semantic segmentation 和物体检测任务上面测试了方法,without bells and whistles,作者可以达到 state-of-the-art 的结果(仅仅物体检测)。如果我们将采样点显示出来就会发现奇妙的现象。采样点会有选择性的位移到 foreground。

Deformable Part-based Model Fully Convolutional Networks for Object Detection (BMVC 2017 oral)
这篇论文和 Deformable CNN 是同期的论文,两者的出发点基本一样。但是训练的过程中,作者使用的 DPM 论文中的公式对物体的位移进行了限制,论文的流程图如下:

物体检测框架的改进
由于 NMS(Non Maximum Suppression)的存在,使得 RCNN 框架的物体检测不是完全的 end-to-end 模型,代季峰组的 Relation Network module 能够代替 NMS,实现 100% 的 end-to-end 模型。
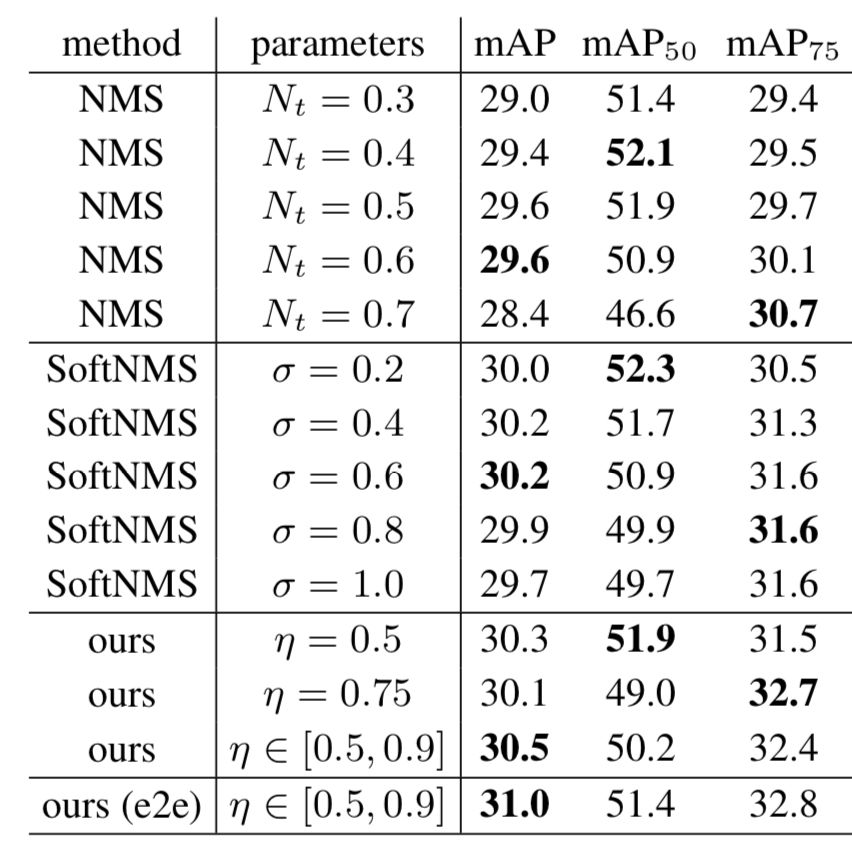
Soft-NMS, improving object detection with One Line of Code (ICCV 2017)
NMS 能除去重叠的 bounding box,是物体检测系统中不可或缺的部分。但是作者发现 NMS 也会滤掉靠的很近的物体。比如下图两匹靠得近的马左边的马由于跟右边的马有很大的 overlapping,从而造成误检。为了避免这种现象的产生,soft-NMS 将 overlapping 的 bounding box 的 confidence 降低而非直接变成零。如下图左边的马的 confidence 从 0.80 降低到了 0.4,从而使得改 bounding box 能够被检测到。soft-NMS 能够在所有的公开数据上面得到 1 个点左右的提升,并且结合 deformable CNN 得到了 state-of-the-art 的结果。

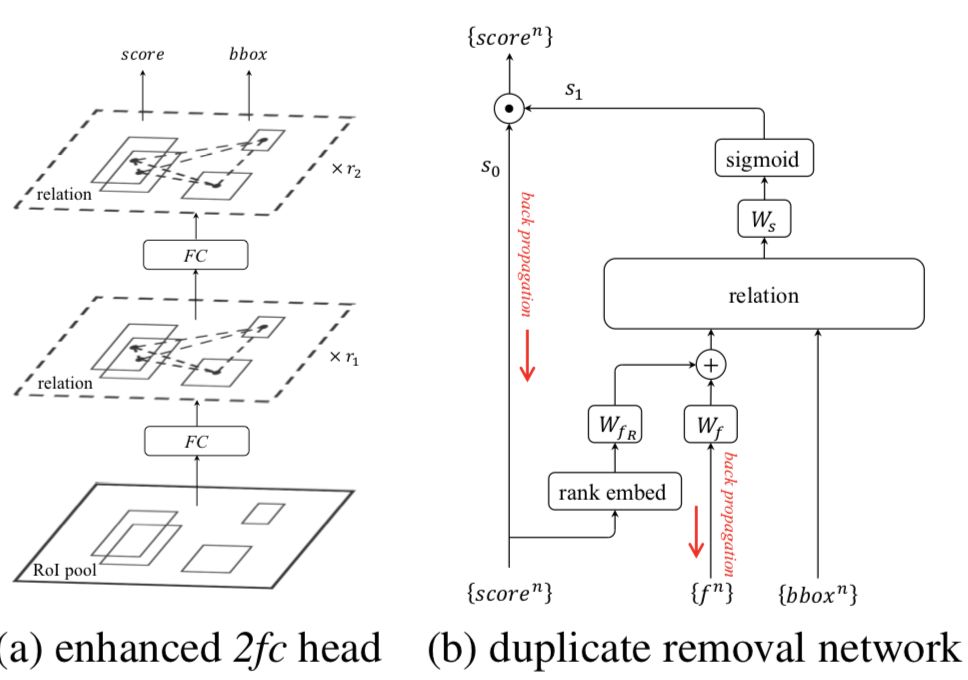
Relation Network for Object Detection (CVPR 2018 submitted)
这篇论文提出了对 relation 进行建模的的 relation module,可以代替 NMS
,实现 100% 的 end-to-end 物体检测。对关系的描述可以提高计算机视觉模型的效果是大家的共识,但是本篇论文是少有的成功运用关系的论文。Relation module 的结果会高于 soft-NMS。在可以预见的将来,relation module 会大量地运用于 CV 模型中。但是美中不足的是,relation network 到底捕捉到了什么样的关系是论文无法说明的。Relation Network 的模型跟最近提出的 non local convolution,attention is all you need 有着惊人的相似。相信如果从这个角度出发,应该会有很大的收获。Relation Module 的结构如下:
Relation Module 跟 NMS 和 Soft-NMS 之间的结果对比。
实例分割的改进
在实例分割方面,除了 Mask RCNN 之外存在着很多新颖的方法,但是由于结果没有 Mask RCNN 好,经常会被人忽律,但是其中的 idea 还是很值得学习借鉴的。
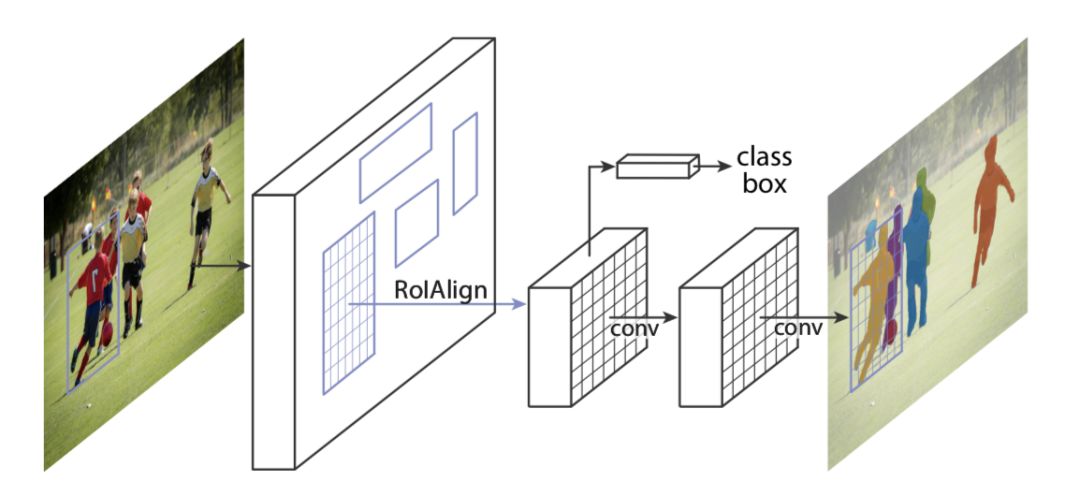
Mask RCNN 已经成为了 instance segmentation 的 baseline 模型,这里就不多做介绍,结构如下:
Deep Watershed Transform for Instance Segmentation (CVPR 2017)
这篇 instance segmentation 的论文在 mask rcnn 之前,这篇论文提出了学习一种类似于 watershed transform 的能量。Watershed transform 可以直接计算,但是由于自然图像的复杂使得结果有很多 local minimal,通过 deep learning 学习到的势能会更加稳定,如下图:

网络通过 GT angle 和 watershed energy 两种 supervision 训练得到。两种能量可以通过 mask 标注产生,Ground-truth 如下图:

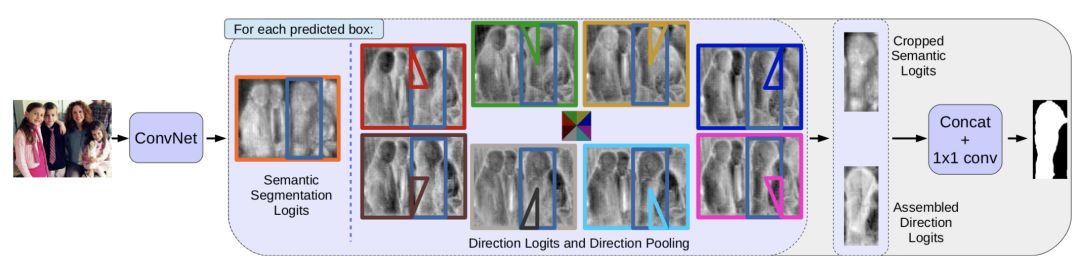
MaskLab : Instance Segmentation by Refining Object Detection with Semantic and Direction Features (CVPR 2018 submitted)
MaskLab 的作者是来自 Google 的团队,第一作者同时也是 deeplab 的作者。应该算是 segmentation 的元老级人物。这篇论文跟 mask rcnn 类似,但是使用了 semantic segmentation 和 Direction prediction 两个分支的信息来生成 mask,结果会比 feature pyramid network 的 mask rcnn 好很多。这篇论文的创新性来自 Direction Pooling,通过每个区域的 direction 的 voting 来得到 region mask,idea 跟 deformable CNN 中的 deformable region pooling 类似。
MaskLab 框架如下:

Directional Pooling 结构如下:
Panoptic Segmentation (CVPR 2018 submitted)
Panoptic Segmentation 中文名为全景分割,是由 Facebook 的大神联手推出的结合 instance segmentation 和 semantic segmentation 的新任务。作者发现,instance segmentation 只能够分别物体,但是没有办法对 stuff 进行预测。而传统的 semantic segmentation 不能够区分物体。作者提出了同时对物体进行分割,并且对 stuff 进行分类的新任务。
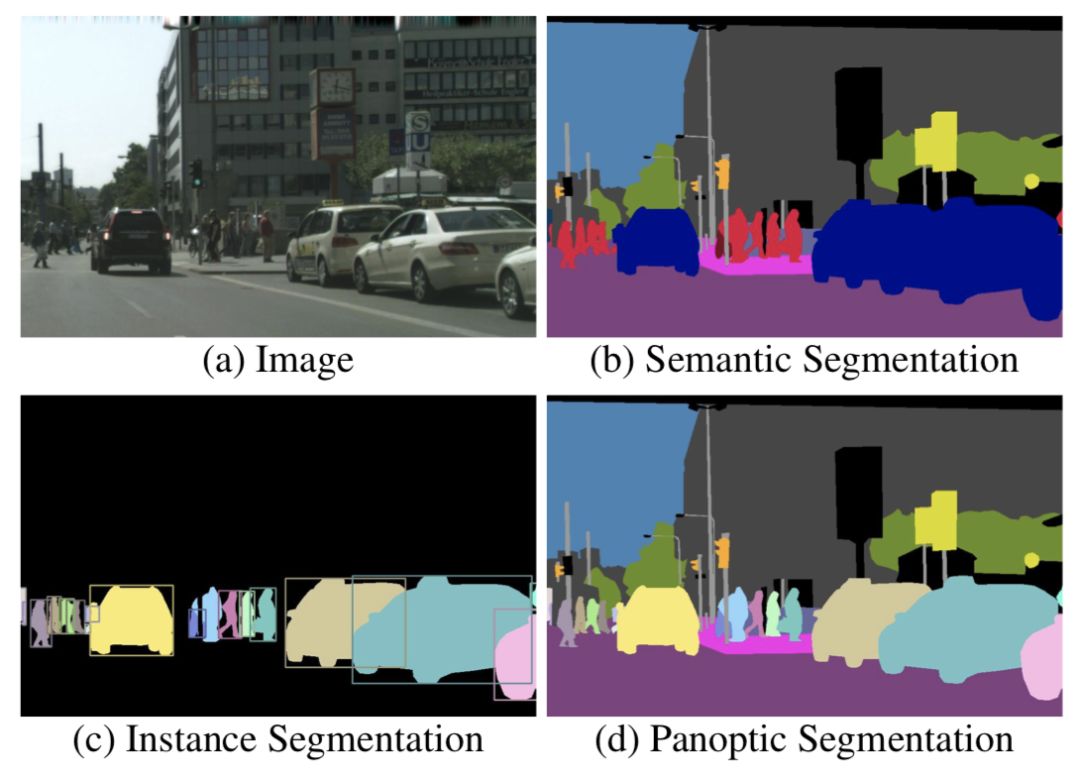
(a)为原图,(b)为 semantic segmentation 图,(c)为 instance segmentation,(d)为新提出的全景分割。与此同时作者提出了全景分割的 evaluation metric 和基于 mask rcnn + PSPNet 的 baseline 模型。新提出的任务应该还是有很大前进空间,相信各路大神应该会很快就攻占这一任务了吧 (>_<)
Instance Segmentation Benchmark
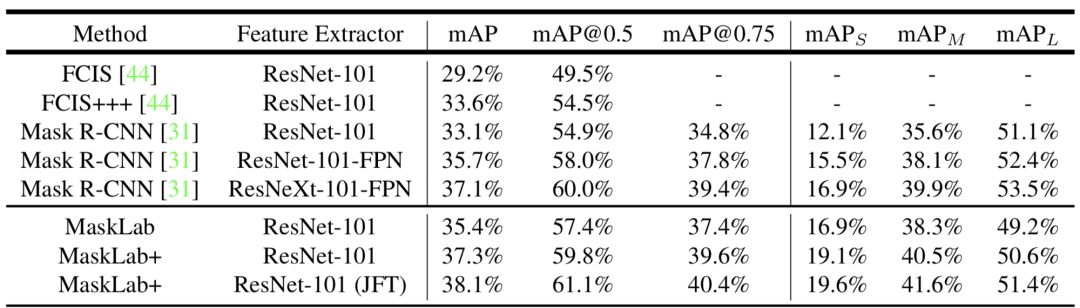
下面我们比较一下不同方法在 cityscape 上面的结果,可以看出 Mask RCNN 结果远超过其他方法,最新提出的 MaskLab 借助大数据的力量微弱超过 mask rcnn。
Cityscape 上面 Watershed,SGN 和 Mask RCNN 的比较

COCO 数据集 Mask RCNN 跟 MaskLab 比较
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






