


学界 | 谷歌提出机器对话Self-Play框架M2M,提高自动化程度
2018年01月20日 12:10:43
来源:机器之心

原标题:学界 | 谷歌提出机器对话Self-Play框架M2M,提高自动化程度 选自arXiv 机器
原标题:学界 | 谷歌提出机器对话Self-Play框架M2M,提高自动化程度
受最近 AI 游戏研究的启发(self-play),谷歌提出了 M2M 的机器对话框架,其结合了众包模式和聚焦任务特定经验的方法,并通过增加自动化程度,以快速引导智能体进行目标导向的对话,并可生成高质量对话数据集。
1. 介绍
使用监督学习方法训练的目标导向的智能体,通常在使用相同任务的对话训练的时候才能得到最佳表现。然而,当开发对话智能体帮助用户完成新任务的时候,例如通过在线网站进行医生预约,可能不存在该任务的人类-智能体对话数据集,因为目前还没有和该特定 API 进行交互对话的智能体。一个常用的方法是通过众包模式使用 Wizard-of-Oz 设置(Wen et al. (2016); Asri et al. (2017))以收集和标注自由格式的对话。然而这种处理方式很昂贵,并存在损耗,因为从众包人员收集的自由格式的对话:(i)可能没有覆盖智能体需要处理的所有交互;(ii)可能包含不适合用作训练数据的对话(例如众包人员使用的对话可能过分简化或复杂);(iii)可能在对话行为标注中存在错误,需要对话开发者进行昂贵的手动修改。
另一种方法在面向消费者的语音助理中应用很广泛,它允许第三方开发者建立聚焦于单独任务(例如,DialogFlow1 、Alexa Skills2 、wit.ai3)的对话「经验」或「技能」。这为对话开发者提供了对特定任务处理的完全控制,使其能递增地添加新的特征到经验中。然而,这种方法非常依赖于开发者设计对话式交互的所有层面,以及预期用户和智能体交互以完成任务的所有方式。将这种方法扩展以使其更加数据驱动化是很有价值的,提高其在对话研究社区中的流行度(相比 Wizard-of-Oz 方法)。
作者在本文中提出了 Machines Talking To Machines(M2M,机器对话机器)的框架,这是一个功能导向的流程,用于训练对话智能体。其主要目标是通过自动化任务无关的步骤以减少建立对话数据集所需的代价,从而对话开发者只需要提供对话的任务特定的层面。另一个目标是获得更高质量的对话,「高质量」指的是:(i)语言和对话流的多样性,(ii)所有预期用户行为的覆盖范围;以及(iii)监督标签的准确性。最后,这个框架的目标是引导对话智能体,使其被部署去服务实际的用户,并达到可接受的任务完成率,之后,该框架应该能使用强化学习通过用户反馈直接提升自身性能。
之前建立语义解析器(Wang et al. (2015))、把自然语言问题映射到结构化问题 (Zhong et al. (2017)) 解析器的方法,都依赖众包形式把自动生成的结构化表征映射到 single-shot 自然语言表述中。然而,以这种方式生成多轮对话需要多个参与智能体的协作。受最近 AI 游戏研究的启发 (Silver et al. (2016, 2017)),我们引入了「dialogue selfplay,自对话」的概念,也就是两个或者多个对话智能体通过选择离散对话行为进行交互,以尽可能地生成对话历史。在此研究中,作者部署了一个基于日程的用户模拟器智能体 (Schatzmann et al. (2007)) 和一个基于有限状态机器的系统智能体,来进行自对话步骤。

图 1:我们提出的 M2M 框架:(1)对话开发者提供一个任务纲要和一个 API 客户端。(2)自动化机器人生成对话大纲;(3)众包人员改写对话并验证 slot span;(4) 使用监督学习在数据集上训练一个对话模型。整个流程可在 8 小时内完成。

图 2:生成大纲与段落的示例。
表 1:用 M2M 收集的对话。

表 2:DSTC2 与 M2M Restaurant 数据集在语言与对话流多样性的对比。
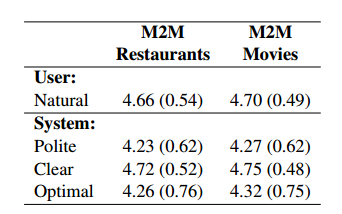
表 3:用 M2M 收集的对话的人类评价。众包人员对用户与系统对话给出得分的平均值(1-5 分), 括号内是标准偏差。



- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






