


学界 | 伯克利吴翼&FAIR田渊栋等人提出强化学习环境Hourse3D
2018年01月20日 12:48:30
来源:机器之心

原标题:学界 | 伯克利吴翼&FAIR田渊栋等人提出强化学习环境Hourse3D 选自arXiv 作
原标题:学界 | 伯克利吴翼&FAIR田渊栋等人提出强化学习环境Hourse3D
选自arXiv
作者:吴翼、吴育昕、Georgia Gkioxari、田渊栋
机器之心编译
参与:路雪、李泽南
构建虚拟 3D 环境对于强化学习研究非常重要。近日,UC Bekerley 博士生吴翼、FAIR 研究工程师吴育昕、博士后 Georgia Gkioxari 和研究科学家田渊栋共同提交了一篇论文,提出一种基于 SUNCG 数据集构建的丰富、可扩展的高效环境 House3D。研究者用连续和离散动作空间训练强化学习智能体,改善了它们在新环境中的泛化能力。该论文目前已提交至 ICLR 2018 大会。
项目链接:https://github.com/facebookresearch/House3D
近期,深度强化学习已在多种游戏上显示了自己的能力,如 Atari 游戏(Mnih et al., 2015)和围棋(Silver et al., 2016),在其中都展示了超越人类的水平。这些巨大成就的根基在于高效明确、可进行自由学习与探索的智能体模拟环境。目前为止,很多研究人员提出的环境已经编码了人类智能的某些方面,其中包括 3D 感知(DeepMind Lab(Beattie et al., 2016)和 Malmo(Johnson et al., 2016))、实时决策(TorchCraft(Synnaeve et al., 2016)和 ELF(Tian et al., 2017))、快速反应(Atari(Bellemare et al., 2013))、长期计划(围棋、国际象棋)、语言和交流(ParlAI(Miller et al., 2017)和(Das et al., 2017b))。
尽管如此,深度强化学习在这些模拟环境中的进展是否能够以及如何迁移到真实世界仍然是一个开放性问题。对于这个方向,最重要的事情就是构建模拟真实世界的环境,该环境需要具备真实世界丰富的结构、内容和动态性。为了加快学习,这些环境应该实时响应,并提供大量多样化的复杂数据。尽管我们很需要这些特性,但它们仍然无法保证达到泛化目标。泛化是智能体在新场景中成功完成任务的能力,这对实际应用非常重要。例如在很多房子里训练的家用机器人或在很多城市中训练的自动驾驶汽车,应该能够轻松部署到与训练场景完全不同的新房子或新城市。
尽管人们往往认为泛化与学习有关,但是毫无疑问泛化与训练智能体的环境的多样性有关。为了促进泛化,环境需要提供大量数据,允许智能体测试其在新条件下识别和动作的能力。要验证智能体是否开发出智能技巧,而不是仅凭记忆(过拟合),具备无偏、无限制本质的新型生成环境是必要的。注意:泛化和大型数据集之间的结合带来了图像识别和目标识别领域的近期进展(Russakovsky et al., 2015; He et al., 2015)。
与泛化被正式定义和充分研究的监督学习相反,强化学习中的泛化可以用多种方式来理解。DeepMind 实验室(Beattie et al., 2016; Higgins et al., 2017)通过像素级颜色或纹理变化和迷宫布局引入环境多样性。Tobin et al. (2017) 通过引入随机噪声改变物体颜色,来探索像素级的泛化。Finn et al. (2017b) 研究在奖励仅提供给任务的部分子集时,智能体在类似任务配置环境中的泛化能力。Pathak et al. (2017) 测试智能体在同样游戏更困难级别的泛化能力。
但是,环境中的像素级变化(如物体的颜色和纹理)或难度级别变化在智能体那里却经常得出非常近似的视觉观察结果。在真实世界中,人类感知和理解复杂的视觉信号。例如,一个人到了朋友家,即使装饰和设计都是新的,他也能轻松识别出哪是厨房。而智能体要想在真实世界中成功,需要理解新的结构布局和多样的物体外表。智能体需要能够将语义与新场景联系起来,在视觉变化场景中实现泛化。这篇论文研究了语义级别的泛化,其中的训练环境和测试环境在视觉上不相同,但共享同样的高级别概念属性。具体来说,研究者提出一个包括数千个室内场景(具备不同的场景类型、布局和物体)的虚拟 3D 环境 House3D,见图 1a。House3D 利用 SUNCG 数据集 (Song et al., 2017),该数据集包含 4.5 万个人类设计的真实世界 3D 房子模型,其中的物体全部标注成不同类别。研究者将 SUNCG 数据集转换至 House3D 环境,这对于不同任务都是有效且可扩展的。在 House3D 中,智能体可自由探索空间,感知大量不同视觉外表的物体。
House3D 展示了智能体确实能够在新基准任务 RoomNav 中学习高级别概念,并泛化至未见的新场景中。在 RoomNav 中,智能体开始位于房子的随机位置,并被要求去往高级语义概念指定的目的地(如厨房)。RoomNav 示例见图 1b。研究者从 House3D 中手动选取了 270 个房子,并将其分割成两个训练集(20 个房子和 200 个房子)和一个用于评估的留出集(50 个房子)。这些房子足够大,且适合导航任务。研究者展示了:使用用标准深度强化学习方法(如 A3C 和 DDPG)训练的 gated-CNN 和 gated-LSTM 策略,大型多样化训练集可以改善智能体在 RoomNav 中的泛化能力。这与小型训练集的结果相反,其中出现了显著的过拟合。此外,深度(depth)信息和语义信号(如分割)带来更好的泛化效果。前者(深度)促进即时动作,后者(分割)帮助在新环境中的语义理解。实验结果证明了为真实世界机器人构建实际视觉系统的意义,同时引出在处理复杂的真实世界任务时,分离视觉和机器人学习等方向。
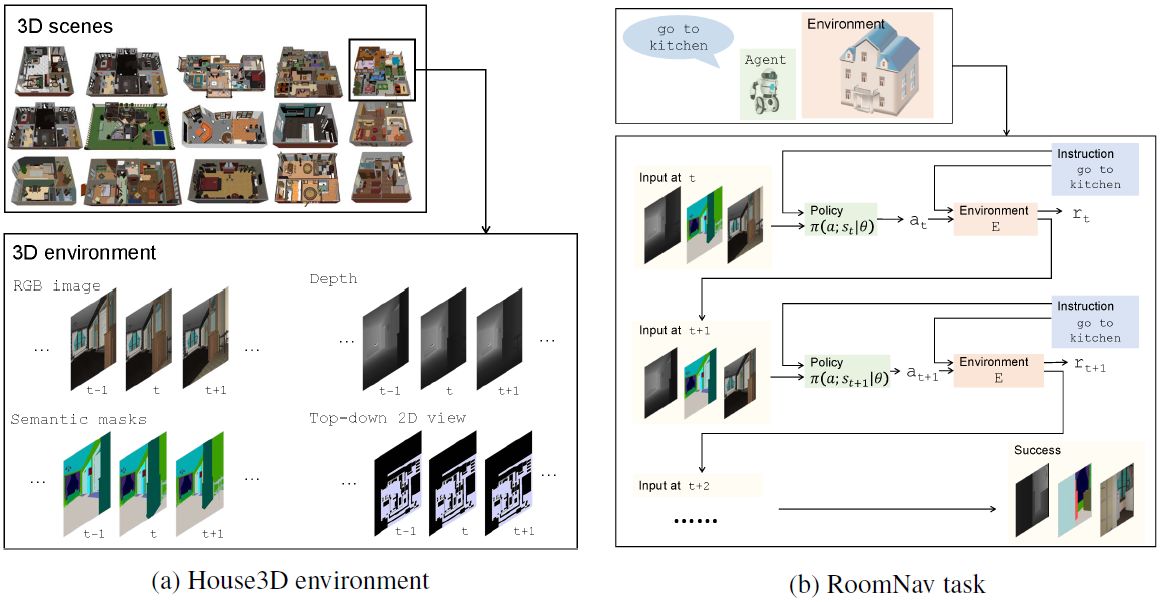
图 1:House3D 环境和 RoomNav 任务概览。
(a)研究者基于 SUNCG 数据集构建了一个高效的交互式环境,该数据集包含 4.5 万个不同的室内场景,从单间到带游泳池和健身房的两层楼房。所有 3D 对象都被完全标注成 80 多个类别。环境中的智能体可获得多种模式的观察结果(如 RGB 图像、深度、分割掩码、自上而下的 2D 视角等。(b)研究者专注于基于语义的导航任务。给定一个高级任务描述,智能体自行探索环境,到达目标房间。
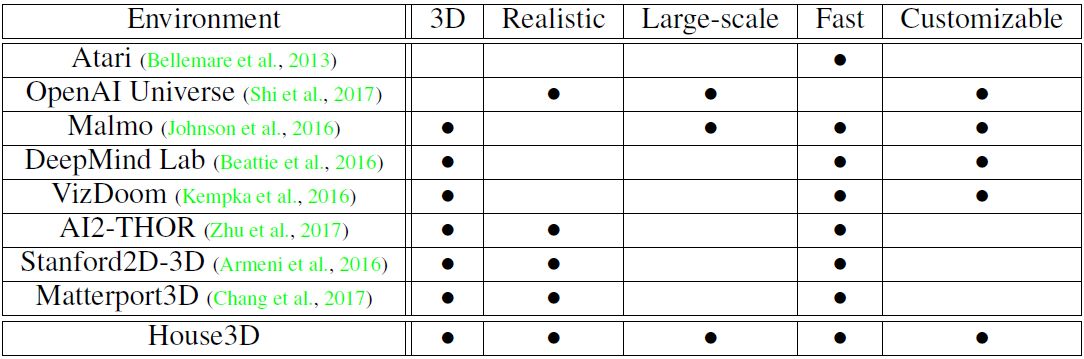
表 1:常用环境总结。属性包括 3D:渲染对象的 3D 本质;真实(Realistic):与现实世界的相似度;大规模(Large-Scale):大型环境集合;Fastspeed:快速渲染;可定制(Customizable):可定制用于其他应用的灵活性。
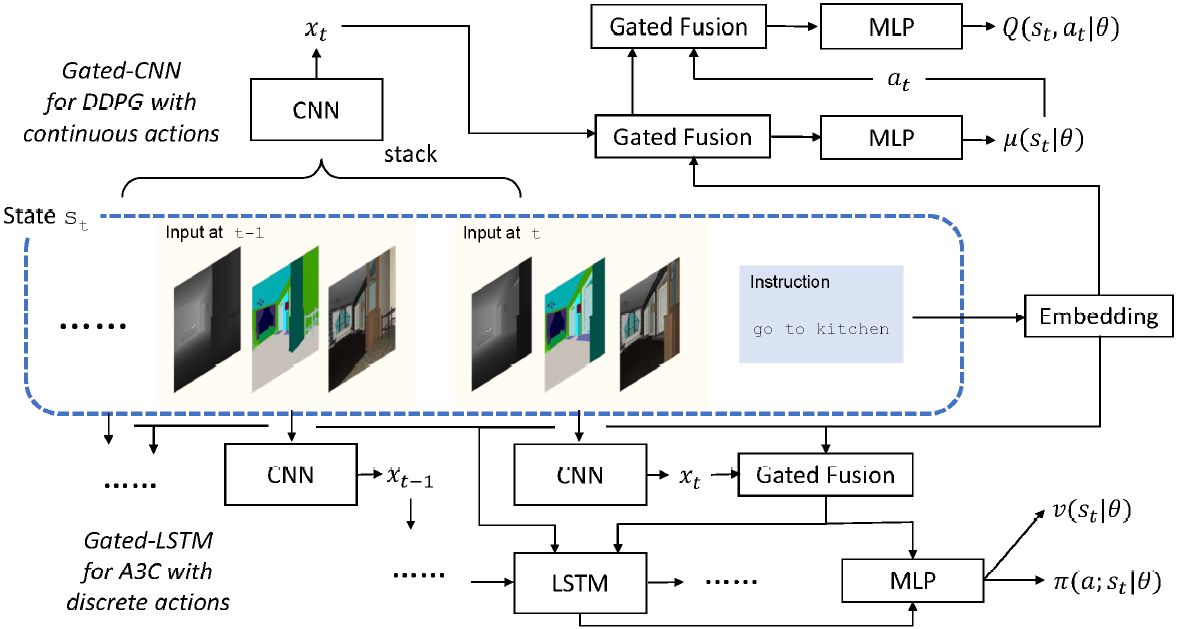
图 2:论文提出模型概览。下方代表用于离散动作的 gated-LSTM 模型,上方代表用于连续动作的 gated-CNN 模型。Gated Fusion 模块指门控注意力(gated-attention)架构。
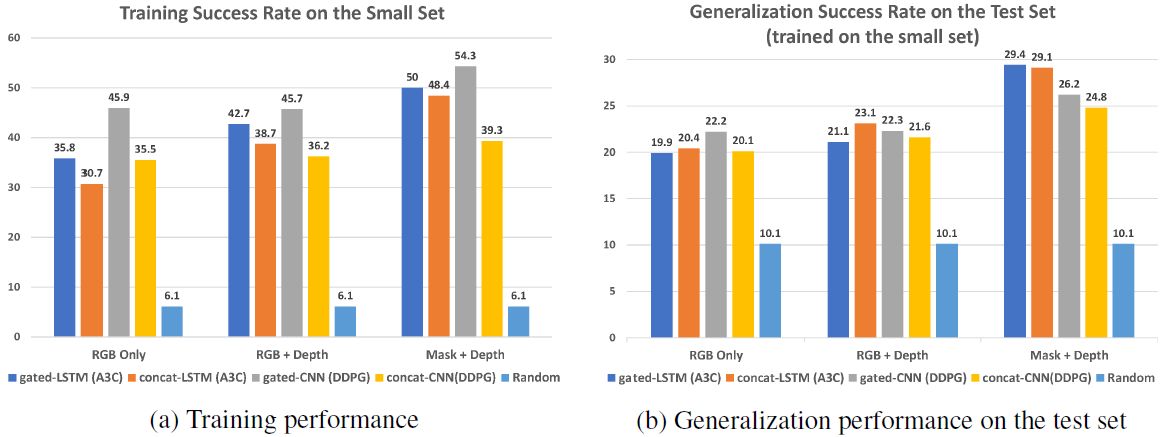
图 3:不同模型在具备不同输入信号(RGB Only、RGB+Depth 和 Mask+Depth)的 Esmall(20 个房屋)上训练时的性能。每一组中,从左到右的条分别对应 gated-LSTM、concat-LSTM、gated-CNN、concat-CNN 和随机策略。
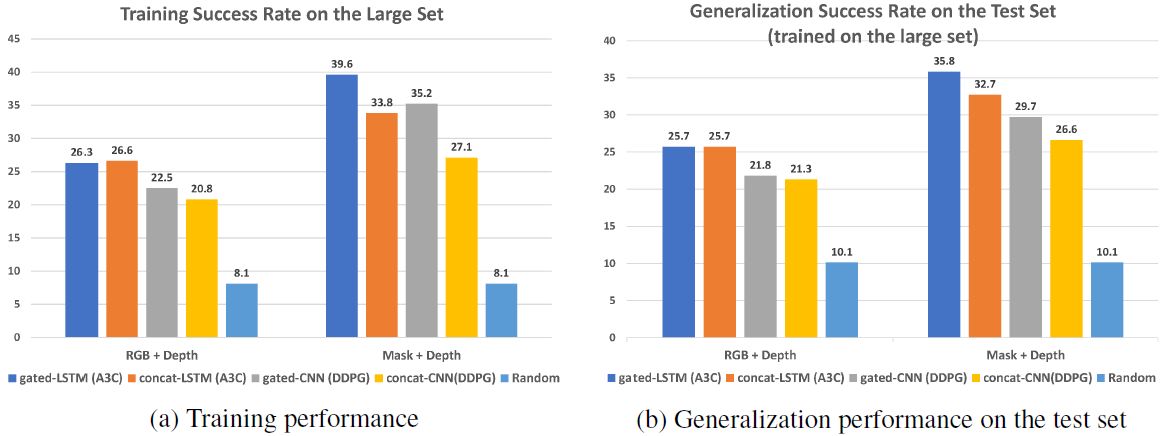
图 4:不同模型在带有 RGB+Depth 和 Mask+Depth 输入信号的 Elarge(200 个房屋)上训练时的性能。每一组中,从左到右的直方条分别对应 gated-LSTM、concat-LSTM、gated-CNN、concat-CNN 和 随机策略。
论文:Building Generalizable Agents with a Realistic and Rich 3D Environment

论文链接:https://arxiv.org/abs/1801.02209
摘要:要缩小机器智能与人类之间的差距,引入视觉真实、内容充实的环境至关重要。在此类环境中,你可以评估和改善实际智能系统的关键特性,即泛化。本研究构建了一种丰富、可扩展的高效环境 House3D,包含 45622 个人工设计的 3D 房屋场景,从单人间到楼房应有尽有;且该环境具备一套完整标注的 3D 物体、材质和场景布置,基于 SUNCG 数据集(Song et al., 2017)。我们重心关注语义级别的泛化,使用 House3D 的子集研究概念驱动的导航任务 RoomNav。在 RoomNav 中,智能体根据语义概念的指定导航至目的地。为了成功,该智能体通过开发感知来理解所处的场景,通过将场景映射到正确的语义来理解概念,通过观察底层物理规则来导航至目的地。我们用连续和离散动作空间训练强化学习智能体,展示了它们在新环境中的泛化能力。具体来说,我们观察到(1)在大型房屋集合上进行训练的难度显著增加,但泛化能力也要好得多;(2)使用语义信号(如分割掩码)提升泛化性能;(3)语义输入信号的门网络(gated network)可以改善训练性能和泛化能力。我们希望 House3D(包括对 RoomNav 任务的分析)能够对设计实际的智能系统有所帮助,也希望社区广泛使用该环境。


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






